DynamicVis: An Efficient and General Visual Foundation Model for Remote Sensing Image Understanding
作者: Keyan Chen, Chenyang Liu, Bowen Chen, Wenyuan Li, Zhengxia Zou, Zhenwei Shi
分类: cs.CV
发布日期: 2025-03-20
💡 一句话要点
DynamicVis:面向遥感图像理解的高效通用视觉基础模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像理解 视觉基础模型 动态视觉感知 选择性注意机制 多实例学习 高效计算 高分辨率图像处理
📋 核心要点
- 现有遥感图像处理方法泛化能力不足,无法有效处理高分辨率、大场景图像中目标稀疏的问题。
- DynamicVis通过动态区域感知骨干网络,平衡局部细节和全局上下文,高效编码大规模遥感数据。
- DynamicVis在九个下游任务上表现出多功能性,并显著降低了计算延迟和GPU内存占用。
📝 摘要(中文)
遥感技术的进步提高了卫星图像的空间分辨率,从而能够进行更详细的视觉表示和多样化的解译。然而,现有方法在不同应用中的泛化能力有限。一些现代基础模型展现出潜力,但受到跨任务适应性不足的限制,并且主要处理低分辨率、尺寸受限的图像,无法充分利用高分辨率数据或大型场景的语义信息。遥感图像与自然图像存在根本差异,关键前景目标(如海上物体、人工建筑物)通常只占据极小的空间比例(约1%),且分布稀疏。从冗长的2D tokens(约100,000)中高效地建模跨任务通用知识,对遥感图像理解而言是一个重大挑战。受人类视觉系统选择性注意机制的启发,我们提出了DynamicVis,一种用于遥感图像的动态视觉感知基础模型。该框架集成了一种基于选择性状态空间模型的新型动态区域感知骨干网络,该网络策略性地平衡了局部细节提取与全局上下文集成,从而能够以计算高效的方式编码大规模数据,同时保持架构的可扩展性。为了增强跨任务知识迁移,我们引入了一种利用元嵌入表示的多实例学习范式,该范式在百万级区域级别标注上进行训练。在九个下游任务上的评估证明了该模型的多功能性。DynamicVis以卓越的效率实现了多层次的特征建模,处理(2048x2048)像素的延迟为97毫秒(是ViT的6%),GPU内存占用为833 MB(是ViT的3%)。
🔬 方法详解
问题定义:遥感图像理解面临的挑战在于如何从高分辨率、大场景图像中有效提取信息,特别是当关键目标(如船只、建筑物)占比很小且分布稀疏时。现有方法要么泛化能力不足,无法适应不同的遥感应用,要么无法有效利用高分辨率数据,导致性能受限。此外,处理大规模遥感图像需要消耗大量的计算资源,限制了其在实际应用中的部署。
核心思路:DynamicVis的核心思路是模仿人类视觉系统的选择性注意机制,通过动态地关注图像中的重要区域,从而提高计算效率和模型性能。该模型旨在平衡局部细节的提取和全局上下文的理解,从而更好地捕捉遥感图像中的复杂语义信息。通过这种方式,DynamicVis能够更有效地处理高分辨率、大场景的遥感图像,并提高模型在不同任务中的泛化能力。
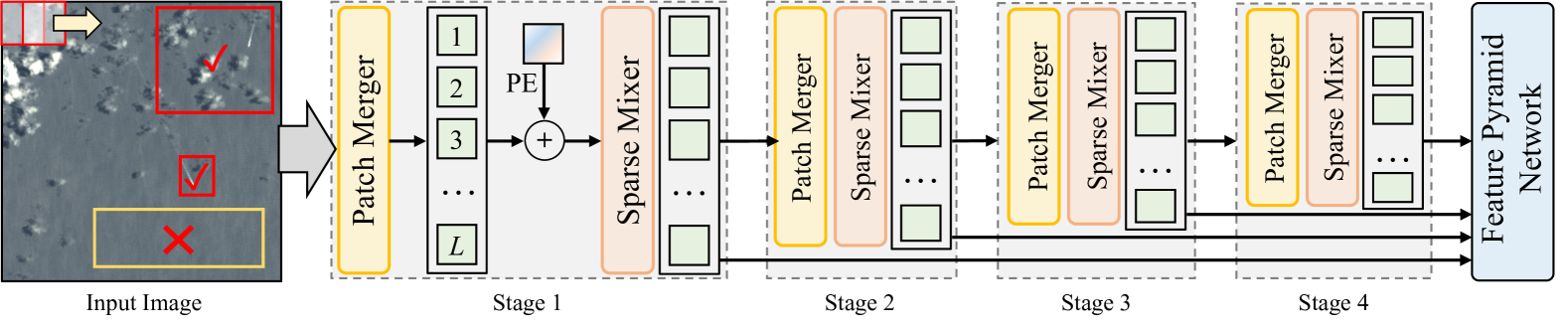
技术框架:DynamicVis框架主要包含两个核心模块:动态区域感知骨干网络和多实例学习范式。动态区域感知骨干网络基于选择性状态空间模型,用于高效地编码大规模遥感数据。多实例学习范式利用元嵌入表示,在百万级区域级别标注上进行训练,以增强跨任务知识迁移。整个框架旨在实现高效的多层次特征建模,并降低计算资源消耗。
关键创新:DynamicVis的关键创新在于其动态区域感知骨干网络,该网络能够根据图像内容动态地调整感受野,从而更有效地提取局部细节和全局上下文信息。与传统的卷积神经网络或Transformer模型相比,DynamicVis能够以更低的计算成本处理高分辨率图像,并提高模型在不同任务中的泛化能力。此外,多实例学习范式也有助于提高模型对稀疏目标的识别能力。
关键设计:DynamicVis的关键设计包括选择性状态空间模型的具体实现方式,例如如何设计状态转移矩阵和观测矩阵,以及如何将局部细节和全局上下文信息进行融合。此外,多实例学习范式的具体实现方式,例如如何生成元嵌入表示,以及如何设计损失函数,也是重要的技术细节。论文中可能还涉及一些超参数的设置,例如学习率、批大小等,这些参数的选择也会影响模型的性能。
🖼️ 关键图片


📊 实验亮点
DynamicVis在处理2048x2048像素的遥感图像时,延迟仅为97毫秒,是ViT的6%。GPU内存占用为833MB,是ViT的3%。在九个下游任务上的评估表明,DynamicVis具有出色的多功能性,证明了其在遥感图像理解方面的卓越性能和效率。
🎯 应用场景
