GAEA: A Geolocation Aware Conversational Assistant
作者: Ron Campos, Ashmal Vayani, Parth Parag Kulkarni, Rohit Gupta, Aizan Zafar, Aritra Dutta, Mubarak Shah
分类: cs.CV, cs.LG
发布日期: 2025-03-20 (更新: 2025-09-03)
备注: The dataset and code used in this submission is available at: https://ucf-crcv.github.io/GAEA/
💡 一句话要点
提出GAEA:一个地理位置感知的对话式助手,用于图像地理定位。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像地理定位 对话式助手 多模态模型 地理信息系统 OpenStreetMap
📋 核心要点
- 现有图像地理定位模型无法提供超出GPS坐标的知识,缺乏对位置的理解和对话能力。
- GAEA通过构建一个地理位置感知的对话模型,使用户能够以对话方式获取图像位置的相关信息。
- GAEA在GAEA-Bench基准测试中显著优于现有开源和专有LMMs,最高提升达18.2%。
📝 摘要(中文)
图像地理定位是一项具有挑战性的任务,传统上AI模型预测图像的精确GPS坐标。然而,用户无法利用该模型进一步扩展知识,因为模型缺乏对位置的理解和与用户交流的对话能力。随着大型多模态模型(LMMs)的巨大进步,研究人员尝试通过LMMs进行图像地理定位,但问题仍然存在,LMMs在地理定位等专业下游任务中表现不佳。本文提出了一个对话模型GAEA来解决这个问题,该模型可以根据用户需求提供图像位置的相关信息。由于缺乏训练此类模型的大规模数据集,因此提出了GAEA-1.4M,这是一个包含超过80万张图像和约140万个问答对的综合数据集,通过利用OpenStreetMap(OSM)属性和地理环境线索构建。为了进行定量评估,提出了一个包含3.5k图像-文本对的GAEA-Bench基准,用于评估具备多样化问题类型的对话能力。评估了11个最先进的开源和专有LMMs,结果表明GAEA显著优于最佳开源模型LLaVA-OneVision 18.2%,优于最佳专有模型GPT-4o 7.2%。数据集、模型和代码均已开源。
🔬 方法详解
问题定义:图像地理定位任务的现有方法主要集中于预测图像的精确GPS坐标,但缺乏对图像所处位置的深层理解和与用户进行交互的能力。用户无法通过这些模型获取关于该位置的更多信息,例如地标、历史背景等。现有的大型多模态模型(LMMs)在通用任务上表现良好,但在地理定位等专业下游任务中表现不佳。
核心思路:GAEA的核心思路是构建一个地理位置感知的对话式助手,它不仅能够识别图像的位置,还能理解该位置的地理环境和相关信息,并以对话的方式与用户进行交互。通过这种方式,用户可以更全面地了解图像所处的位置,并获取更丰富的知识。
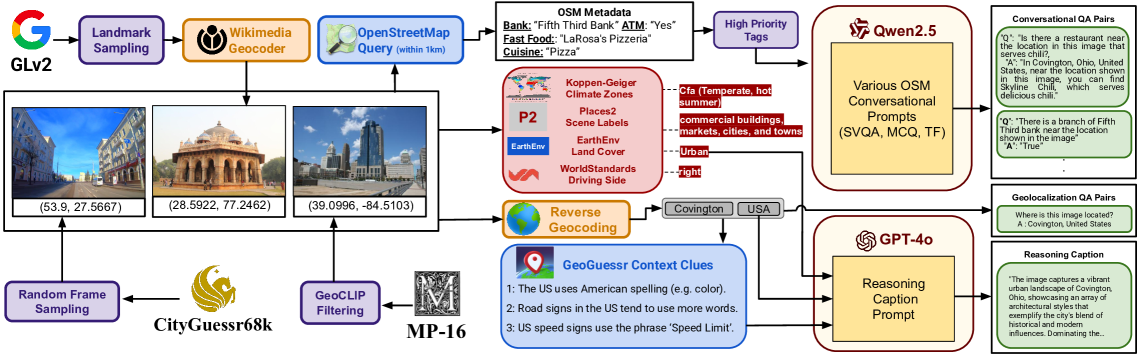
技术框架:GAEA的整体框架包含以下几个主要部分:1) 数据集构建:构建大规模的GAEA-1.4M数据集,包含图像和对应的问答对,这些问答对涵盖了图像位置的各种信息。2) 模型训练:使用GAEA-1.4M数据集训练对话模型,使其具备地理位置感知和对话能力。3) 基准测试:构建GAEA-Bench基准测试,用于评估模型的对话能力和地理位置理解能力。
关键创新:GAEA的关键创新在于:1) 提出了一个地理位置感知的对话式助手,能够以对话方式提供图像位置的相关信息。2) 构建了一个大规模的GAEA-1.4M数据集,用于训练此类模型。3) 提出了GAEA-Bench基准测试,用于评估模型的对话能力和地理位置理解能力。与现有方法相比,GAEA不仅能够预测图像的位置,还能理解该位置的地理环境和相关信息,并以对话的方式与用户进行交互。
关键设计:GAEA-1.4M数据集的构建利用了OpenStreetMap(OSM)属性和地理环境线索,生成了多样化的问答对。GAEA-Bench基准测试包含了多种问题类型,用于全面评估模型的对话能力。模型训练的具体参数设置、损失函数和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
GAEA在GAEA-Bench基准测试中表现出色,显著优于现有的开源和专有LMMs。具体而言,GAEA优于最佳开源模型LLaVA-OneVision 18.2%,优于最佳专有模型GPT-4o 7.2%。这些结果表明,GAEA在地理位置感知和对话能力方面具有显著优势。
🎯 应用场景
GAEA具有广泛的应用前景,例如旅游导览、城市探索、地理教育、智能安防等。它可以帮助用户更好地了解图像所处的位置,获取更丰富的知识,并提供个性化的服务。未来,GAEA可以与增强现实(AR)和虚拟现实(VR)技术相结合,为用户提供更沉浸式的体验。
📄 摘要(原文)
Image geolocalization, in which an AI model traditionally predicts the precise GPS coordinates of an image, is a challenging task with many downstream applications. However, the user cannot utilize the model to further their knowledge beyond the GPS coordinates; the model lacks an understanding of the location and the conversational ability to communicate with the user. In recent days, with the tremendous progress of large multimodal models (LMMs) -- proprietary and open-source -- researchers have attempted to geolocalize images via LMMs. However, the issues remain unaddressed; beyond general tasks, for more specialized downstream tasks, such as geolocalization, LMMs struggle. In this work, we propose solving this problem by introducing a conversational model, GAEA, that provides information regarding the location of an image as the user requires. No large-scale dataset enabling the training of such a model exists. Thus, we propose GAEA-1.4M, a comprehensive dataset comprising over 800k images and approximately 1.4M question-answer pairs, constructed by leveraging OpenStreetMap (OSM) attributes and geographical context clues. For quantitative evaluation, we propose a diverse benchmark, GAEA-Bench, comprising 3.5k image-text pairs to evaluate conversational capabilities equipped with diverse question types. We consider 11 state-of-the-art open-source and proprietary LMMs and demonstrate that GAEA significantly outperforms the best open-source model, LLaVA-OneVision, by 18.2% and the best proprietary model, GPT-4o, by 7.2%. Our dataset, model and codes are available.