PAVE: Patching and Adapting Video Large Language Models
作者: Zhuoming Liu, Yiquan Li, Khoi Duc Nguyen, Yiwu Zhong, Yin Li
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-03-25
备注: CVPR2025 Camera Ready
🔗 代码/项目: GITHUB
💡 一句话要点
PAVE:通过轻量级适配器增强视频大语言模型的多模态理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 多模态学习 适配器 边信道信息 视听问答
📋 核心要点
- 现有Video LLM难以有效利用音频、3D等边信道信息,限制了其在复杂场景下的应用。
- PAVE通过引入轻量级适配器“patches”,在不修改原模型结构和权重的前提下,实现对多模态信息的有效融合。
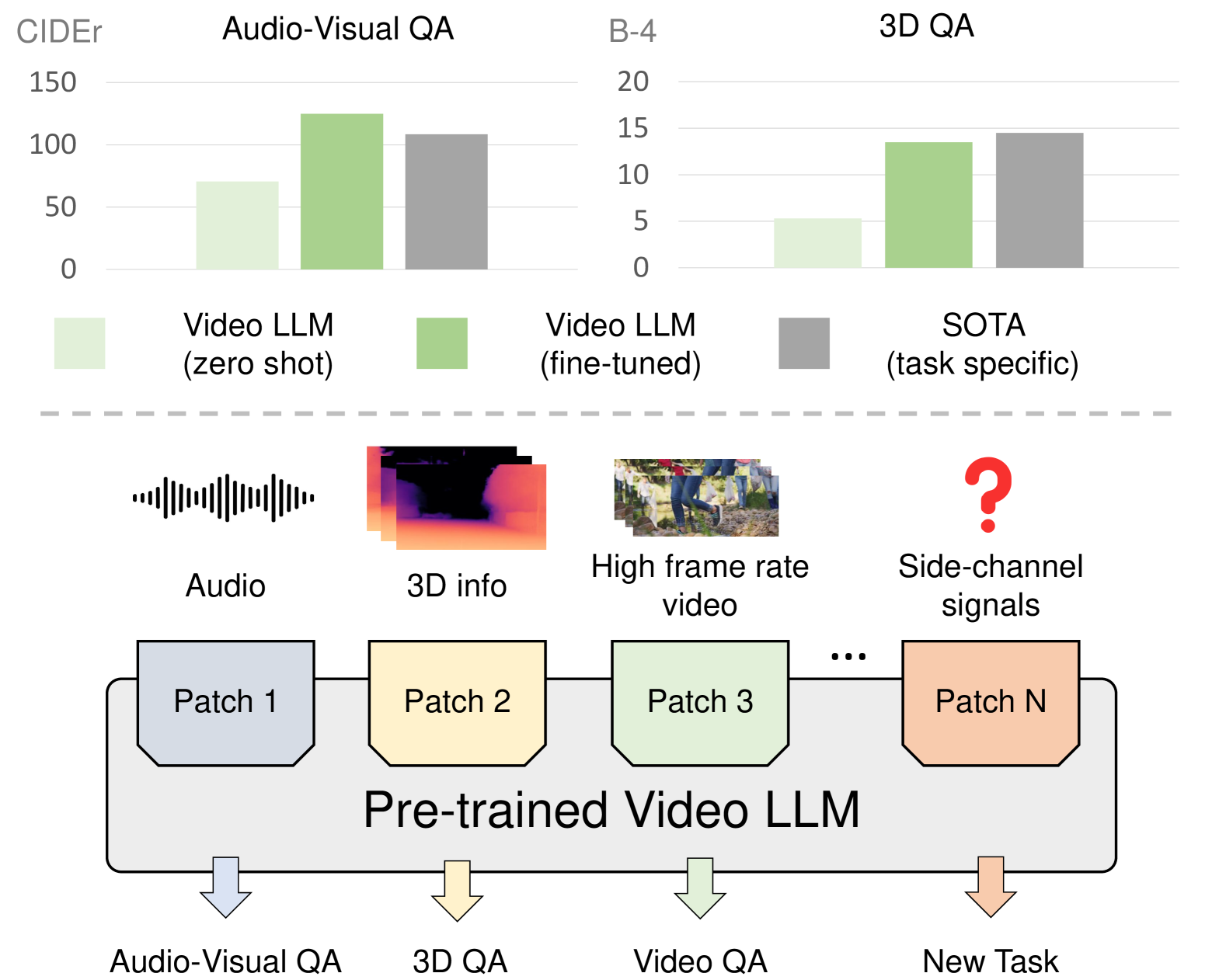
- 实验表明,PAVE在视听问答、3D推理等任务上显著提升了性能,且计算开销极小,并具备良好的泛化能力。
📝 摘要(中文)
预训练的视频大语言模型(Video LLMs)展现了卓越的推理能力,然而,将这些模型适配到涉及额外模态或数据类型(例如,音频或3D信息)的新任务仍然具有挑战性。本文提出了PAVE,一个灵活的框架,用于将预训练的Video LLMs适配到具有边信道信号的下游任务,例如音频、3D线索或多视角视频。PAVE引入了轻量级适配器,称为“patches”,它向基础模型添加少量参数和操作,而不修改其架构或预训练权重。通过这样做,PAVE可以有效地适配预训练的基础模型,以支持各种下游任务,包括视听问答、3D推理、多视角视频识别和高帧率视频理解。在这些任务中,PAVE显著提高了基础模型的性能,超越了最先进的特定任务模型,同时仅产生约0.1%的额外FLOPs和参数的微小成本。此外,PAVE支持多任务学习,并且在不同的Video LLMs之间具有良好的泛化能力。代码已开源。
🔬 方法详解
问题定义:现有预训练的视频大语言模型(Video LLMs)虽然在视频理解方面表现出色,但当需要处理包含音频、3D信息或多视角视频等额外模态或数据类型的任务时,其性能会受到限制。现有的方法通常需要对整个模型进行微调或重新训练,这不仅计算成本高昂,而且容易导致过拟合,并且可能破坏预训练模型原有的知识。
