MASH-VLM: Mitigating Action-Scene Hallucination in Video-LLMs through Disentangled Spatial-Temporal Representations
作者: Kyungho Bae, Jinhyung Kim, Sihaeng Lee, Soonyoung Lee, Gunhee Lee, Jinwoo Choi
分类: cs.CV
发布日期: 2025-03-20
备注: Accepted for CVPR 2025
💡 一句话要点
MASH-VLM通过解耦时空表示缓解视频LLM中的动作-场景幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 动作-场景幻觉 时空解耦 注意力机制 位置编码
📋 核心要点
- 现有Video-LLM混合时空特征,导致动作和场景信息纠缠,产生动作-场景幻觉。
- MASH-VLM通过DST-attention解耦时空token,并使用Harmonic-RoPE平衡时空token的位置信息。
- 在UNSCENE基准测试中,MASH-VLM取得了SOTA结果,并在现有视频理解基准上也有提升。
📝 摘要(中文)
本文旨在解决视频大语言模型(Video-LLM)中存在的动作-场景幻觉问题,即模型基于场景上下文错误地预测动作,或基于观察到的动作错误地预测场景。我们发现,现有的Video-LLM常常由于两个主要因素而遭受动作-场景幻觉:一是通过跨所有token的注意力操作混合了空间和时间特征;二是使用了标准的旋转位置编码(RoPE),导致文本token过度强调某些类型的token,这取决于它们的序列顺序。为了解决这些问题,我们提出了MASH-VLM,即通过解耦时空表示来缓解Video-LLM中的动作-场景幻觉。我们的方法包括两个关键创新:(1) DST-attention,一种新颖的注意力机制,通过使用掩码注意力来限制空间和时间token之间的直接交互,从而在LLM中解耦空间和时间token;(2) Harmonic-RoPE,它扩展了位置ID的维度,允许空间和时间token相对于文本token保持平衡的位置。为了评估Video-LLM中的动作-场景幻觉,我们引入了UNSCENE基准,包含1,320个视频和4,078个QA对。大量的实验表明,MASH-VLM在UNSCENE基准以及现有的视频理解基准上都取得了最先进的结果。
