What can Off-the-Shelves Large Multi-Modal Models do for Dynamic Scene Graph Generation?
作者: Xuanming Cui, Jaiminkumar Ashokbhai Bhoi, Chionh Wei Peng, Adriel Kuek, Ser Nam Lim
分类: cs.CV
发布日期: 2025-03-20
💡 一句话要点
利用现成的大型多模态模型解决动态场景图生成问题,实现性能显著提升。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态场景图生成 大型多模态模型 视频理解 序列生成 少量数据微调
📋 核心要点
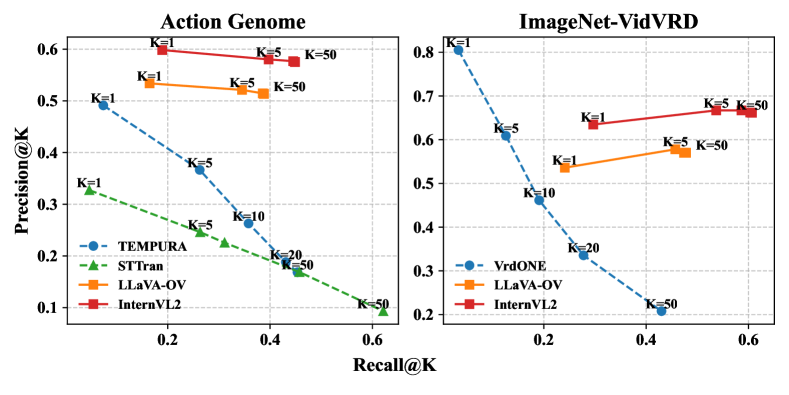
- 现有动态场景图生成方法存在精度-召回率权衡、缺乏三元组重要性感知以及评估协议不当等问题。
- 本文探索了利用预训练的大型多模态模型(LMM)直接进行动态场景图生成,无需复杂架构设计。
- 实验表明,经过少量数据微调的LMM能够显著提升动态场景图生成的性能,达到最先进水平。
📝 摘要(中文)
动态场景图生成(DSGG)是计算机视觉中一项具有挑战性的任务。现有方法通常侧重于复杂的架构设计,并且在评估期间仅使用召回率。本文深入研究了这些方法预测的场景图,发现了现有DSGG方法的三个关键问题:严重的精度-召回率权衡、缺乏对三元组重要性的感知以及不适当的评估协议。另一方面,最近大型多模态模型(LMM)的进展表明其在视频理解方面具有强大的能力,但尚未在像DSGG这样的细粒度、逐帧理解任务上进行测试。本文首次对视频LMM执行DSGG进行了系统的分析。在不依赖复杂架构设计的情况下,结果表明具有简单解码器结构的LMM可以转变为最先进的场景图生成器,有效克服上述问题,同时只需要少量微调(5-10%的训练数据)。
🔬 方法详解
问题定义:动态场景图生成(DSGG)旨在从视频中提取每一帧的场景图,描述视频中实体之间的关系。现有方法通常依赖于复杂的网络结构设计,但存在精度和召回率之间的严重权衡,并且对不同三元组的重要性考虑不足,同时评估指标也存在局限性。这些问题导致现有方法在实际应用中效果不佳。
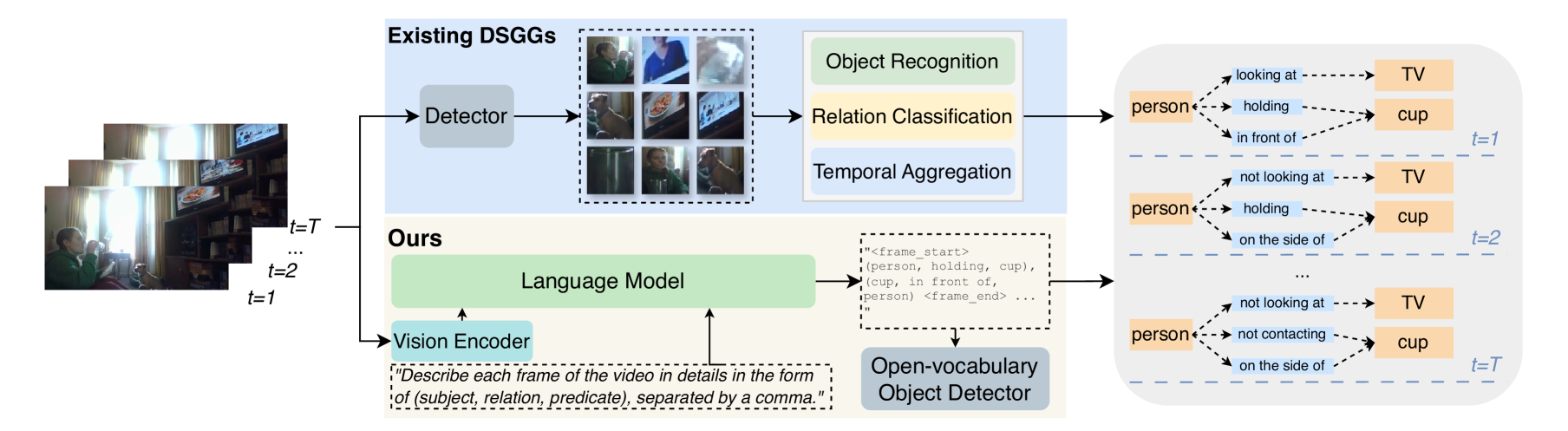
核心思路:本文的核心思路是利用预训练的大型多模态模型(LMM)强大的视频理解能力,直接进行动态场景图的生成。LMM已经在海量数据上进行了预训练,具备了丰富的视觉和语言知识,因此可以更好地理解视频内容,并生成更准确的场景图。通过少量数据微调,LMM可以适应DSGG任务,克服现有方法的不足。
技术框架:本文采用decoder-only结构的LMM作为核心框架。输入是视频帧序列,通过LMM直接生成场景图的三元组(subject, predicate, object)。整个流程可以看作是一个序列生成任务,LMM根据输入的视频帧,逐个生成三元组。在训练阶段,使用交叉熵损失函数来优化LMM的参数,使其能够更准确地预测场景图。
关键创新:本文的关键创新在于首次将大型多模态模型应用于动态场景图生成任务,并证明了LMM在这一任务上的有效性。与现有方法相比,本文的方法不需要复杂的网络结构设计,而是直接利用预训练模型的知识,从而简化了模型的设计和训练过程。此外,本文还指出了现有DSGG方法存在的问题,并提出了相应的解决方案。
