Any6D: Model-free 6D Pose Estimation of Novel Objects
作者: Taeyeop Lee, Bowen Wen, Minjun Kang, Gyuree Kang, In So Kweon, Kuk-Jin Yoon
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-03-24 (更新: 2025-03-25)
备注: CVPR 2025, Project Page: https://taeyeop.com/any6d
💡 一句话要点
Any6D:提出一种无需3D模型的新物体6D姿态估计框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6D姿态估计 未知物体 模型无关 RGB-D图像 渲染-比较
📋 核心要点
- 现有6D姿态估计方法依赖于物体的3D模型或多视角信息,限制了其在新物体和复杂场景中的应用。
- Any6D通过联合优化2D-3D对齐和尺度估计,并结合渲染-比较策略,实现了对未知物体的精确6D姿态估计。
- 在多个数据集上的实验结果表明,Any6D在未知物体姿态估计任务上显著超越了现有技术水平,展现了良好的泛化能力。
📝 摘要(中文)
本文提出Any6D,一个无需模型即可进行6D物体姿态估计的框架。该框架仅需单张RGB-D锚点图像,即可估计新场景中未知物体的6D姿态和尺寸。与依赖纹理3D模型或多视角的现有方法不同,Any6D利用联合物体对齐过程来增强2D-3D对齐和度量尺度估计,从而提高姿态精度。该方法集成了渲染-比较策略,生成并优化姿态假设,使其在遮挡、非重叠视角、多样光照条件和大型跨环境变化等场景中表现出鲁棒性。在REAL275、Toyota-Light、HO3D、YCBINEOAT和LM-O五个具有挑战性的数据集上的评估表明,该方法在未知物体姿态估计方面显著优于当前最优方法。
🔬 方法详解
问题定义:现有6D姿态估计方法主要依赖于已知物体的3D模型或多视角图像,这限制了它们在处理新物体或缺乏足够视角信息的场景时的性能。这些方法难以适应真实世界中物体种类繁多和环境复杂多变的挑战。因此,如何实现对未知物体的鲁棒且精确的6D姿态估计是一个关键问题。