DynamicVis在遥感图像解译领域具有广泛的应用前景,例如目标检测(如船只、建筑物)、土地利用分类、灾害监测、城市规划等。该模型能够高效处理高分辨率遥感图像,并提高模型在不同任务中的泛化能力,从而为遥感图像的智能化分析提供更强大的工具。未来,DynamicVis有望应用于更广泛的遥感应用场景,并促进遥感技术的进一步发展。
📄 摘要(原文)
The advancement of remote sensing technology has improved the spatial resolution of satellite imagery, facilitating more detailed visual representations for diverse interpretations. However, existing methods exhibit limited generalization capabilities across varied applications. While some contemporary foundation models demonstrate potential, they are hindered by insufficient cross-task adaptability and primarily process low-resolution imagery of restricted sizes, thus failing to fully exploit high-resolution data or leverage comprehensive large-scene semantics. Crucially, remote sensing imagery differs fundamentally from natural images, as key foreground targets (eg., maritime objects, artificial structures) often occupy minimal spatial proportions (~1%) and exhibit sparse distributions. Efficiently modeling cross-task generalizable knowledge from lengthy 2D tokens (~100,000) poses a significant challenge yet remains critical for remote sensing image understanding. Motivated by the selective attention mechanisms inherent to the human visual system, we propose DynamicVis, a dynamic visual perception foundation model for remote sensing imagery. The framework integrates a novel dynamic region perception backbone based on the selective state space model, which strategically balances localized detail extraction with global contextual integration, enabling computationally efficient encoding of large-scale data while maintaining architectural scalability. To enhance cross-task knowledge transferring, we introduce a multi-instance learning paradigm utilizing meta-embedding representations, trained on million-scale region-level annotations. Evaluations across nine downstream tasks demonstrate the model's versatility. DynamicVis achieves multi-level feature modeling with exceptional efficiency, processing (2048x2048) pixels with 97 ms latency (6% of ViT's) and 833 MB GPU memory (3% of ViT's).