ModalTune: Fine-Tuning Slide-Level Foundation Models with Multi-Modal Information for Multi-task Learning in Digital Pathology
作者: Vishwesh Ramanathan, Tony Xu, Pushpak Pati, Faruk Ahmed, Maged Goubran, Anne L. Martel
分类: eess.IV, cs.CV, cs.LG
发布日期: 2025-03-21 (更新: 2025-07-30)
💡 一句话要点
提出ModalTune框架以解决数字病理中的多任务学习问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数字病理 多任务学习 多模态融合 滑动级基础模型 自监督学习 癌症预测 大型语言模型
📋 核心要点
- 现有数字病理方法在处理大规模幻灯片图像时,训练信号不足,导致预测性能受限。
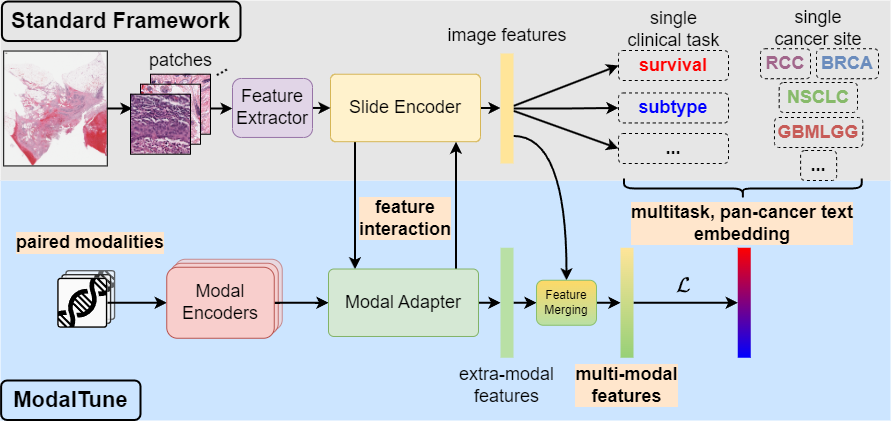
- ModalTune框架通过Modal Adapter整合多模态信息,且不需修改基础模型权重,提升了多任务学习能力。
- ModalTune在四种癌症类型的生存和亚型预测任务中表现出色,且在两个分布外数据集上具有良好的泛化能力。
📝 摘要(中文)
数字病理中的预测任务面临整体幻灯片图像(WSI)庞大尺寸和训练信号弱的挑战。随着计算能力、数据可用性和自监督学习(SSL)的进步,滑动级基础模型(SLFM)得以应用于低数据环境。然而,现有方法未能充分利用任务和模态之间的共享信息。为此,本文提出ModalTune,一个新颖的微调框架,通过引入Modal Adapter整合新模态而不修改SLFM权重,并利用大型语言模型(LLM)将标签编码为文本,从而在单一训练过程中捕捉多任务和癌症类型之间的语义关系。ModalTune在四种癌症类型的预测任务中实现了最新的SOTA结果,同时在泛癌症设置中保持竞争力。
🔬 方法详解
问题定义:本文旨在解决数字病理中多任务学习的挑战,尤其是在处理大规模幻灯片图像时,现有方法未能有效利用任务和模态之间的共享信息。
