JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse
作者: Muyao Li, Zihao Wang, Kaichen He, Xiaojian Ma, Yitao Liang
分类: cs.CV, cs.AI
发布日期: 2025-03-20 (更新: 2025-09-12)
备注: Accepted by ACL 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出JARVIS-VLA,通过视觉语言后训练提升VLA模型在Minecraft中的决策能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 视觉语言动作 后训练 Minecraft 决策智能
📋 核心要点
- 现有VLA模型主要关注动作后训练,忽略了对基础视觉语言模型(VLM)的增强,限制了其在复杂环境中的表现。
- 提出Act from Visual Language Post-Training方法,通过视觉和语言指导,以自监督方式提升VLM的世界知识、视觉识别和空间定位能力。
- 实验表明,该方法在Minecraft原子任务上相比最佳基线提升40%,并超越了传统模仿学习策略,达到SOTA性能。
📝 摘要(中文)
近年来,基于动作的开放世界环境决策问题受到了广泛关注。视觉语言动作(VLA)模型,通过大规模网络数据集的预训练,在决策任务中展现出潜力。然而,以往工作主要集中于动作后训练,往往忽略了对基础模型本身的增强。为此,我们提出了一种新颖的方法,即“从视觉语言后训练中行动”,通过视觉和语言指导,以自监督的方式改进视觉语言模型(VLM)。这种增强提高了模型在开放世界环境中的世界知识、视觉识别和空间定位能力。基于上述后训练范式,我们获得了首个能够在Minecraft中遵循人类指令完成超过1000种不同原子任务(包括制作、冶炼、烹饪、采矿和杀戮)的VLA模型。实验表明,在非轨迹任务上进行后训练,相比于最佳基线智能体,在一系列不同的原子任务上取得了显著的40%的性能提升。此外,我们的方法在Minecraft中超越了传统的基于模仿学习的策略,实现了最先进的性能。我们已开源代码、模型和数据集,以促进进一步的研究。
🔬 方法详解
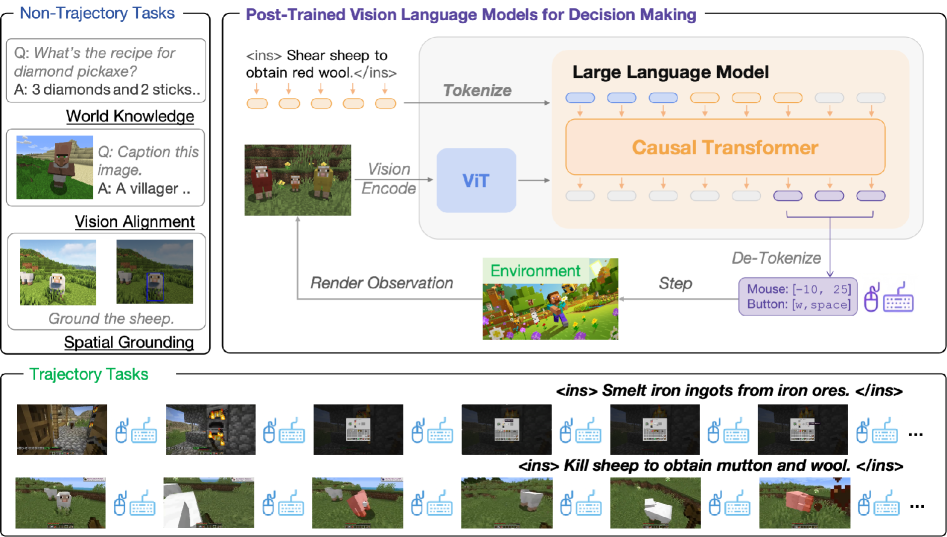
问题定义:论文旨在解决视觉语言动作模型(VLA)在开放世界环境(如Minecraft)中进行决策时,由于基础视觉语言模型(VLM)能力不足而导致性能受限的问题。现有方法主要集中于动作后训练,忽略了对VLM本身知识、视觉理解和空间推理能力的提升,这使得模型难以有效理解复杂指令并做出正确的动作。
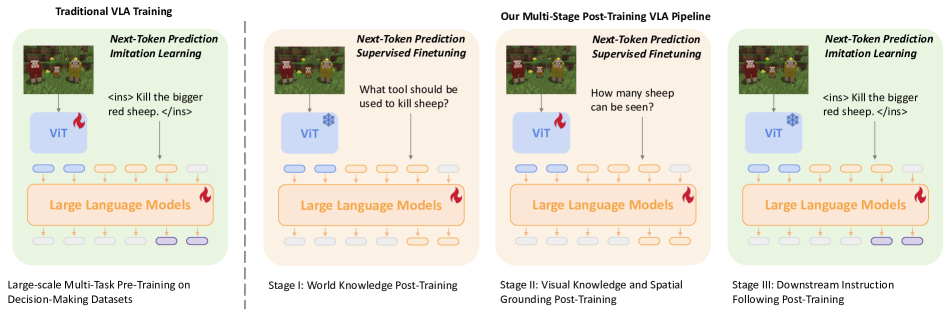
核心思路:论文的核心思路是通过视觉语言后训练(Act from Visual Language Post-Training)来增强VLM。具体来说,利用Minecraft游戏环境中的视觉和语言信息,以自监督的方式训练VLM,使其更好地理解游戏世界,从而提升其在VLA任务中的表现。这种方法强调在动作训练之前,先提升VLM的基础能力。
技术框架:整体框架包含两个主要阶段:首先,利用Minecraft游戏数据进行VLM的后训练,提升其视觉和语言理解能力。然后,将后训练后的VLM应用于VLA任务,使其能够根据人类指令在游戏中执行各种原子任务。具体流程包括:收集Minecraft游戏中的视觉和语言数据;设计自监督学习任务,例如视觉问答、图像描述等;使用收集的数据训练VLM;将训练好的VLM集成到VLA模型中;在Minecraft环境中评估VLA模型的性能。
关键创新:最重要的技术创新点在于提出了视觉语言后训练的概念,并将其应用于VLA模型。与以往主要关注动作后训练的方法不同,该方法强调在动作训练之前,先通过视觉和语言信息来提升VLM的基础能力。这种方法能够更有效地利用游戏环境中的数据,提升模型的泛化能力和鲁棒性。