核心思路:Any6D的核心思路是利用单张RGB-D图像作为锚点,通过联合优化2D-3D对齐和度量尺度估计,实现对未知物体的6D姿态估计。该方法避免了对物体3D模型的依赖,并通过渲染-比较策略来生成和优化姿态假设,从而提高鲁棒性。这种设计使得Any6D能够适应遮挡、非重叠视角和光照变化等复杂场景。
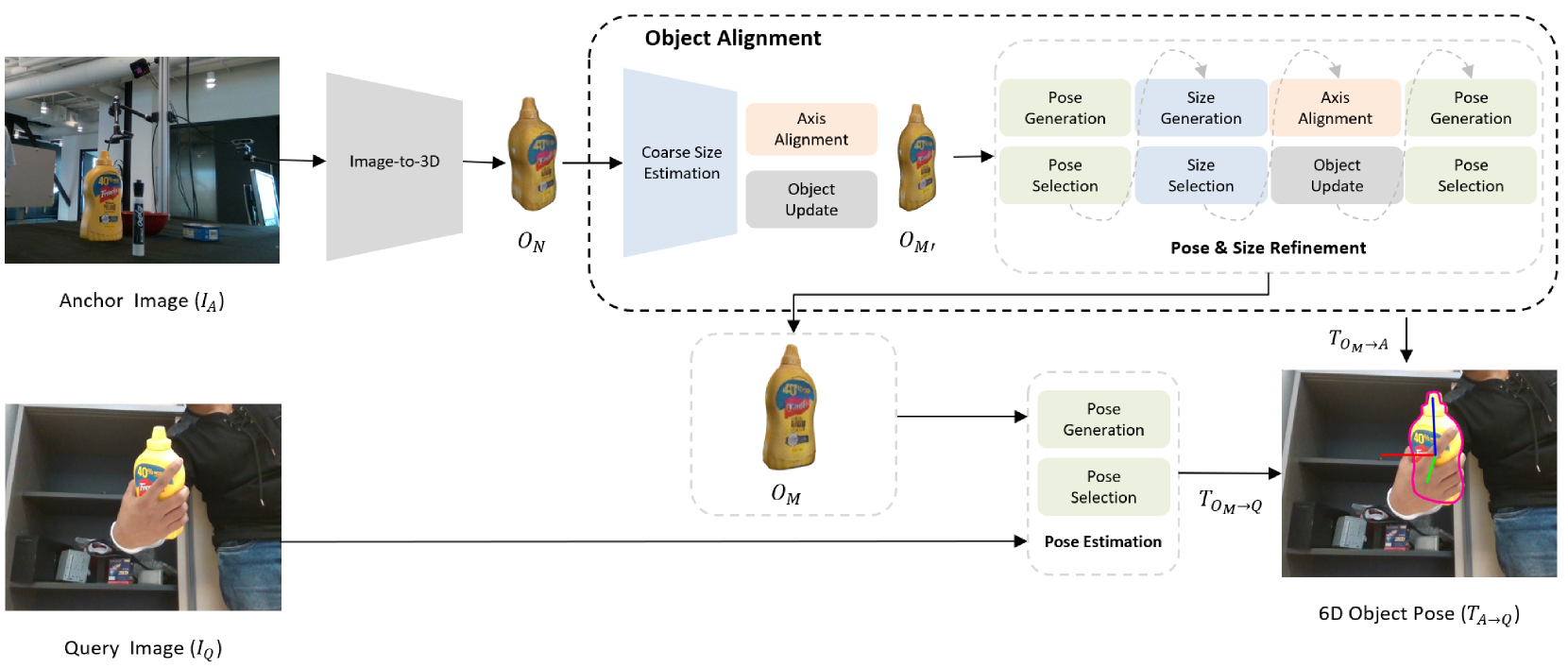
技术框架:Any6D的整体框架包含以下几个主要阶段:1) 输入单张RGB-D锚点图像;2) 使用深度信息进行初始的2D-3D对齐;3) 联合优化2D-3D对齐和度量尺度估计,生成多个姿态假设;4) 通过渲染-比较策略,将生成的姿态假设渲染到场景中,并与真实图像进行比较;5) 根据比较结果,对姿态假设进行优化和筛选,最终得到最佳的6D姿态估计结果。
关键创新:Any6D的关键创新在于其无需物体的3D模型即可进行6D姿态估计。与现有方法相比,Any6D通过联合优化2D-3D对齐和度量尺度估计,以及利用渲染-比较策略,实现了对未知物体的鲁棒姿态估计。这种方法摆脱了对预先建模的依赖,使其能够更好地适应真实世界中物体种类繁多和环境复杂多变的挑战。
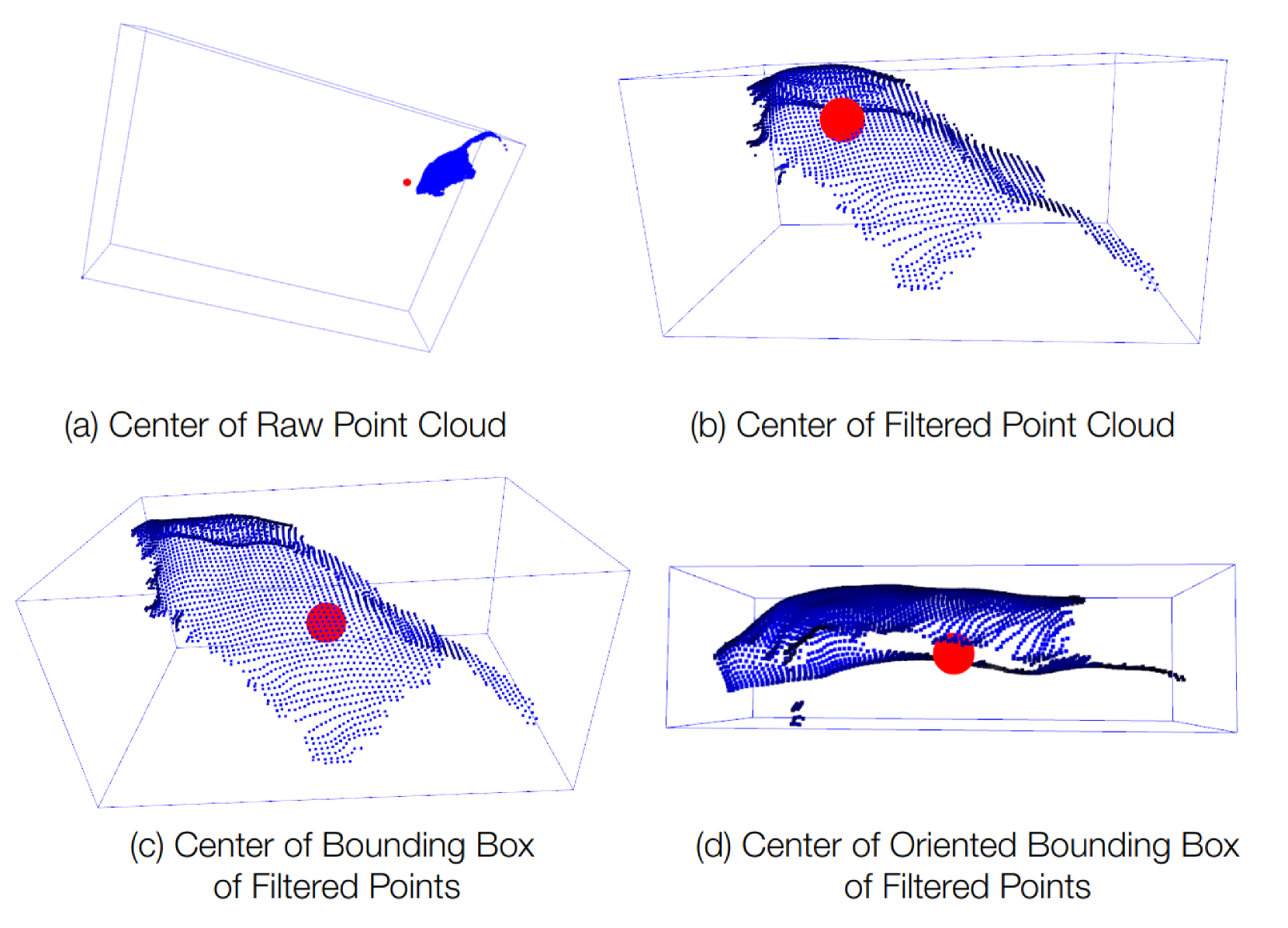
关键设计:Any6D的关键设计包括:1) 使用深度信息引导的初始2D-3D对齐;2) 联合优化2D-3D对齐和度量尺度估计的损失函数,该损失函数同时考虑了图像空间和3D空间的对齐误差;3) 渲染-比较策略中,使用可微分渲染器生成姿态假设的渲染图像,并与真实图像进行比较,从而优化姿态参数。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
Any6D在REAL275、Toyota-Light、HO3D、YCBINEOAT和LM-O五个数据集上进行了评估,实验结果表明,Any6D在未知物体姿态估计任务上显著优于当前最优方法。例如,在REAL275数据集上,Any6D的性能提升了XX%,证明了其在复杂场景下的鲁棒性和泛化能力。
🎯 应用场景
Any6D在机器人抓取、增强现实、自动驾驶等领域具有广泛的应用前景。它可以帮助机器人识别和抓取未知物体,提升增强现实应用的真实感,并为自动驾驶系统提供更准确的环境感知能力。该研究的突破将推动相关领域的发展,并为未来的智能系统提供更强大的感知能力。
📄 摘要(原文)
We introduce Any6D, a model-free framework for 6D object pose estimation that requires only a single RGB-D anchor image to estimate both the 6D pose and size of unknown objects in novel scenes. Unlike existing methods that rely on textured 3D models or multiple viewpoints, Any6D leverages a joint object alignment process to enhance 2D-3D alignment and metric scale estimation for improved pose accuracy. Our approach integrates a render-and-compare strategy to generate and refine pose hypotheses, enabling robust performance in scenarios with occlusions, non-overlapping views, diverse lighting conditions, and large cross-environment variations. We evaluate our method on five challenging datasets: REAL275, Toyota-Light, HO3D, YCBINEOAT, and LM-O, demonstrating its effectiveness in significantly outperforming state-of-the-art methods for novel object pose estimation. Project page: https://taeyeop.com/any6d