GASP: Unifying Geometric and Semantic Self-Supervised Pre-training for Autonomous Driving
作者: William Ljungbergh, Adam Lilja, Adam Tonderski. Arvid Laveno Ling, Carl Lindström, Willem Verbeke, Junsheng Fu, Christoffer Petersson, Lars Hammarstrand, Michael Felsberg
分类: cs.CV, cs.RO
发布日期: 2025-03-19
💡 一句话要点
GASP:面向自动驾驶的几何与语义自监督预训练统一框架
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 自监督学习 几何学习 语义学习 占据预测 时空预测 预训练模型
📋 核心要点
- 现有自动驾驶方法难以有效利用海量的时空数据,缺乏对环境几何和语义结构的统一理解。
- GASP通过预测未来时空点的通用占据、自我占据和视觉基础模型特征,学习环境的统一表征。
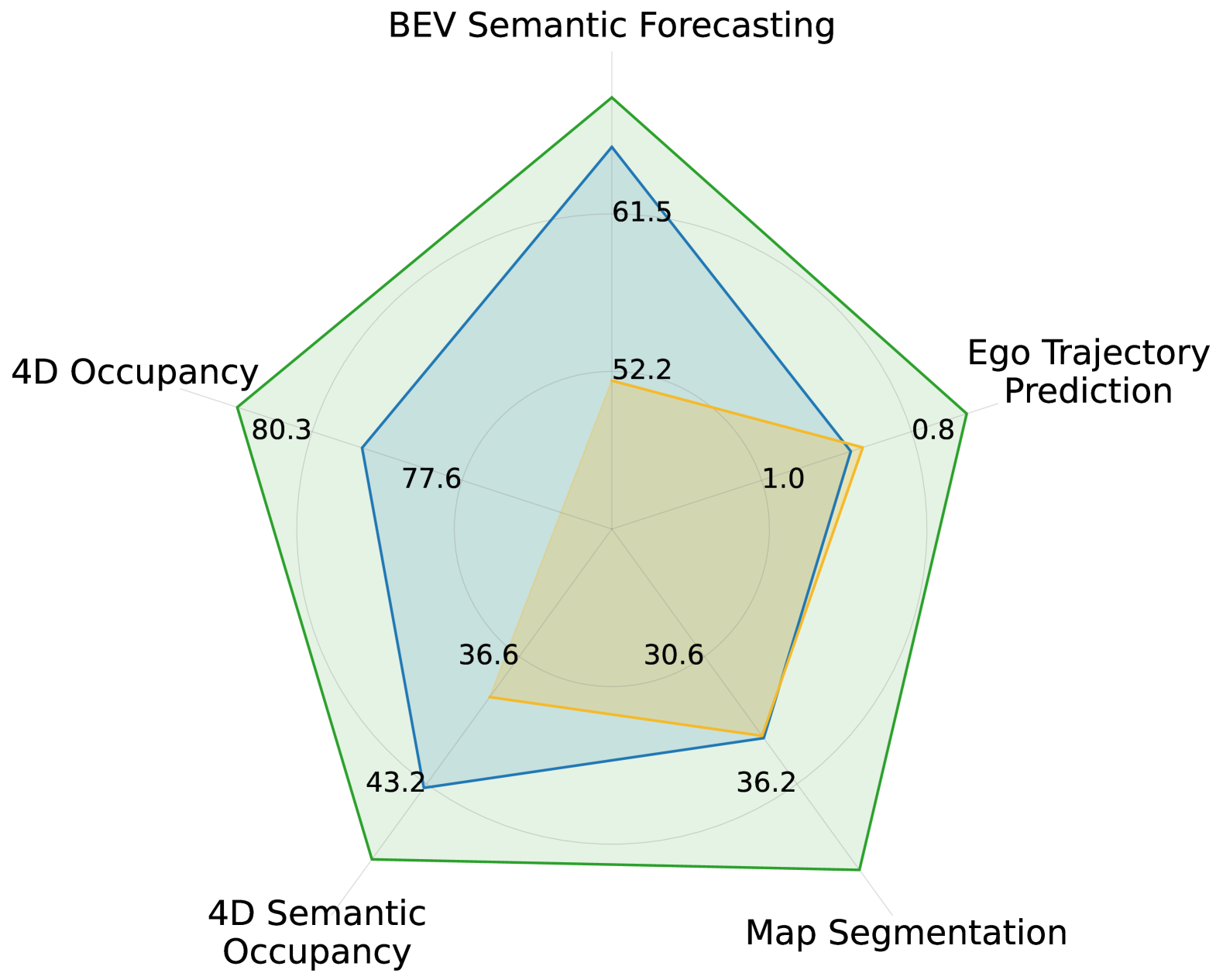
- 实验表明,GASP在语义占据预测、在线地图构建和自我轨迹预测方面均取得了显著提升。
📝 摘要(中文)
本文提出了一种几何和语义自监督预训练方法GASP,旨在学习统一的表征。该方法通过预测时空中的任意查询未来点来完成:(1)通用占据,捕捉3D场景的演变结构;(2)自我占据,建模自我车辆在环境中的路径;(3)从视觉基础模型中提取的精馏高级特征。通过建模几何和语义4D占据场,而非原始传感器测量,模型学习了环境及其随时间演变的结构化、可泛化的表征。在多个自动驾驶基准测试中验证了GASP,结果表明在语义占据预测、在线地图构建和自我轨迹预测方面均有显著改进。证明了连续的4D几何和语义占据预测为自动驾驶提供了一种可扩展且有效的预训练范例。
🔬 方法详解
问题定义:自动驾驶系统需要理解周围环境的几何结构和语义信息,并预测未来的状态。现有的方法通常依赖于大量的标注数据,或者难以将几何和语义信息有效地结合起来。此外,如何利用自动驾驶场景中海量的时空数据进行有效的自监督学习也是一个挑战。
核心思路:GASP的核心思路是通过自监督学习的方式,让模型学习预测未来时空点的占据情况和语义信息。具体来说,模型需要预测在给定的过去状态下,未来某个时空点的通用占据(场景结构)、自我占据(车辆轨迹)以及从视觉基础模型中提取的语义特征。通过这种方式,模型可以学习到环境的几何和语义结构,以及它们随时间的变化规律。