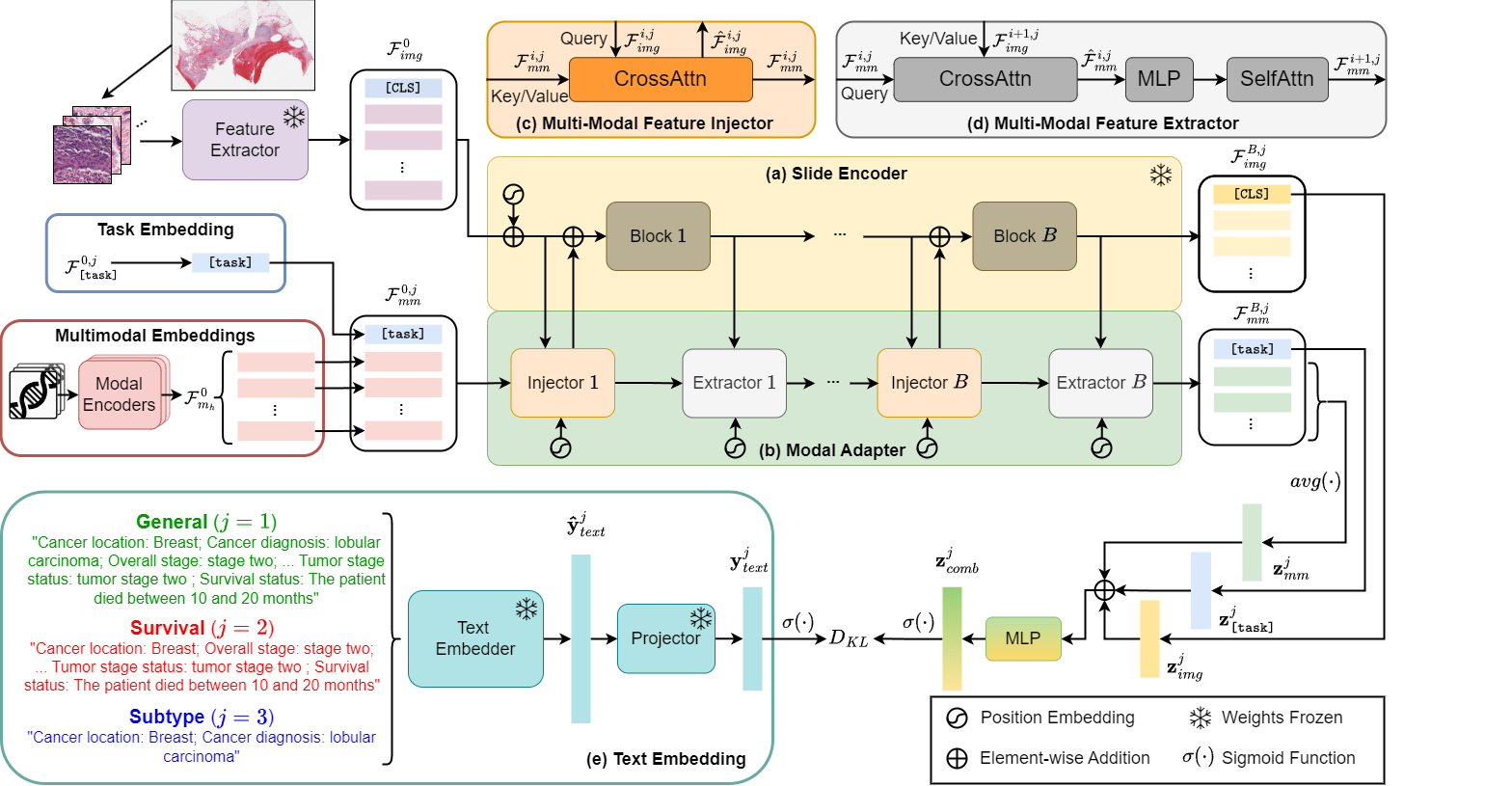
核心思路:ModalTune框架通过引入Modal Adapter,允许在不修改SLFM权重的情况下整合新模态,同时利用大型语言模型(LLM)将标签转化为文本,捕捉多任务之间的语义关系。
技术框架:ModalTune的整体架构包括SLFM作为基础模型,Modal Adapter用于模态整合,以及LLM用于标签编码。训练过程中,模型通过共享信息提升多任务学习的效果。
关键创新:ModalTune是首个统一的微调框架,能够同时处理多模态和多任务学习,且在数字病理领域实现了显著的性能提升。
关键设计:在设计中,Modal Adapter的参数设置经过精心调整,以确保与SLFM的兼容性;损失函数结合了多任务学习的需求,确保模型在不同任务间的平衡性能。整体网络结构经过优化,以提升训练效率和预测准确性。
🖼️ 关键图片
📊 实验亮点
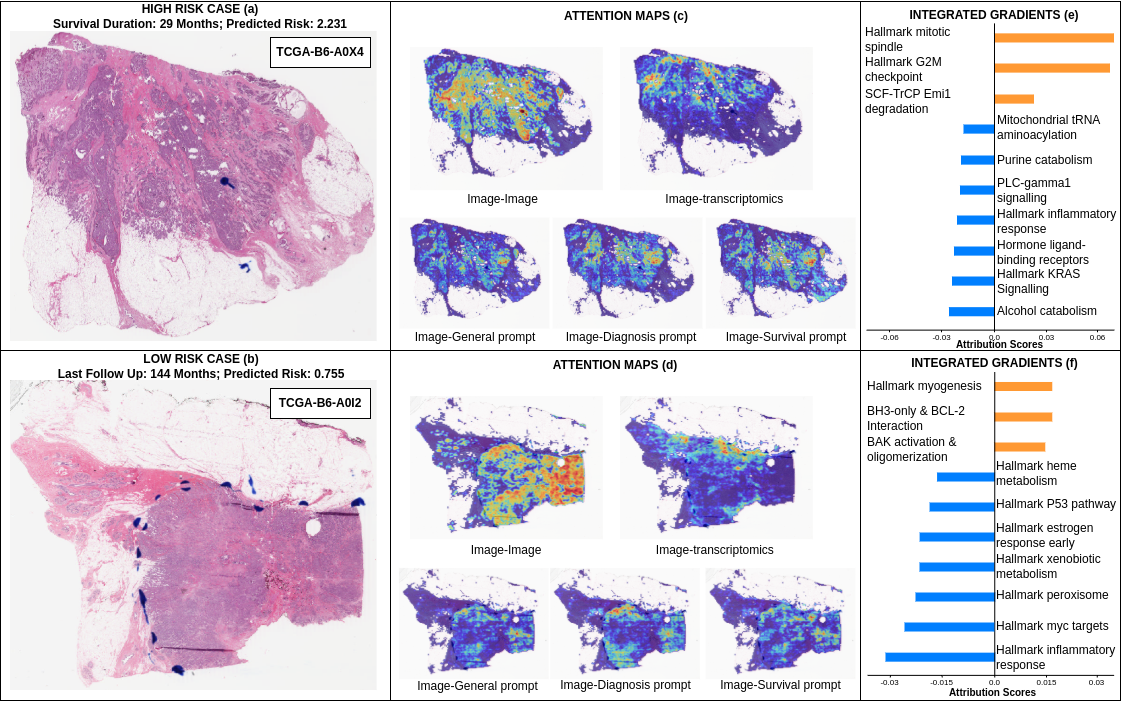
ModalTune在四种癌症类型的预测任务中实现了最新的SOTA结果,相较于单模态和多模态模型,显著提升了生存和癌症亚型预测的准确性。此外,该框架在两个分布外数据集上也展现出良好的泛化能力,证明了其广泛适用性。
🎯 应用场景
该研究在数字病理领域具有广泛的应用潜力,能够帮助医生更准确地进行癌症诊断和预后评估。通过提升多任务学习能力,ModalTune可在临床实践中提供更为精准的决策支持,未来可能推动个性化医疗的发展。
📄 摘要(原文)
Prediction tasks in digital pathology are challenging due to the massive size of whole-slide images (WSIs) and the weak nature of training signals. Advances in computing, data availability, and self-supervised learning (SSL) have paved the way for slide-level foundation models (SLFMs) that can improve prediction tasks in low-data regimes. However, current methods under-utilize shared information between tasks and modalities. To overcome this challenge, we propose ModalTune, a novel fine-tuning framework which introduces the Modal Adapter to integrate new modalities without modifying SLFM weights. Additionally, we use large-language models (LLMs) to encode labels as text, capturing semantic relationships across multiple tasks and cancer types in a single training recipe. ModalTune achieves state-of-the-art (SOTA) results against both uni-modal and multi-modal models across four cancer types, jointly improving survival and cancer subtype prediction while remaining competitive in pan-cancer settings. Additionally, we show ModalTune is generalizable to two out-of-distribution (OOD) datasets. To our knowledge, this is the first unified fine-tuning framework for multi-modal, multi-task, and pan-cancer modeling in digital pathology.