关键设计:论文中关键的设计包括:自监督学习任务的设计,例如,可以设计视觉问答任务,让模型根据游戏截图回答相关问题;损失函数的设计,可以使用交叉熵损失函数来训练模型;网络结构的选择,可以选择Transformer等常用的视觉语言模型结构。此外,数据增强也是一个重要的环节,可以通过对游戏截图进行旋转、缩放等操作来增加数据的多样性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过视觉语言后训练,VLA模型在Minecraft原子任务上的性能相比最佳基线提升了40%。此外,该方法还超越了传统的基于模仿学习的策略,实现了最先进的性能。这些结果表明,视觉语言后训练是一种有效的提升VLA模型性能的方法。
🎯 应用场景
该研究成果可应用于游戏AI、机器人控制、虚拟助手等领域。通过提升VLA模型在复杂环境中的决策能力,可以开发出更智能的游戏AI,帮助玩家完成各种任务;也可以应用于机器人控制,使机器人能够根据人类指令在现实世界中执行各种任务;还可以应用于虚拟助手,使其能够更好地理解用户的需求,并提供更个性化的服务。
📄 摘要(原文)
Recently, action-based decision-making in open-world environments has gained significant attention. Visual Language Action (VLA) models, pretrained on large-scale web datasets, have shown promise in decision-making tasks. However, previous work has primarily focused on action post-training, often neglecting enhancements to the foundational model itself. In response, we introduce a novel approach, Act from Visual Language Post-Training, which refines Visual Language Models (VLMs) through visual and linguistic guidance in a self-supervised manner. This enhancement improves the models' capabilities in world knowledge, visual recognition, and spatial grounding in open-world environments. Following the above post-training paradigms, we obtain the first VLA models in Minecraft that can follow human instructions on over 1k different atomic tasks, including crafting, smelting, cooking, mining, and killing. Our experiments demonstrate that post-training on non-trajectory tasks leads to a significant 40% improvement over the best agent baseline on a diverse set of atomic tasks. Furthermore, we demonstrate that our approach surpasses traditional imitation learning-based policies in Minecraft, achieving state-of-the-art performance. We have open-sourced the code, models, and datasets to foster further research. The project page can be found in https://craftjarvis.github.io/JarvisVLA.