核心思路:PAVE的核心思路是引入轻量级的适配器模块(称为“patches”),这些模块被添加到预训练的Video LLM中,用于处理额外的模态或数据类型。这些适配器模块只包含少量的参数和操作,因此可以以较低的计算成本将模型适配到新的任务。同时,由于适配器模块不修改预训练模型的原始权重,因此可以保留预训练模型的知识,并避免过拟合。
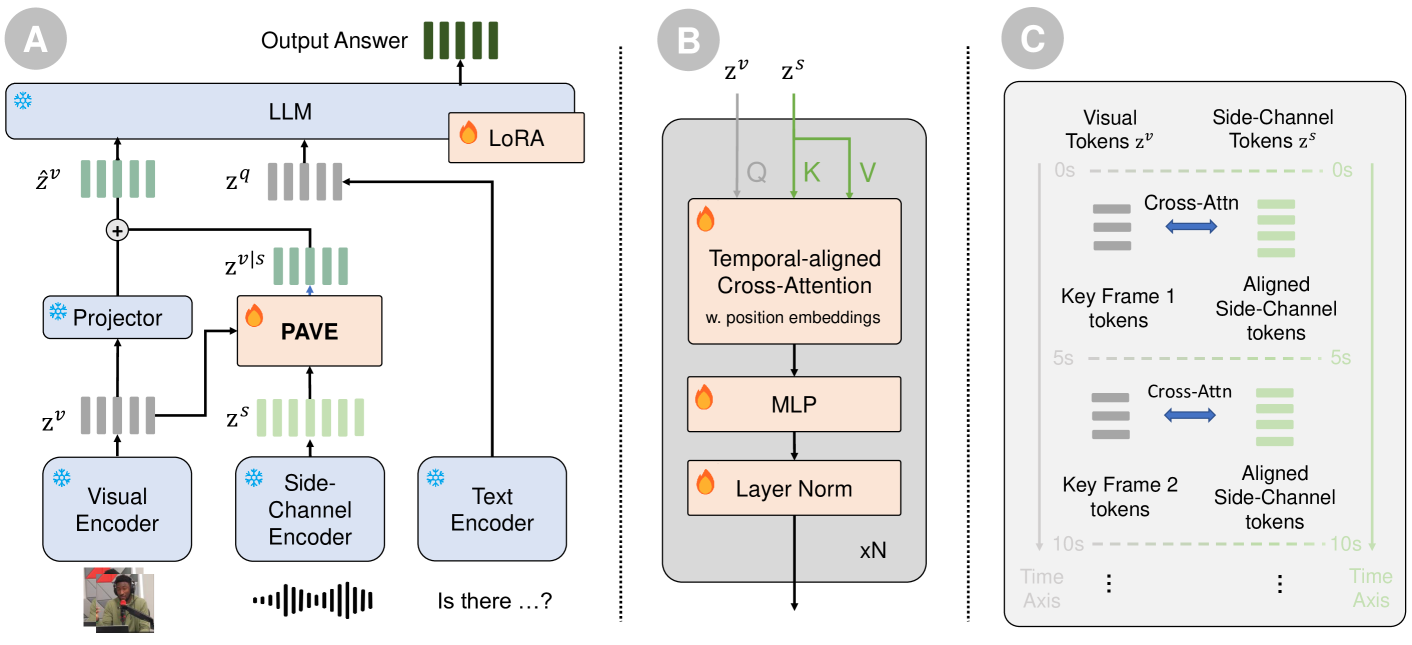
技术框架:PAVE框架主要包含以下几个模块:1) 边信道信号编码器:用于提取音频、3D信息或多视角视频等边信道信号的特征。2) 轻量级适配器(patches):将边信道信号的特征与视频特征进行融合。这些适配器被插入到Video LLM的各个层中,以实现多模态信息的有效融合。3) 预训练的Video LLM:作为基础模型,负责视频理解和推理。整个框架采用端到端的方式进行训练。
关键创新:PAVE的关键创新在于引入了轻量级的适配器模块(patches),这些模块可以在不修改预训练模型结构和权重的前提下,实现对多模态信息的有效融合。这种方法不仅计算成本低廉,而且可以保留预训练模型的知识,并避免过拟合。此外,PAVE框架具有良好的泛化能力,可以应用于不同的Video LLMs和不同的下游任务。
关键设计:PAVE的关键设计包括:1) 适配器模块的结构:适配器模块采用简单的线性层或MLP结构,以减少计算开销。2) 适配器模块的插入位置:适配器模块被插入到Video LLM的各个层中,以实现多模态信息的有效融合。3) 损失函数:采用交叉熵损失函数或对比学习损失函数,以优化适配器模块的参数。
🖼️ 关键图片

📊 实验亮点
PAVE在多个下游任务上取得了显著的性能提升。例如,在视听问答任务上,PAVE超越了最先进的特定任务模型。在3D推理任务上,PAVE也取得了显著的性能提升。此外,PAVE的计算开销极小,仅增加了约0.1%的FLOPs和参数。实验结果表明,PAVE是一种高效且有效的多模态视频理解方法。
🎯 应用场景
PAVE框架具有广泛的应用前景,例如在智能监控中,可以利用音频信息来识别异常事件;在自动驾驶中,可以利用3D信息来增强环境感知能力;在视频会议中,可以利用多视角视频来提供更沉浸式的体验。此外,PAVE还可以应用于视频内容分析、视频推荐等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Pre-trained video large language models (Video LLMs) exhibit remarkable reasoning capabilities, yet adapting these models to new tasks involving additional modalities or data types (e.g., audio or 3D information) remains challenging. In this paper, we present PAVE, a flexible framework for adapting pre-trained Video LLMs to downstream tasks with side-channel signals, such as audio, 3D cues, or multi-view videos. PAVE introduces lightweight adapters, referred to as "patches," which add a small number of parameters and operations to a base model without modifying its architecture or pre-trained weights. In doing so, PAVE can effectively adapt the pre-trained base model to support diverse downstream tasks, including audio-visual question answering, 3D reasoning, multi-view video recognition, and high frame rate video understanding. Across these tasks, PAVE significantly enhances the performance of the base model, surpassing state-of-the-art task-specific models while incurring a minor cost of ~0.1% additional FLOPs and parameters. Further, PAVE supports multi-task learning and generalizes well across different Video LLMs. Our code is available at https://github.com/dragonlzm/PAVE.