UniCrossAdapter: Multimodal Adaptation of CLIP for Radiology Report Generation
作者: Yaxiong Chen, Chuang Du, Chunlei Li, Jingliang Hu, Yilei Shi, Shengwu Xiong, Xiao Xiang Zhu, Lichao Mou
分类: cs.CV
发布日期: 2025-03-20
备注: MICCAI 2024 Workshop
🔗 代码/项目: GITHUB
💡 一句话要点
提出UniCrossAdapter,用于CLIP在放射影像报告生成任务上的多模态迁移学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射影像报告生成 CLIP 迁移学习 多模态学习 领域自适应
📋 核心要点
- 医学影像报告生成任务面临数据稀缺的挑战,直接应用预训练模型存在领域差异。
- 提出UniCrossAdapter,通过轻量级适配器模块,高效地将CLIP迁移到医学影像领域。
- 实验表明,该方法在放射影像报告生成任务上取得了state-of-the-art的结果。
📝 摘要(中文)
自动放射影像报告生成旨在加速放射科医生繁琐且易出错的报告流程。由于标注的医学数据相对稀缺,学习对齐医学图像和文本发现仍然具有挑战性。本文提出从大规模预训练的视觉-语言模型CLIP迁移表征,以更好地捕捉图像和文本之间的跨模态语义。然而,由于自然图像和放射影像之间的领域差距,直接应用CLIP效果欠佳。为了实现高效的适应,我们引入了UniCrossAdapter,这是一种轻量级的适配器模块,它被集成到CLIP中,并在目标任务上进行微调,同时保持基础参数固定。适配器分布在不同的模态及其交互中,以增强视觉-语言对齐。在两个公共数据集上的实验表明,我们的方法是有效的,并在放射影像报告生成方面推进了最先进的技术水平。所提出的迁移学习框架提供了一种利用大规模预训练模型中的语义知识来解决数据稀缺的医学视觉-语言任务的方法。
🔬 方法详解
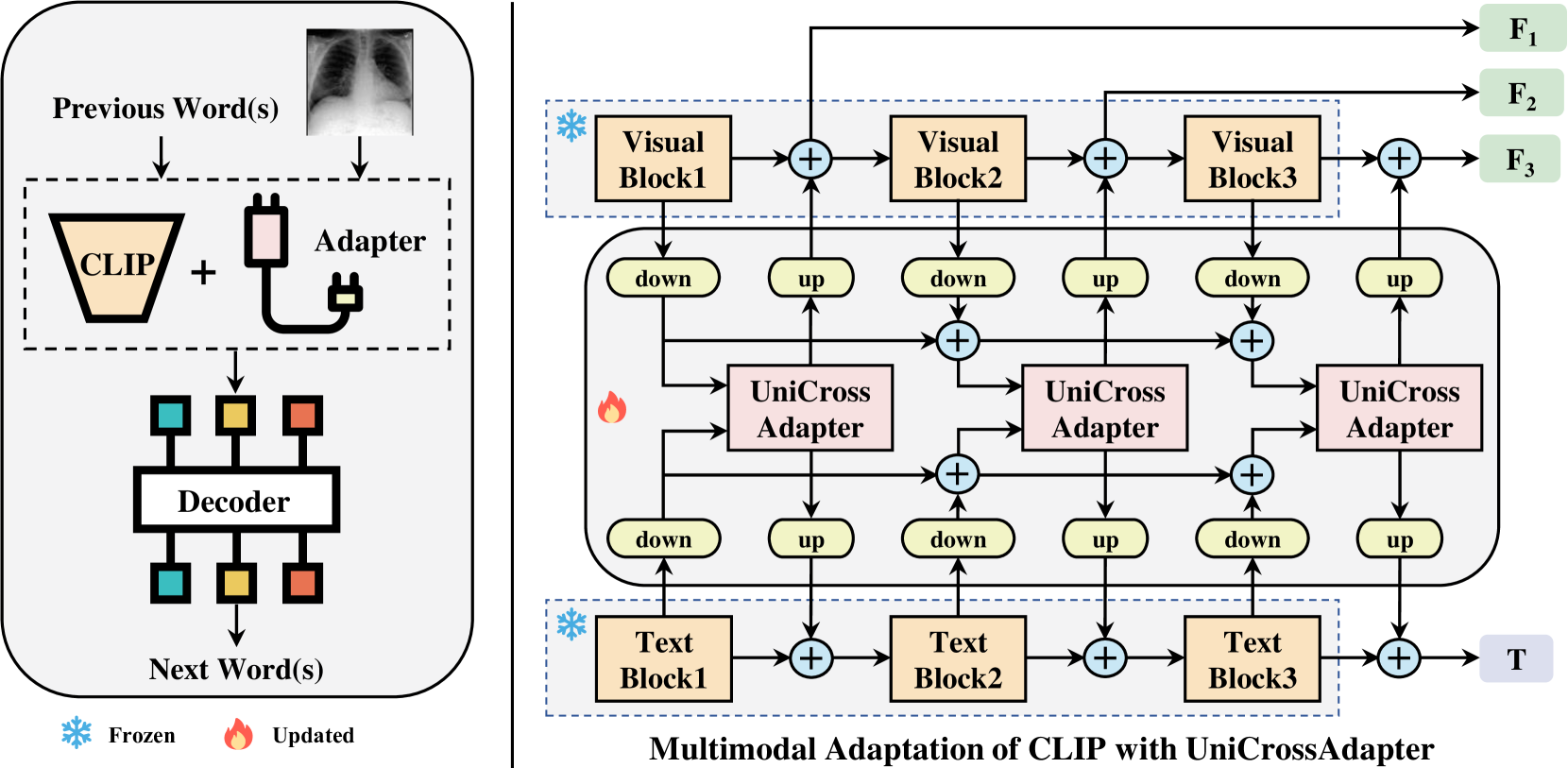
问题定义:放射影像报告生成旨在自动生成放射科医生的报告,但现有方法受限于医学影像数据集的规模,难以充分学习图像和文本之间的关联。直接应用在自然图像上预训练的CLIP模型,由于领域差异,效果不佳。
核心思路:利用CLIP强大的视觉-语言表征能力,通过迁移学习的方式,将其应用于放射影像报告生成任务。核心在于设计一种轻量级的适配器模块,在保持CLIP主体参数不变的情况下,学习特定于医学影像领域的知识,从而缩小领域差距。