🔬 方法详解
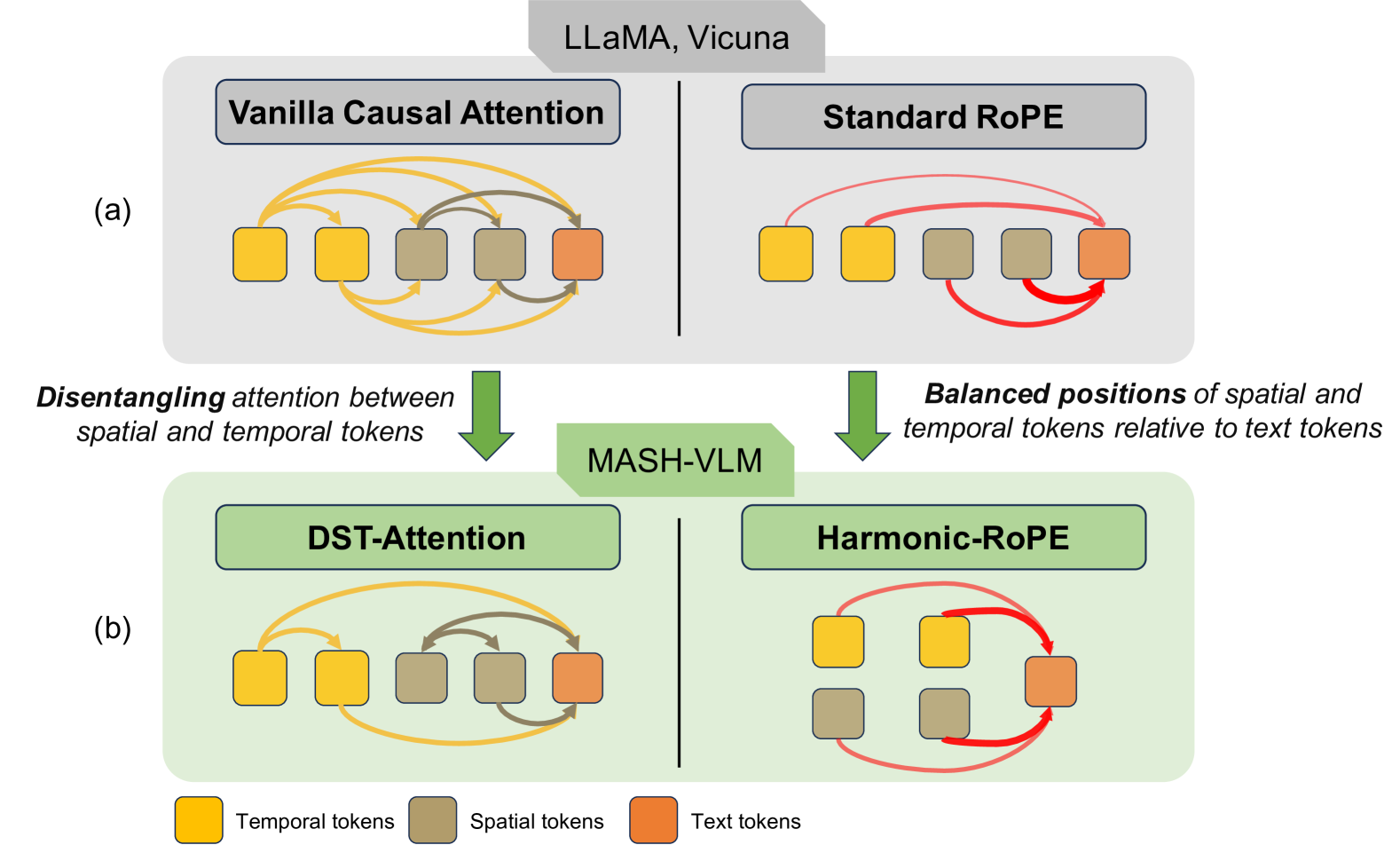
问题定义:论文旨在解决视频大语言模型(Video-LLM)中存在的动作-场景幻觉问题。现有的Video-LLM在理解视频内容时,容易将动作和场景混淆,导致模型错误地预测动作或场景。这种幻觉现象严重影响了Video-LLM的可靠性和实用性。现有方法的痛点在于无法有效区分和处理视频中的空间(场景)和时间(动作)信息,导致二者相互干扰。
核心思路:论文的核心解决思路是通过解耦视频中的空间和时间表示来缓解动作-场景幻觉。具体来说,论文提出了两种关键技术:DST-attention和Harmonic-RoPE。DST-attention通过限制空间和时间token之间的直接交互,从而实现二者的解耦。Harmonic-RoPE则通过扩展位置ID的维度,使得空间和时间token能够相对于文本token保持平衡的位置关系。这样设计的目的是为了让模型能够更准确地理解视频中的动作和场景,从而减少幻觉的产生。
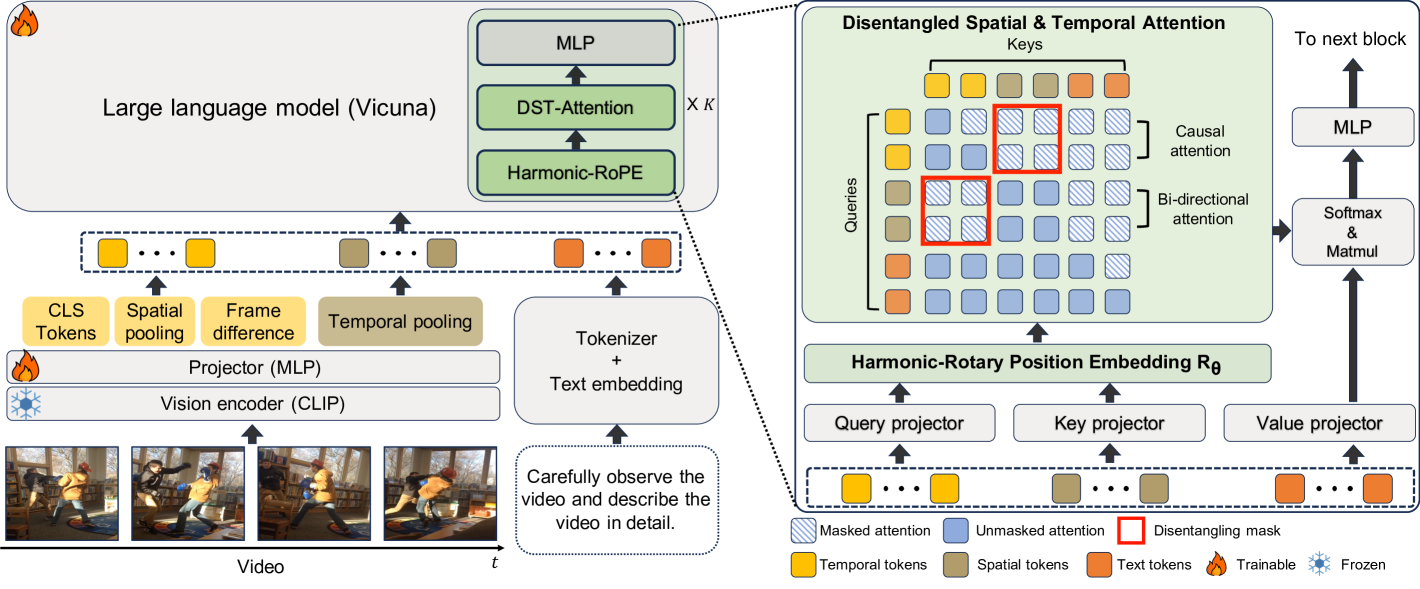
技术框架:MASH-VLM的整体框架基于现有的Video-LLM架构,主要包括视频编码器、LLM以及连接二者的接口。视频编码器负责提取视频帧的特征,LLM负责处理文本信息并进行推理。MASH-VLM的关键在于对LLM内部的注意力机制和位置编码进行了改进,即引入了DST-attention和Harmonic-RoPE。整个流程如下:首先,视频通过视频编码器提取特征;然后,特征被转换为空间和时间token;接着,这些token被输入到经过改进的LLM中,通过DST-attention进行时空解耦,并通过Harmonic-RoPE进行位置编码;最后,LLM输出对视频内容的理解和预测。
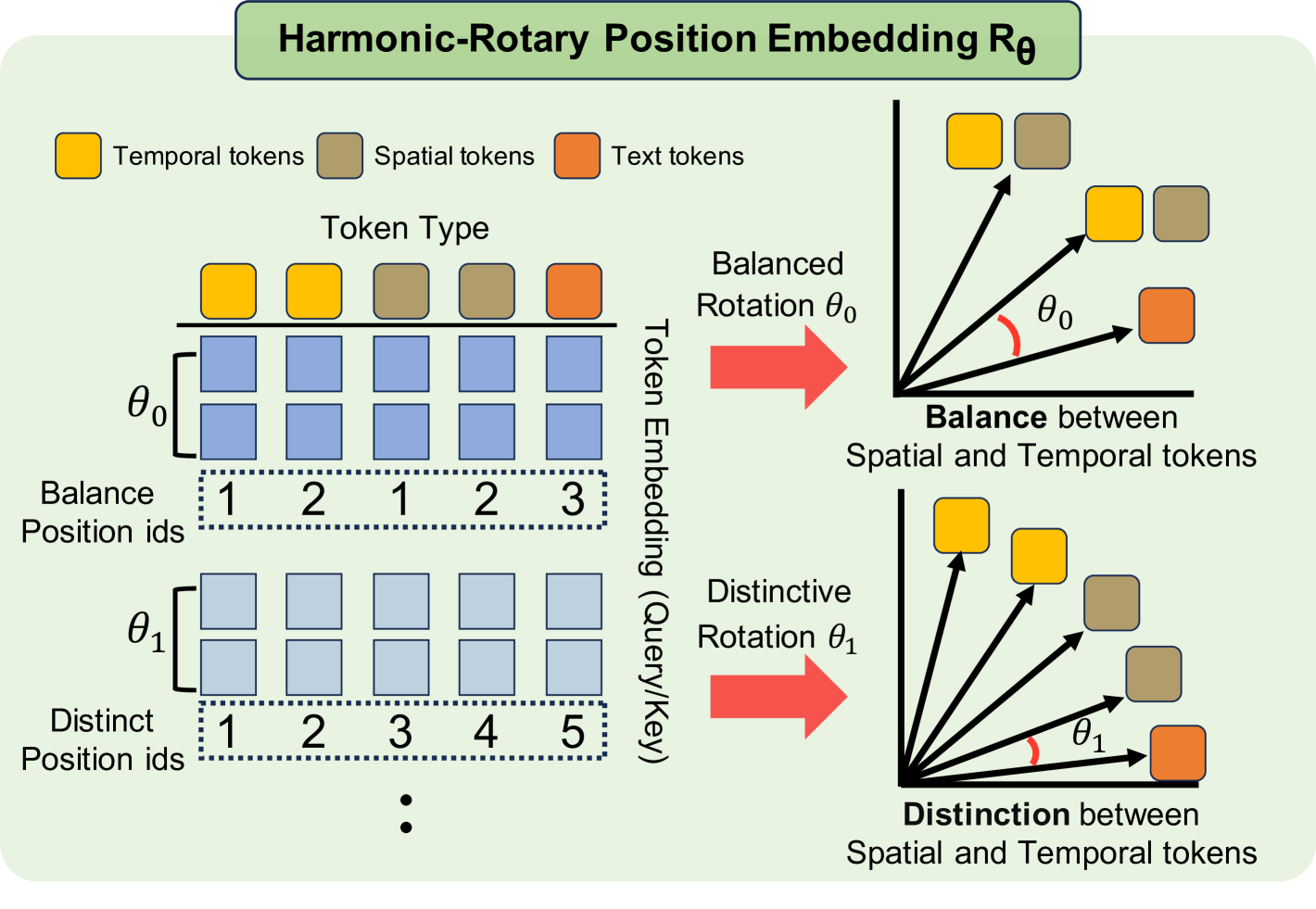
关键创新:MASH-VLM最重要的技术创新点在于DST-attention和Harmonic-RoPE。DST-attention与现有注意力机制的本质区别在于,它通过掩码操作限制了空间和时间token之间的直接交互,从而实现了时空解耦。Harmonic-RoPE与现有位置编码方法的本质区别在于,它扩展了位置ID的维度,使得空间和时间token能够相对于文本token保持平衡的位置关系,避免了某些token被过度强调。
