Jasmine: Harnessing Diffusion Prior for Self-supervised Depth Estimation
作者: Jiyuan Wang, Chunyu Lin, Cheng Guan, Lang Nie, Jing He, Haodong Li, Kang Liao, Yao Zhao
分类: cs.CV, cs.AI
发布日期: 2025-03-20 (更新: 2025-10-19)
备注: Accepted to NeurIPS 2025. 23 pages, with the appendix
💡 一句话要点
Jasmine:利用扩散先验的自监督深度估计框架,提升单目深度估计的清晰度和泛化性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自监督学习 深度估计 Stable Diffusion 视觉先验 单目视觉
📋 核心要点
- 自监督深度估计受限于遮挡、无纹理区域和光照变化等问题,导致预测结果模糊且存在伪影,难以有效利用Stable Diffusion的视觉先验。
- Jasmine通过构建混合图像重建代理任务,在无额外监督下保留Stable Diffusion模型的细节先验,同时避免深度估计性能下降。
- Jasmine引入Scale-Shift GRU,弥合了Stable Diffusion与自监督深度估计之间的尺度和偏移差异,并隔离了重投影损失的干扰,提升了性能。
📝 摘要(中文)
本文提出了Jasmine,这是首个基于Stable Diffusion (SD)的自监督单目深度估计框架。该框架有效地利用了SD的视觉先验,从而增强了无监督预测的清晰度和泛化能力。以往基于SD的方法都是有监督的,因为将扩散模型应用于密集预测需要高精度的监督。相比之下,自监督的重投影方法面临着固有的挑战(例如,遮挡、无纹理区域、光照变化),并且预测结果表现出模糊和伪影,这严重损害了SD的潜在先验。为了解决这个问题,我们构建了一种新颖的混合图像重建代理任务。在没有任何额外监督的情况下,它通过重建图像本身来保留SD模型的细节先验,同时防止深度估计的退化。此外,为了解决SD的尺度和平移不变估计与自监督尺度不变深度估计之间固有的不一致性,我们构建了Scale-Shift GRU。它不仅弥合了这种分布差距,还将SD输出的精细纹理与重投影损失的干扰隔离开来。大量的实验表明,Jasmine在KITTI基准测试上实现了SoTA性能,并在多个数据集上表现出卓越的零样本泛化能力。
🔬 方法详解
问题定义:现有的自监督单目深度估计方法在处理遮挡、无纹理区域和光照变化时,容易产生模糊和伪影,无法充分利用Stable Diffusion等扩散模型的强大视觉先验。直接将扩散模型应用于自监督深度估计会受到重投影误差的干扰,导致性能下降。
核心思路:Jasmine的核心思路是利用Stable Diffusion的视觉先验来提升自监督深度估计的质量。为了克服重投影误差的干扰,论文提出了一种混合图像重建代理任务,该任务在不依赖额外监督的情况下,通过重建图像本身来保留Stable Diffusion的细节先验。同时,为了解决尺度和偏移不一致问题,引入了Scale-Shift GRU。
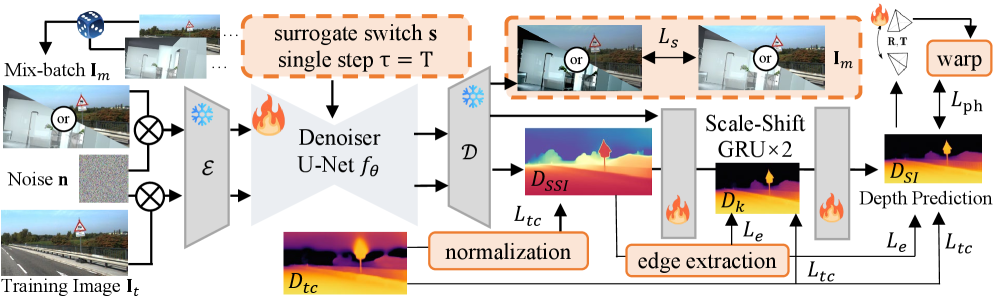
技术框架:Jasmine框架主要包含以下几个模块:1) 深度估计网络:用于预测单目图像的深度图。2) 混合图像重建模块:通过结合原始图像和Stable Diffusion生成的图像,构建代理重建任务。3) Scale-Shift GRU:用于校正Stable Diffusion的尺度和偏移,并隔离重投影损失的干扰。整体流程是:首先使用深度估计网络预测深度图,然后利用深度图进行图像重建,同时利用Stable Diffusion生成图像,构建混合图像重建损失,最后通过Scale-Shift GRU进行校正。
关键创新:Jasmine的关键创新在于:1) 提出了一种混合图像重建代理任务,该任务能够在自监督的框架下有效利用Stable Diffusion的视觉先验。2) 引入了Scale-Shift GRU,解决了Stable Diffusion与自监督深度估计之间的尺度和偏移不一致问题。与现有方法相比,Jasmine能够在不依赖额外监督的情况下,显著提升自监督深度估计的清晰度和泛化能力。