技术框架:UniCrossAdapter框架主要包含以下几个部分:首先,使用预训练的CLIP模型作为 backbone,提取图像和文本的特征。然后,将UniCrossAdapter模块插入到CLIP的图像编码器、文本编码器以及跨模态交互模块中。最后,在放射影像报告生成数据集上,固定CLIP的参数,仅训练UniCrossAdapter模块,从而实现高效的领域适应。
关键创新:UniCrossAdapter的关键创新在于其轻量级的设计和在跨模态交互中的应用。传统的微调方法需要更新整个模型的参数,计算量大且容易过拟合。UniCrossAdapter通过引入少量的可训练参数,实现了高效的领域适应。此外,将适配器模块分布在不同的模态及其交互中,能够更好地捕捉图像和文本之间的关联。
关键设计:UniCrossAdapter采用Transformer结构,包含多头自注意力机制和前馈神经网络。在图像编码器和文本编码器中,适配器模块被插入到Transformer层的中间。在跨模态交互模块中,适配器模块被用于学习图像和文本特征之间的对齐关系。损失函数采用交叉熵损失函数,用于优化生成的报告与真实报告之间的相似度。具体参数设置(如适配器模块的层数、隐藏层维度等)需要根据具体数据集进行调整。
🖼️ 关键图片
📊 实验亮点
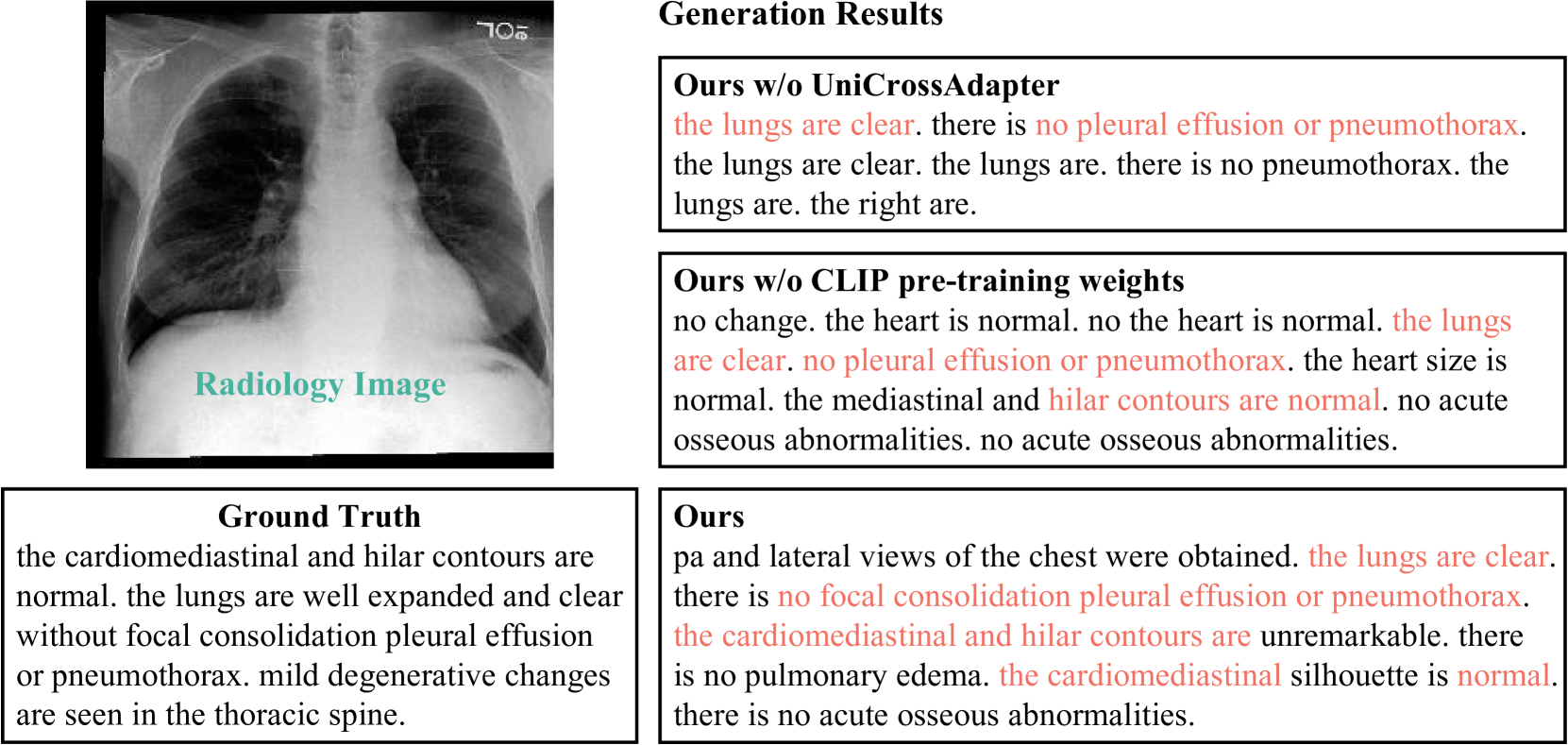
UniCrossAdapter在两个公开的放射影像报告生成数据集上取得了显著的性能提升,超越了现有的state-of-the-art方法。实验结果表明,该方法能够有效地利用CLIP的预训练知识,并适应医学影像领域的特点,从而生成更准确、更全面的报告。
🎯 应用场景
该研究成果可应用于医疗影像辅助诊断领域,帮助放射科医生快速生成报告,提高诊断效率和准确性。未来可扩展到其他医学影像任务,如疾病分类、病灶检测等,具有广阔的应用前景。同时,该方法也为其他数据稀缺的视觉-语言任务提供了借鉴。
📄 摘要(原文)
Automated radiology report generation aims to expedite the tedious and error-prone reporting process for radiologists. While recent works have made progress, learning to align medical images and textual findings remains challenging due to the relative scarcity of labeled medical data. For example, datasets for this task are much smaller than those used for image captioning in computer vision. In this work, we propose to transfer representations from CLIP, a large-scale pre-trained vision-language model, to better capture cross-modal semantics between images and texts. However, directly applying CLIP is suboptimal due to the domain gap between natural images and radiology. To enable efficient adaptation, we introduce UniCrossAdapter, lightweight adapter modules that are incorporated into CLIP and fine-tuned on the target task while keeping base parameters fixed. The adapters are distributed across modalities and their interaction to enhance vision-language alignment. Experiments on two public datasets demonstrate the effectiveness of our approach, advancing state-of-the-art in radiology report generation. The proposed transfer learning framework provides a means of harnessing semantic knowledge from large-scale pre-trained models to tackle data-scarce medical vision-language tasks. Code is available at https://github.com/chauncey-tow/MRG-CLIP.