PM4Bench: Benchmarking Large Vision-Language Models with Parallel Multilingual Multi-Modal Multi-task Corpus
作者: Junyuan Gao, Jiahe Song, Jiang Wu, Runchuan Zhu, Guanlin Shen, Shasha Wang, Xingjian Wei, Haote Yang, Songyang Zhang, Weijia Li, Bin Wang, Dahua Lin, Lijun Wu, Conghui He
分类: cs.CV, cs.CL
发布日期: 2025-03-24 (更新: 2026-01-07)
备注: Equal contribution: Junyuan Gao, Jiahe Song, Jiang Wu; Corresponding author: Conghui He
🔗 代码/项目: GITHUB
💡 一句话要点
提出PM4Bench,一个用于评估大规模视觉-语言模型的多语言多模态多任务并行基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多语言评估 多模态学习 并行语料库 OCR 基准测试 跨语言能力
📋 核心要点
- 现有LVLM评估依赖非并行语料库和分离的多模态输入,无法公平评估跨语言能力和模拟真实场景。
- PM4Bench构建在严格的并行语料库上,包含10种语言,并引入视觉融合的文本查询,以实现公平和真实的评估。
- 实验表明,视觉融合设置下LVLM性能显著下降,多语言OCR能力是性能瓶颈和跨语言差异的关键因素。
📝 摘要(中文)
大规模视觉-语言模型(LVLMs)展现了良好的多语言能力,但其评估受到两个关键限制:(1)使用非并行语料库,将固有的语言能力差距与数据集伪影混淆,无法公平评估跨语言对齐;(2)分离的多模态输入,偏离了大多数文本嵌入在视觉环境中的真实场景。为了解决这些挑战,我们提出了PM4Bench,这是第一个在10种语言的严格并行语料库上构建的多语言多模态多任务基准。通过消除内容差异,我们的基准能够公平地比较不同语言的模型能力。我们还引入了一种视觉设置,其中文本查询被视觉融合到图像中,迫使模型共同“看”、“读”和“思考”。对10个LVLM的广泛评估揭示了视觉设置中相对于标准输入的性能大幅下降。进一步的分析表明,OCR能力不仅是一个普遍的瓶颈,而且导致了跨语言的性能差异,表明改进多语言OCR对于提高LVLM性能至关重要。我们将在https://github.com/opendatalab/PM4Bench发布PM4Bench。
🔬 方法详解
问题定义:现有的大规模视觉-语言模型(LVLMs)在多语言环境下的评估存在偏差。主要痛点在于:1) 使用非并行语料库,导致评估结果受到数据集本身差异的影响,无法准确反映模型在不同语言上的真实能力;2) 多模态输入是分离的,与实际应用中视觉信息和文本信息紧密结合的场景不符。
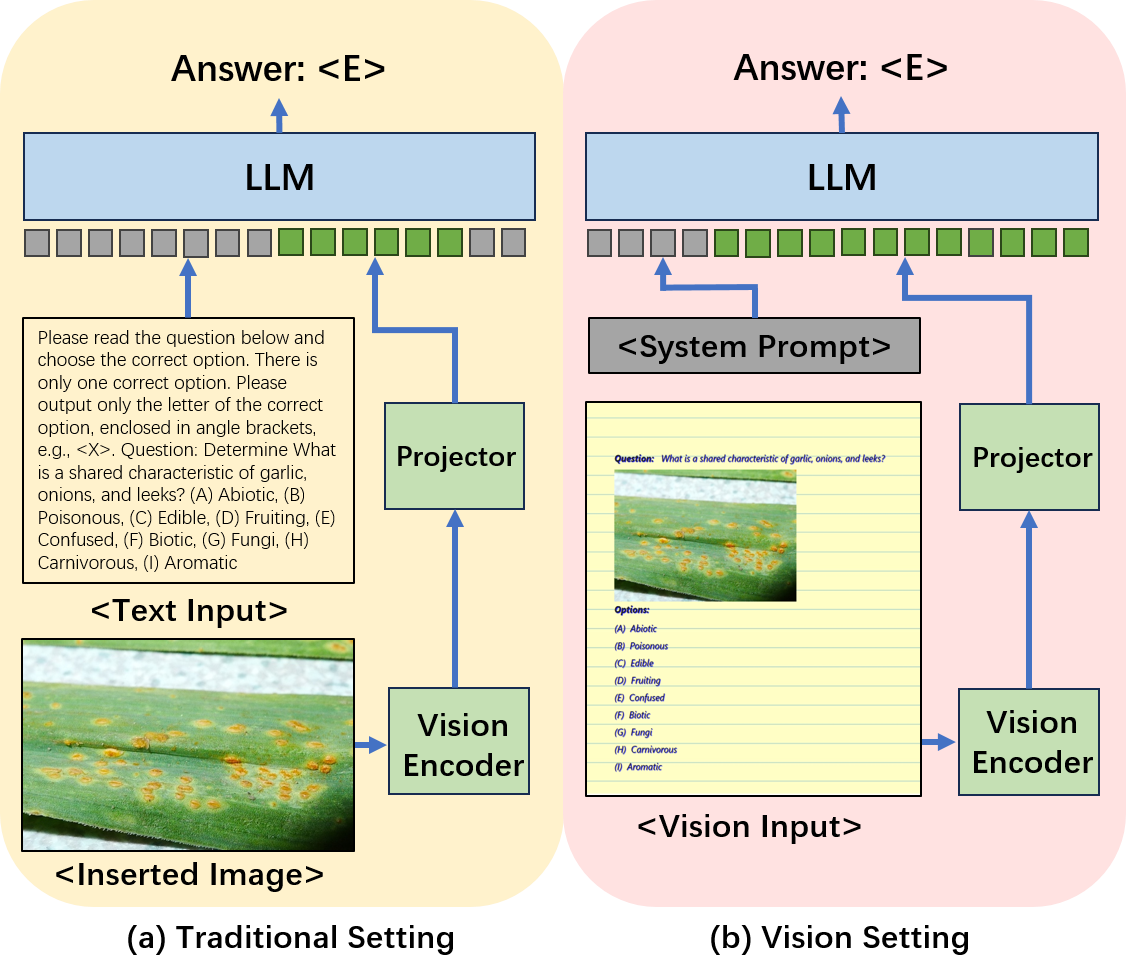
核心思路:为了解决上述问题,论文的核心思路是构建一个严格的并行多语言多模态基准测试集,即PM4Bench。通过使用并行语料库,确保不同语言版本的内容一致,从而消除数据集差异带来的评估偏差。同时,引入视觉融合的文本查询,模拟真实场景中视觉信息和文本信息相互关联的情况,更全面地评估模型的性能。
技术框架:PM4Bench基准测试集包含10种语言的并行语料库,覆盖多种视觉-语言任务。其评估流程包括:1) 构建多语言并行数据集;2) 设计视觉融合的文本查询方式,将文本信息嵌入到图像中;3) 使用PM4Bench评估多个LVLM模型在不同语言和模态下的性能;4) 分析评估结果,找出模型在多语言和多模态方面的瓶颈。
关键创新:PM4Bench的关键创新在于:1) 首次构建了严格的并行多语言多模态基准测试集,为公平评估LVLM的跨语言能力提供了基础;2) 引入视觉融合的文本查询方式,更真实地模拟了实际应用场景,提高了评估的可靠性。