关键设计:混合图像重建损失是关键的设计之一,它结合了原始图像的重建损失和Stable Diffusion生成图像的重建损失,从而在保留细节先验的同时,避免了深度估计的退化。Scale-Shift GRU的设计也至关重要,它通过学习尺度和偏移的变换,弥合了Stable Diffusion与自监督深度估计之间的分布差异。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
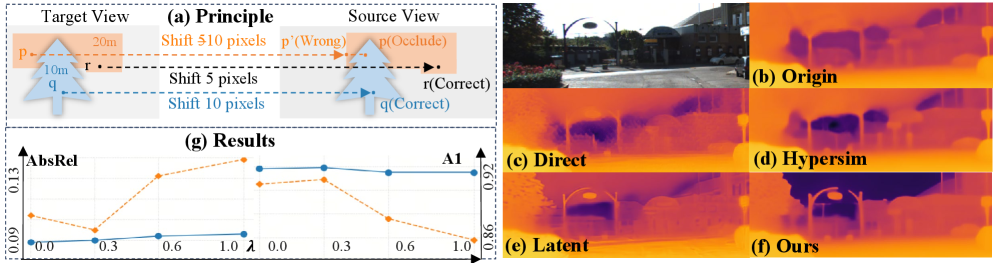
Jasmine在KITTI数据集上取得了SoTA的性能,并且在多个数据集上表现出卓越的零样本泛化能力。实验结果表明,Jasmine能够显著提升自监督深度估计的清晰度和准确性,尤其是在处理遮挡、无纹理区域和光照变化等复杂场景时,优势更加明显。具体的性能数据和对比基线可以在论文的实验部分找到。
🎯 应用场景
Jasmine在自动驾驶、机器人导航、虚拟现实等领域具有广泛的应用前景。高质量的深度估计对于这些应用至关重要,可以帮助系统更好地理解周围环境,从而做出更准确的决策。Jasmine的自监督特性使其能够更容易地应用于各种场景,降低了对标注数据的依赖,具有很高的实际应用价值。
📄 摘要(原文)
In this paper, we propose Jasmine, the first Stable Diffusion (SD)-based self-supervised framework for monocular depth estimation, which effectively harnesses SD's visual priors to enhance the sharpness and generalization of unsupervised prediction. Previous SD-based methods are all supervised since adapting diffusion models for dense prediction requires high-precision supervision. In contrast, self-supervised reprojection suffers from inherent challenges (e.g., occlusions, texture-less regions, illumination variance), and the predictions exhibit blurs and artifacts that severely compromise SD's latent priors. To resolve this, we construct a novel surrogate task of hybrid image reconstruction. Without any additional supervision, it preserves the detail priors of SD models by reconstructing the images themselves while preventing depth estimation from degradation. Furthermore, to address the inherent misalignment between SD's scale and shift invariant estimation and self-supervised scale-invariant depth estimation, we build the Scale-Shift GRU. It not only bridges this distribution gap but also isolates the fine-grained texture of SD output against the interference of reprojection loss. Extensive experiments demonstrate that Jasmine achieves SoTA performance on the KITTI benchmark and exhibits superior zero-shot generalization across multiple datasets.