关键设计:本文的关键设计在于如何将DSGG任务转化为LMM可以处理的序列生成任务。具体来说,本文将场景图表示为三元组的序列,并使用特殊的token来表示三元组的开始和结束。此外,本文还采用了少量数据微调的策略,以避免LMM在DSGG任务上出现过拟合。损失函数采用标准的交叉熵损失函数,用于衡量模型预测的三元组与真实三元组之间的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过少量数据微调(5-10%训练数据)的LMM在动态场景图生成任务上取得了显著的性能提升,超越了现有的最先进方法。具体性能提升数据未知,但论文强调LMM有效克服了精度-召回率权衡等问题,表明其在生成高质量场景图方面具有优势。
🎯 应用场景
该研究成果可应用于视频监控、自动驾驶、机器人导航等领域。通过生成动态场景图,可以帮助机器更好地理解周围环境,从而做出更智能的决策。例如,在自动驾驶中,可以利用动态场景图来识别车辆、行人和其他交通参与者,并预测它们的行为,从而提高驾驶安全性。在机器人导航中,可以利用动态场景图来构建环境地图,并规划最优路径。
📄 摘要(原文)
Dynamic Scene Graph Generation (DSGG) for videos is a challenging task in computer vision. While existing approaches often focus on sophisticated architectural design and solely use recall during evaluation, we take a closer look at their predicted scene graphs and discover three critical issues with existing DSGG methods: severe precision-recall trade-off, lack of awareness on triplet importance, and inappropriate evaluation protocols. On the other hand, recent advances of Large Multimodal Models (LMMs) have shown great capabilities in video understanding, yet they have not been tested on fine-grained, frame-wise understanding tasks like DSGG. In this work, we conduct the first systematic analysis of Video LMMs for performing DSGG. Without relying on sophisticated architectural design, we show that LMMs with simple decoder-only structure can be turned into State-of-the-Art scene graph generators that effectively overcome the aforementioned issues, while requiring little finetuning (5-10% training data).