PP-DocLayout: A Unified Document Layout Detection Model to Accelerate Large-Scale Data Construction
作者: Ting Sun, Cheng Cui, Yuning Du, Yi Liu
分类: cs.CV, cs.AI
发布日期: 2025-03-21
备注: Github Repo: https://github.com/PaddlePaddle/PaddleX
🔗 代码/项目: GITHUB
💡 一句话要点
PP-DocLayout:统一文档布局检测模型,加速大规模数据构建
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档布局分析 目标检测 RT-DETR 文档智能 深度学习
📋 核心要点
- 现有文档布局分析模型难以在不同文档类型和复杂布局上泛化,且大规模数据处理的实时性不足。
- PP-DocLayout通过统一的检测模型,实现了对多种文档类型和布局的高精度、高效率分析。
- PP-DocLayout提供了三种不同规模的模型,在精度、效率和资源占用之间实现了灵活的平衡。
📝 摘要(中文)
文档布局分析是文档智能中的关键预处理步骤,能够检测和定位结构元素,如标题、文本块、表格和公式。现有的布局检测模型在跨文档类型泛化、处理复杂布局以及实现大规模数据处理的实时性能方面面临重大挑战。为了解决这些限制,我们提出了PP-DocLayout,它在高精度和高效率方面实现了对各种文档格式中23种布局区域的识别。为了满足不同的需求,我们提供了三种不同规模的模型。PP-DocLayout-L是一个基于RT-DETR-L检测器的高精度模型,在T4 GPU上实现了90.4%的mAP@0.5和每页13.4毫秒的端到端推理时间。PP-DocLayout-M是一个平衡模型,在T4 GPU上提供75.2%的mAP@0.5和每页12.7毫秒的推理时间。PP-DocLayout-S是一个为资源受限环境和实时应用设计的高效模型,在T4 GPU上具有每页8.1毫秒的推理时间,在CPU上具有14.5毫秒的推理时间。这项工作不仅推进了文档布局分析的最新技术,而且为构建高质量训练数据提供了一个强大的解决方案,从而推动了文档智能和多模态人工智能系统的发展。
🔬 方法详解
问题定义:论文旨在解决文档布局分析中现有模型泛化能力差、处理复杂布局困难以及大规模数据处理实时性不足的问题。现有方法难以兼顾精度和效率,无法满足不同应用场景的需求。
核心思路:论文的核心思路是利用先进的目标检测模型(RT-DETR)构建一个统一的文档布局检测框架,通过优化模型结构和参数,实现在不同规模的模型上精度和效率的平衡。针对不同应用场景,提供不同规模的模型选择。
技术框架:PP-DocLayout采用基于RT-DETR的目标检测框架。整体流程包括:输入文档图像,经过预处理后输入到RT-DETR模型中,模型输出各个布局元素的边界框和类别信息,最后进行后处理得到最终的布局分析结果。提供了三种不同规模的模型:PP-DocLayout-L(高精度)、PP-DocLayout-M(平衡)、PP-DocLayout-S(高效率)。
关键创新:关键创新在于利用RT-DETR框架进行文档布局检测,并针对不同应用场景设计了不同规模的模型。通过模型结构的优化和参数调整,在精度和效率之间取得了良好的平衡。
关键设计:论文采用了RT-DETR-L作为高精度模型的基础,并针对文档布局分析任务进行了微调。具体的技术细节包括:数据集的选择和预处理、损失函数的选择和优化、以及模型训练的策略。具体参数设置未知。
🖼️ 关键图片

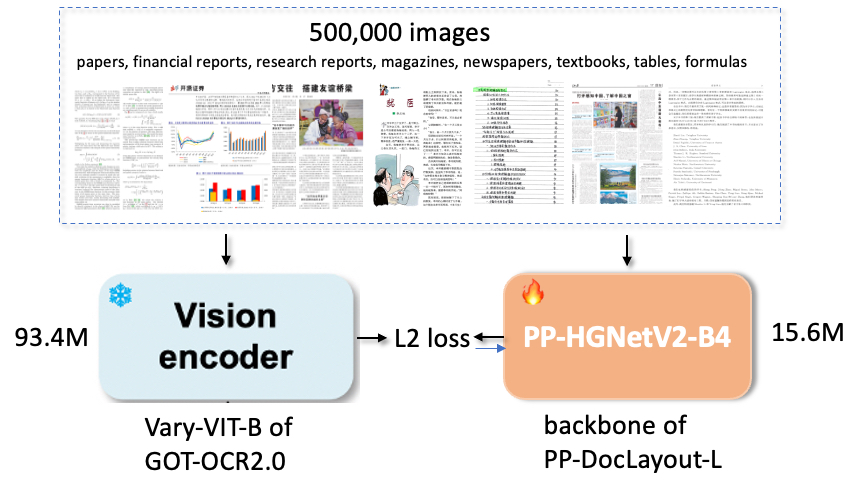

📊 实验亮点
PP-DocLayout在文档布局检测任务上取得了显著的性能提升。PP-DocLayout-L在T4 GPU上实现了90.4%的mAP@0.5,推理时间为13.4ms/页。PP-DocLayout-S在T4 GPU上推理时间仅为8.1ms/页,在CPU上为14.5ms/页。三种不同规模的模型在精度和效率之间实现了良好的平衡,满足了不同应用场景的需求。
🎯 应用场景
PP-DocLayout可广泛应用于文档数字化、自动化办公、信息抽取、智能文档管理等领域。通过准确高效地识别文档布局,可以为后续的文档理解、信息检索和知识挖掘提供基础支持,提升工作效率,降低人工成本。未来可应用于更复杂的文档场景,例如手写文档、低质量扫描文档等。
📄 摘要(原文)
Document layout analysis is a critical preprocessing step in document intelligence, enabling the detection and localization of structural elements such as titles, text blocks, tables, and formulas. Despite its importance, existing layout detection models face significant challenges in generalizing across diverse document types, handling complex layouts, and achieving real-time performance for large-scale data processing. To address these limitations, we present PP-DocLayout, which achieves high precision and efficiency in recognizing 23 types of layout regions across diverse document formats. To meet different needs, we offer three models of varying scales. PP-DocLayout-L is a high-precision model based on the RT-DETR-L detector, achieving 90.4% mAP@0.5 and an end-to-end inference time of 13.4 ms per page on a T4 GPU. PP-DocLayout-M is a balanced model, offering 75.2% mAP@0.5 with an inference time of 12.7 ms per page on a T4 GPU. PP-DocLayout-S is a high-efficiency model designed for resource-constrained environments and real-time applications, with an inference time of 8.1 ms per page on a T4 GPU and 14.5 ms on a CPU. This work not only advances the state of the art in document layout analysis but also provides a robust solution for constructing high-quality training data, enabling advancements in document intelligence and multimodal AI systems. Code and models are available at https://github.com/PaddlePaddle/PaddleX .