OpenLex3D: A Tiered Evaluation Benchmark for Open-Vocabulary 3D Scene Representations
作者: Christina Kassab, Sacha Morin, Martin Büchner, Matías Mattamala, Kumaraditya Gupta, Abhinav Valada, Liam Paull, Maurice Fallon
分类: cs.CV, cs.RO
发布日期: 2025-03-25 (更新: 2025-10-14)
备注: NeurIPS 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
OpenLex3D:用于开放词汇3D场景表示的分层评估基准
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景理解 开放词汇 语义分割 对象检索 基准测试
📋 核心要点
- 现有3D场景理解方法受限于封闭集语义,无法充分利用自然语言的丰富性。
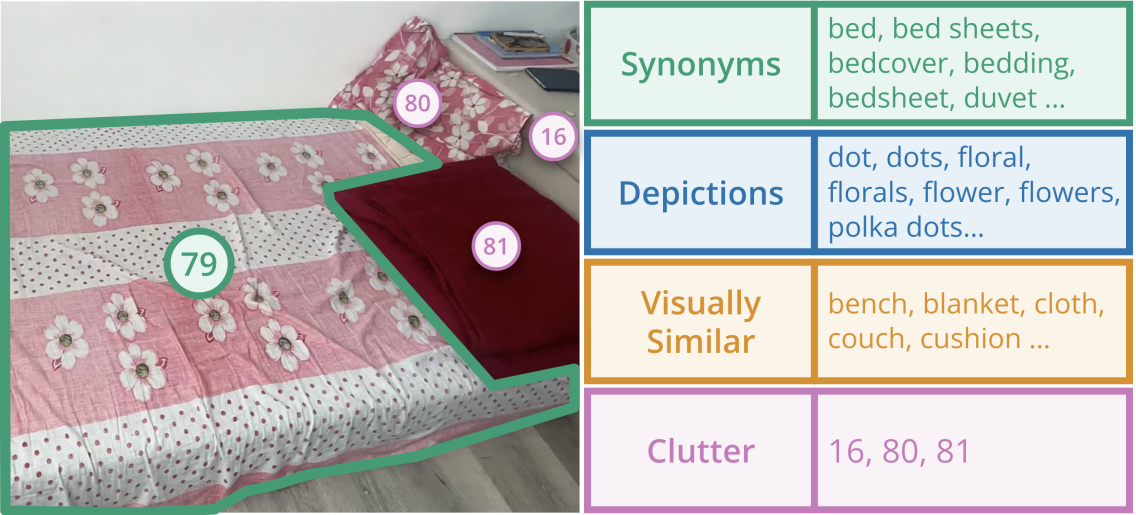
- OpenLex3D通过提供更丰富的标签注释,包括同义词和细粒度描述,来捕捉真实世界的语言变异性。
- 通过开放集3D语义分割和对象检索任务,OpenLex3D评估了现有方法的性能,并指出了改进方向。
📝 摘要(中文)
本文提出了OpenLex3D,一个专门用于评估3D开放词汇场景表示的基准。现有的3D场景理解方法受到封闭集语义数据集的限制,无法捕捉语言的丰富性。OpenLex3D为Replica、ScanNet++和HM3D场景提供了全新的标签注释,通过引入同义对象类别和更细致的描述,捕捉了真实世界中的语言变异性。我们的标签集比原始数据集每个场景多13倍的标签。通过引入开放集3D语义分割任务和对象检索任务,我们在OpenLex3D上评估了各种现有的3D开放词汇方法,展示了失败案例和改进方向。我们的实验提供了关于特征精度、分割和下游能力的见解。该基准可在https://openlex3d.github.io/公开获取。
🔬 方法详解
问题定义:现有3D场景理解方法依赖于封闭集语义的数据集进行训练和评估,这些数据集无法捕捉自然语言的多样性和复杂性。这限制了模型在真实世界场景中的泛化能力,尤其是在处理开放词汇和细粒度语义时。现有方法难以处理同义词和上下文相关的对象描述,导致性能下降。
核心思路:OpenLex3D的核心思路是创建一个包含更丰富、更细致的标签注释的3D场景数据集,从而更真实地反映自然语言的复杂性。通过引入同义词和细粒度描述,OpenLex3D旨在挑战现有模型,并推动开放词汇3D场景理解领域的发展。该基准测试鼓励开发能够理解和处理更广泛语言表达的模型。
技术框架:OpenLex3D基于现有的Replica、ScanNet++和HM3D数据集,并在此基础上进行了扩展和重新标注。主要包含以下几个部分:1) 数据集选择:选择具有代表性的3D场景数据集。2) 标签注释:为每个场景添加新的标签注释,包括同义对象类别和细粒度描述。3) 任务定义:定义开放集3D语义分割和对象检索任务。4) 评估指标:设计合适的评估指标来衡量模型在这些任务上的性能。
关键创新:OpenLex3D的关键创新在于其标签注释的丰富性和细粒度。与现有数据集相比,OpenLex3D提供了更多的标签,包括同义词和细粒度描述,从而更真实地反映了自然语言的复杂性。这种更丰富的标签集使得模型能够学习到更鲁棒和泛化的3D场景表示。
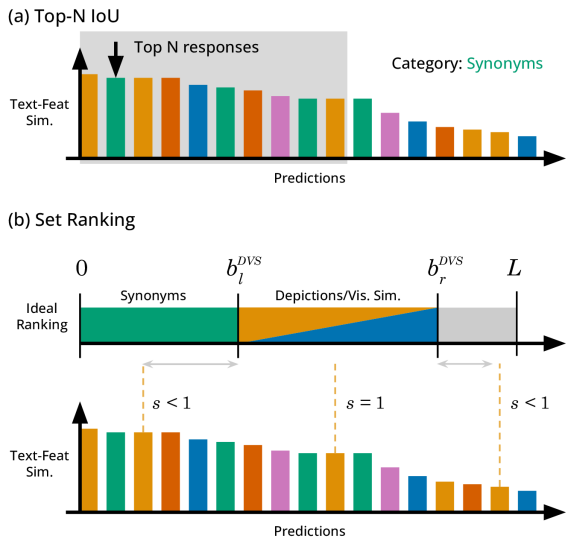