关键设计:在视觉融合方面,论文可能采用了图像编辑或合成技术,将文本信息以自然的方式嵌入到图像中。具体的参数设置和网络结构细节未知,但可以推测,视觉融合过程需要保证文本信息的可读性和与图像内容的语义一致性。此外,评估指标的选择也至关重要,需要综合考虑模型在不同语言和模态下的准确率、召回率等指标。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在视觉融合的文本查询设置下,LVLM的性能相比标准输入显著下降,这突显了现有模型在处理复杂多模态信息方面的不足。进一步分析发现,OCR能力是影响跨语言性能的关键因素,表明提升多语言OCR技术对于提高LVLM的整体性能至关重要。具体性能数据和提升幅度在摘要中未给出。
🎯 应用场景
该研究成果可应用于提升多语言视觉-语言模型的性能,尤其是在跨文化交流、多语言信息检索、多语言内容创作等领域。通过更准确地评估和改进模型的多语言能力,可以促进不同语言和文化之间的信息共享和理解,并为全球用户提供更好的视觉-语言服务。
📄 摘要(原文)
While Large Vision-Language Models (LVLMs) demonstrate promising multilingual capabilities, their evaluation is currently hindered by two critical limitations: (1) the use of non-parallel corpora, which conflates inherent language capability gaps with dataset artifacts, precluding a fair assessment of cross-lingual alignment; and (2) disjointed multimodal inputs, which deviate from real-world scenarios where most texts are embedded within visual contexts. To address these challenges, we propose PM4Bench, the first Multilingual Multi-Modal Multi-task Benchmark constructed on a strictly parallel corpus across 10 languages. By eliminating content divergence, our benchmark enables a fair comparison of model capabilities across different languages. We also introduce a vision setting where textual queries are visually fused into images, compelling models to jointly "see," "read," and "think". Extensive evaluation of 10 LVLMs uncover a substantial performance drop in the Vision setting compared to standard inputs. Further analysis reveals that OCR capability is not only a general bottleneck but also contributes to cross-lingual performance disparities, suggesting that improving multilingual OCR is essential for advancing LVLM performance. We will release PM4Bench at https://github.com/opendatalab/PM4Bench .