关键设计:DST-attention的关键设计在于掩码矩阵的构建,该矩阵用于控制空间和时间token之间的注意力权重。具体来说,掩码矩阵将空间token和时间token之间的注意力权重设置为0,从而阻止二者之间的直接交互。Harmonic-RoPE的关键设计在于位置ID的扩展方式,论文采用了一种谐波函数来扩展位置ID的维度,使得空间和时间token能够获得不同的位置编码,从而实现二者的区分。论文中没有明确给出具体的参数设置和损失函数,这部分信息未知。
🖼️ 关键图片
📊 实验亮点
MASH-VLM在UNSCENE基准测试中取得了state-of-the-art的结果,显著降低了动作-场景幻觉。此外,MASH-VLM在现有的视频理解基准测试中也取得了有竞争力的结果,表明其具有良好的泛化能力。具体的性能数据和提升幅度在论文中没有明确给出,这部分信息未知。
🎯 应用场景
MASH-VLM的潜在应用领域包括视频内容理解、视频问答、视频摘要、智能监控等。该研究的实际价值在于提高了Video-LLM的可靠性和准确性,使其能够更好地理解和处理视频内容。未来,MASH-VLM可以应用于更复杂的视频分析任务,例如视频编辑、视频生成等,为人们的生活和工作带来便利。
📄 摘要(原文)
In this work, we tackle action-scene hallucination in Video Large Language Models (Video-LLMs), where models incorrectly predict actions based on the scene context or scenes based on observed actions. We observe that existing Video-LLMs often suffer from action-scene hallucination due to two main factors. First, existing Video-LLMs intermingle spatial and temporal features by applying an attention operation across all tokens. Second, they use the standard Rotary Position Embedding (RoPE), which causes the text tokens to overemphasize certain types of tokens depending on their sequential orders. To address these issues, we introduce MASH-VLM, Mitigating Action-Scene Hallucination in Video-LLMs through disentangled spatial-temporal representations. Our approach includes two key innovations: (1) DST-attention, a novel attention mechanism that disentangles the spatial and temporal tokens within the LLM by using masked attention to restrict direct interactions between the spatial and temporal tokens; (2) Harmonic-RoPE, which extends the dimensionality of the positional IDs, allowing the spatial and temporal tokens to maintain balanced positions relative to the text tokens. To evaluate the action-scene hallucination in Video-LLMs, we introduce the UNSCENE benchmark with 1,320 videos and 4,078 QA pairs. Extensive experiments demonstrate that MASH-VLM achieves state-of-the-art results on the UNSCENE benchmark, as well as on existing video understanding benchmarks.