Beyond Semantics: Rediscovering Spatial Awareness in Vision-Language Models
作者: Jianing Qi, Jiawei Liu, Hao Tang, Zhigang Zhu
分类: cs.CV
发布日期: 2025-03-21 (更新: 2025-10-01)
💡 一句话要点
揭示视觉-语言模型空间感知不足,提出可解释性工具并改进多模态注意力机制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 空间推理 可解释性分析 多模态注意力 位置编码
📋 核心要点
- 现有视觉-语言模型在空间推理方面存在不足,未能充分利用视觉编码器中的空间信息。
- 通过分析发现视觉token嵌入范数过大抑制了LLM的位置嵌入,导致空间感知能力下降。
- 开发了位置敏感性指数、跨模态平衡和RoPE敏感性探针等工具,用于分析和改进模型。
📝 摘要(中文)
视觉-语言模型(VLMs)在识别和描述物体方面表现出色,但常常在空间推理方面失败。本研究探讨了LLaVA等VLMs为何未能充分利用空间线索,尽管它们具有位置编码和空间信息丰富的视觉编码器特征。分析表明,关键的不平衡在于视觉token嵌入的范数远大于文本token,从而抑制了LLM的位置嵌入。为了揭示这种机制,我们开发了三种可解释性工具:(1)位置敏感性指数,量化了对token顺序的依赖性;(2)跨模态平衡,揭示了注意力头的分配模式;(3)RoPE敏感性探针,测量了对旋转位置嵌入的依赖性。这些工具揭示了视觉token和系统提示主导了注意力。我们通过有针对性的干预验证了我们的机制理解,这些干预可预测地恢复位置敏感性。这些发现揭示了多模态注意力中先前未知的失效模式,并展示了解释性分析如何指导有原则的改进。
🔬 方法详解
问题定义:视觉-语言模型(VLMs)在理解图像内容和生成文本描述方面取得了显著进展,但它们在空间推理方面仍然存在不足。现有的VLMs,例如LLaVA,虽然具备位置编码和空间信息丰富的视觉特征,但未能有效地利用这些信息进行空间关系的推理,导致在需要理解物体之间相对位置的任务中表现不佳。
核心思路:该论文的核心思路是揭示VLMs中空间感知能力不足的根本原因,并提出相应的改进方法。作者认为,视觉token嵌入的范数远大于文本token,导致LLM对位置信息的敏感性降低。通过平衡视觉和文本token的权重,可以恢复模型对位置信息的敏感性,从而提高空间推理能力。
技术框架:该研究主要通过可解释性分析工具来理解VLMs的行为,并进行有针对性的干预。具体来说,包括以下几个关键模块: 1. 位置敏感性指数(Position Sensitivity Index):用于量化模型对token顺序的依赖程度。 2. 跨模态平衡(Cross Modality Balance):用于揭示注意力头在视觉和文本模态之间的分配模式。 3. RoPE敏感性探针(RoPE Sensitivity Probe):用于测量模型对旋转位置嵌入的依赖程度。
通过这些工具,作者分析了VLMs在处理空间信息时的注意力机制,并发现了视觉token主导注意力的问题。
关键创新:该论文的关键创新在于: 1. 揭示了视觉-语言模型中视觉token嵌入范数过大导致空间感知能力下降的机制。 2. 提出了三种可解释性工具,用于分析和理解多模态注意力机制。 3. 通过有针对性的干预,验证了对模型行为的理解,并成功提高了模型的空间推理能力。
关键设计:论文的关键设计包括: 1. 位置敏感性指数的计算方法:通过交换token的顺序,观察模型输出的变化,从而量化模型对位置信息的敏感程度。 2. 跨模态平衡的分析方法:通过分析注意力头在视觉和文本token上的权重分布,揭示不同模态之间的注意力分配模式。 3. RoPE敏感性探针的设计:通过修改旋转位置嵌入,观察模型输出的变化,从而测量模型对位置嵌入的依赖程度。 4. 干预策略:通过调整视觉和文本token的权重,平衡不同模态之间的注意力,从而提高模型的空间推理能力。
🖼️ 关键图片
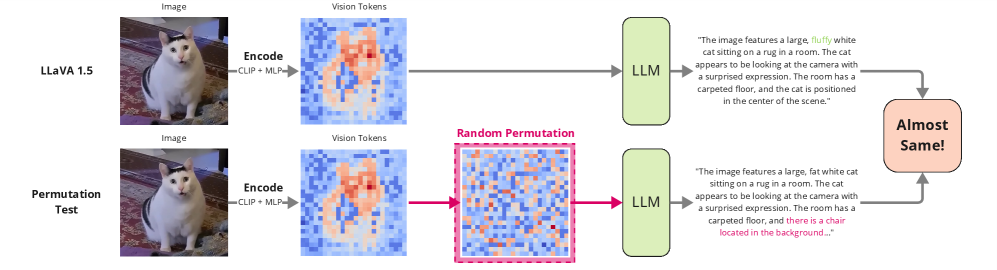
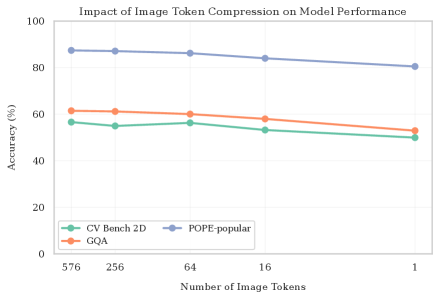
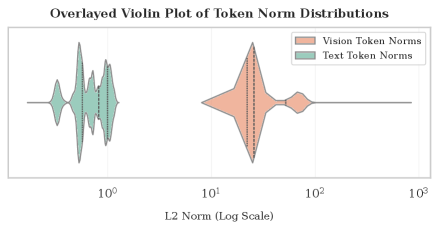
📊 实验亮点
该研究通过实验验证了视觉token嵌入范数过大是导致空间感知能力下降的关键因素。通过调整视觉和文本token的权重,成功恢复了模型对位置信息的敏感性,并在空间推理任务上取得了显著的性能提升。具体提升幅度未知,但研究表明该方法具有有效性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、图像编辑、视觉问答等领域。通过提高视觉-语言模型对空间信息的理解能力,可以使机器人在复杂环境中更好地感知和交互,提升自动化系统的智能化水平,并为用户提供更自然、更准确的视觉信息服务。
📄 摘要(原文)
Vision Language Models (VLMs) excel at identifying and describing objects but often fail at spatial reasoning. We study why VLMs, such as LLaVA, underutilize spatial cues despite having positional encodings and spatially rich vision encoder features. Our analysis reveals a key imbalance: vision token embeddings have much larger norms than text tokens, suppressing LLM's position embedding. To expose this mechanism, we developed three interpretability tools: (1) the Position Sensitivity Index, which quantifies reliance on token order, (2) the Cross Modality Balance, which reveals attention head allocation patterns, and (3) a RoPE Sensitivity probe, which measures dependence on rotary positional embeddings. These tools uncover that vision tokens and system prompts dominate attention. We validated our mechanistic understanding through targeted interventions that predictably restore positional sensitivity. These findings reveal previously unknown failure modes in multimodal attention and demonstrate how interpretability analysis can guide principled improvements.