关键设计:OpenLex3D的关键设计包括:1) 标签注释策略:采用人工标注和自动标注相结合的方法,确保标签的准确性和完整性。2) 任务设计:开放集3D语义分割任务要求模型能够识别未在训练集中出现的对象类别。对象检索任务要求模型能够根据自然语言描述检索到相应的3D对象。3) 评估指标:采用精确率、召回率和F1分数等指标来评估模型在这些任务上的性能。
🖼️ 关键图片

📊 实验亮点
OpenLex3D的实验结果表明,现有3D开放词汇方法在处理同义词和细粒度描述时存在不足。例如,在开放集3D语义分割任务中,现有方法的性能显著低于封闭集语义分割任务。OpenLex3D的标签集比原始数据集每个场景多13倍的标签,为模型提供了更丰富的训练数据,从而有望提升模型的性能。
🎯 应用场景
OpenLex3D可应用于机器人导航、虚拟现实、增强现实、智能家居等领域。通过提升3D场景理解能力,机器人可以更好地与环境交互,虚拟现实和增强现实应用可以提供更逼真的体验,智能家居系统可以更智能地理解用户的需求。该基准测试将推动相关技术的发展,并促进这些应用场景的落地。
📄 摘要(原文)
3D scene understanding has been transformed by open-vocabulary language models that enable interaction via natural language. However, at present the evaluation of these representations is limited to datasets with closed-set semantics that do not capture the richness of language. This work presents OpenLex3D, a dedicated benchmark for evaluating 3D open-vocabulary scene representations. OpenLex3D provides entirely new label annotations for scenes from Replica, ScanNet++, and HM3D, which capture real-world linguistic variability by introducing synonymical object categories and additional nuanced descriptions. Our label sets provide 13 times more labels per scene than the original datasets. By introducing an open-set 3D semantic segmentation task and an object retrieval task, we evaluate various existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and avenues for improvement. Our experiments provide insights on feature precision, segmentation, and downstream capabilities. The benchmark is publicly available at: https://openlex3d.github.io/.