技术框架:GASP的整体框架包含以下几个主要模块:1)输入模块:接收来自传感器(如激光雷达、摄像头)的历史数据;2)编码器:将历史数据编码成一个高维的特征表示;3)预测模块:根据编码后的特征,预测未来时空点的通用占据、自我占据和语义特征;4)损失函数:计算预测结果与真实值之间的差异,用于训练模型。整个流程可以看作是一个时空预测任务,模型通过不断地预测未来状态来学习环境的动态变化。
关键创新:GASP的关键创新在于它将几何和语义信息统一到一个自监督学习框架中。与以往的方法相比,GASP不需要大量的标注数据,而是通过预测未来状态来学习环境的结构和动态变化。此外,GASP还利用了视觉基础模型提取的语义特征,从而提高了模型的语义理解能力。通过建模4D占据场,GASP能够更好地捕捉环境的时空信息。
关键设计:GASP的关键设计包括:1)使用体素网格来表示3D空间,并对每个体素进行占据预测;2)使用Transformer网络来建模时序依赖关系;3)使用多任务学习的方式,同时预测通用占据、自我占据和语义特征;4)设计了专门的损失函数来平衡不同任务之间的权重。具体的网络结构和参数设置未知,需要参考论文原文。
🖼️ 关键图片

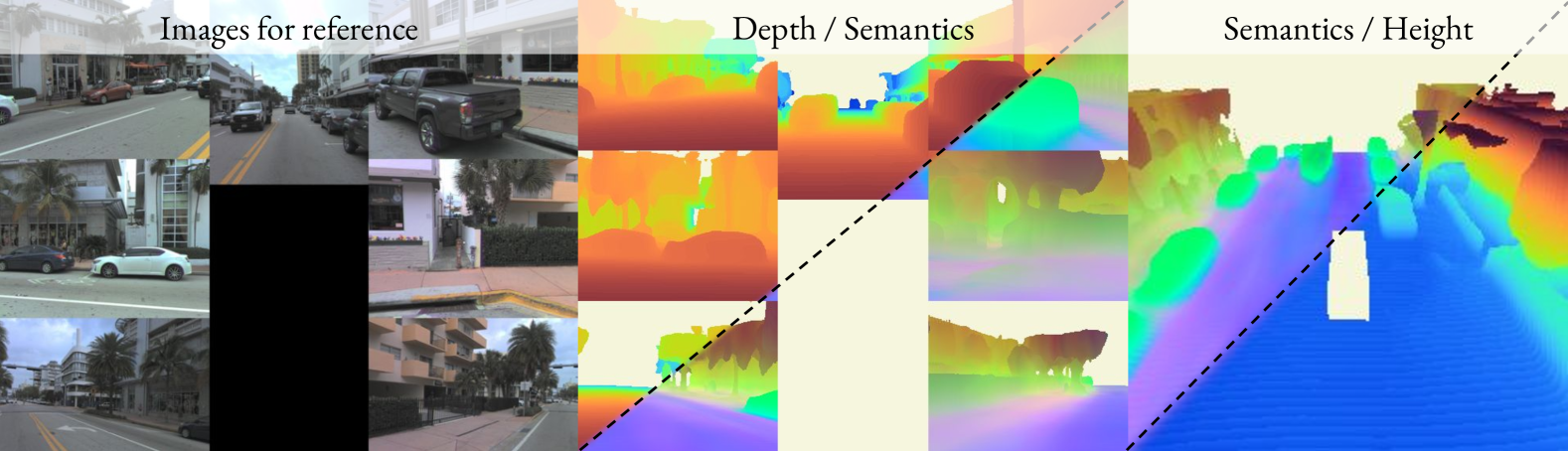
📊 实验亮点
GASP在多个自动驾驶基准测试中取得了显著的改进。具体来说,在语义占据预测任务中,GASP的性能优于现有的方法。此外,GASP还在在线地图构建和自我轨迹预测方面取得了不错的成绩。这些结果表明,GASP是一种有效的自监督预训练方法,可以提高自动驾驶系统的性能。
🎯 应用场景
GASP的潜在应用领域包括自动驾驶、机器人导航、增强现实等。通过学习环境的几何和语义结构,GASP可以帮助自动驾驶系统更好地理解周围环境,提高感知和决策能力。此外,GASP还可以用于构建高精度的地图,为自动驾驶系统提供更可靠的导航信息。该研究的未来影响在于推动自动驾驶技术的进一步发展,提高交通安全和效率。
📄 摘要(原文)
Self-supervised pre-training based on next-token prediction has enabled large language models to capture the underlying structure of text, and has led to unprecedented performance on a large array of tasks when applied at scale. Similarly, autonomous driving generates vast amounts of spatiotemporal data, alluding to the possibility of harnessing scale to learn the underlying geometric and semantic structure of the environment and its evolution over time. In this direction, we propose a geometric and semantic self-supervised pre-training method, GASP, that learns a unified representation by predicting, at any queried future point in spacetime, (1) general occupancy, capturing the evolving structure of the 3D scene; (2) ego occupancy, modeling the ego vehicle path through the environment; and (3) distilled high-level features from a vision foundation model. By modeling geometric and semantic 4D occupancy fields instead of raw sensor measurements, the model learns a structured, generalizable representation of the environment and its evolution through time. We validate GASP on multiple autonomous driving benchmarks, demonstrating significant improvements in semantic occupancy forecasting, online mapping, and ego trajectory prediction. Our results demonstrate that continuous 4D geometric and semantic occupancy prediction provides a scalable and effective pre-training paradigm for autonomous driving. For code and additional visualizations, see \href{https://research.zenseact.com/publications/gasp/.