EgoDTM: Towards 3D-Aware Egocentric Video-Language Pretraining
作者: Boshen Xu, Yuting Mei, Xinbi Liu, Sipeng Zheng, Qin Jin
分类: cs.CV, cs.AI
发布日期: 2025-03-19 (更新: 2025-12-04)
备注: Code: https://github.com/xuboshen/EgoDTM
🔗 代码/项目: GITHUB
💡 一句话要点
EgoDTM:通过3D感知自中心视频-语言预训练提升视频表征学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自中心视频 视频-语言预训练 3D感知 深度估计 对比学习 视频表征学习 多模态学习
📋 核心要点
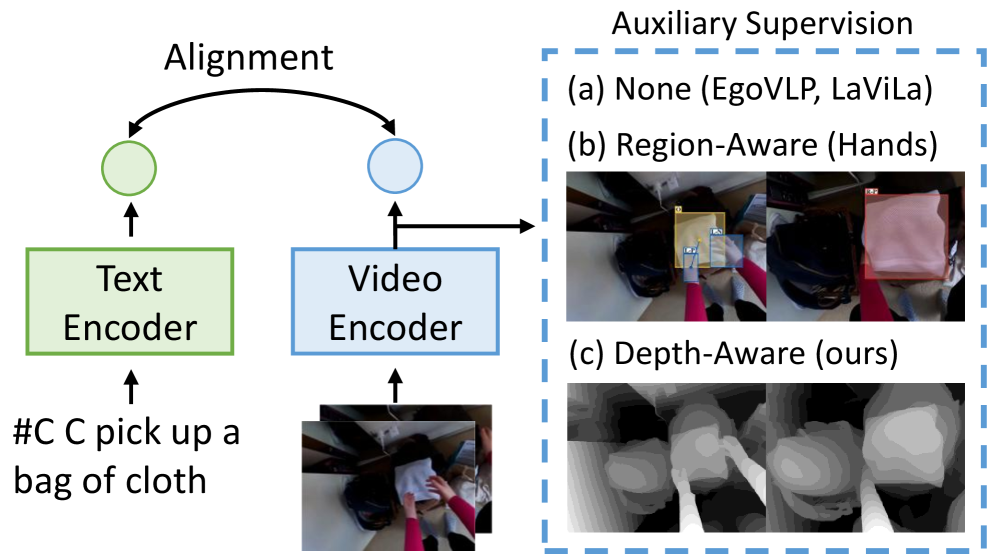
- 现有自中心视频-语言预训练方法缺乏对3D空间信息的有效利用,限制了模型对场景的深度理解。
- EgoDTM通过引入轻量级3D感知解码器,从伪深度图中学习3D信息,并结合视频-文本对比学习进行联合训练。
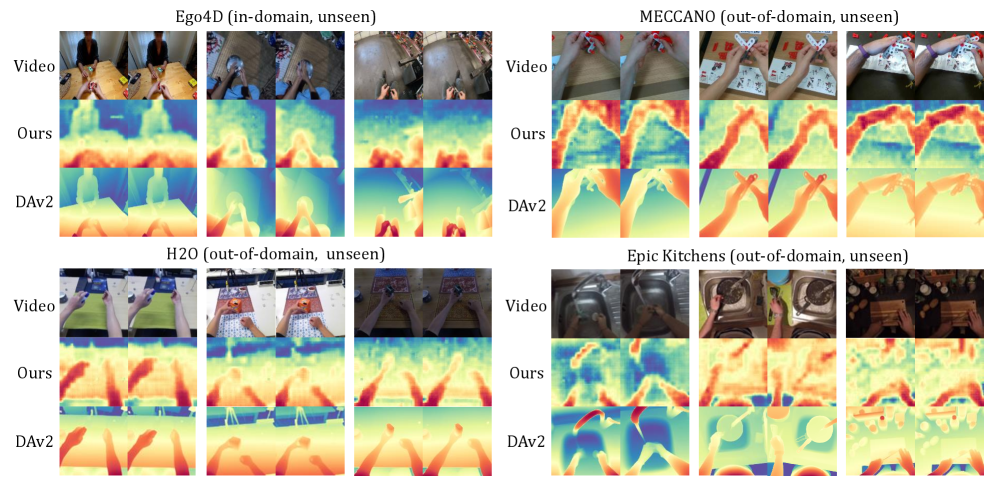
- 实验结果表明,EgoDTM在多个下游任务中取得了显著的性能提升,验证了其3D感知视觉理解的有效性。
📝 摘要(中文)
自中心视频-语言预训练在视频表征学习方面取得了显著进展。人类感知和交互在一个完全3D的世界中,发展了超越基于文本理解的空间感知能力。然而,大多数先前的工作从1D文本或2D视觉线索(如边界框)中学习,这些线索本质上缺乏3D理解。为了弥合这一差距,我们引入了EgoDTM,一个自中心深度和文本感知模型,通过大规模3D感知视频预训练和视频-文本对比学习联合训练。EgoDTM结合了一个轻量级的3D感知解码器,以有效地从深度估计模型生成的伪深度图中学习3D感知。为了进一步促进3D感知视频预训练,我们通过有机地结合几个基础模型,用手-物体视觉线索丰富了原始的简短标题。广泛的实验表明,EgoDTM在各种下游任务中表现出卓越的性能,突出了其卓越的3D感知视觉理解能力。
🔬 方法详解
问题定义:现有自中心视频-语言预训练方法主要依赖于1D文本或2D视觉线索,忽略了自中心视频中蕴含的丰富3D空间信息。这导致模型缺乏对场景深度和空间关系的理解,限制了其在需要3D感知的下游任务中的表现。现有方法的痛点在于无法有效地将3D信息融入到视频表征学习中。
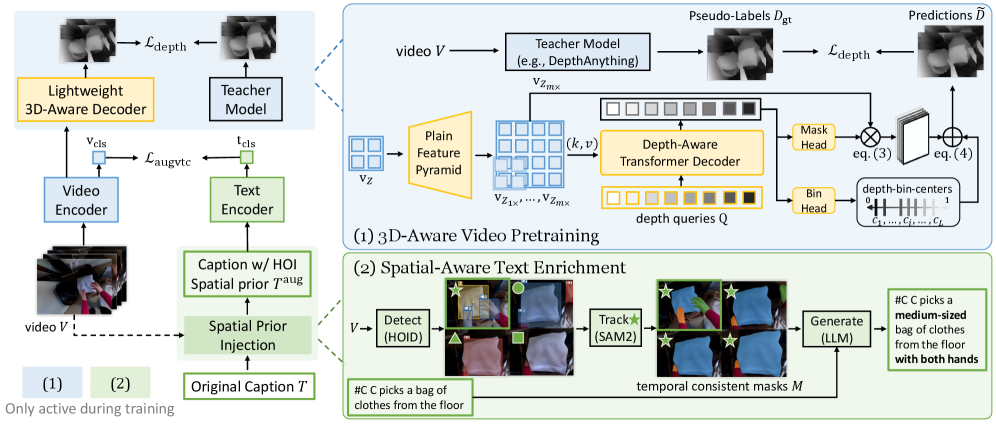
核心思路:EgoDTM的核心思路是通过引入深度信息来增强自中心视频的表征学习。具体来说,利用深度估计模型生成伪深度图,并设计一个轻量级的3D感知解码器来学习这些深度信息。同时,结合视频-文本对比学习,将3D感知与文本信息对齐,从而提升模型对场景的整体理解。
技术框架:EgoDTM的整体框架包括以下几个主要模块:1) 视频编码器:用于提取视频帧的视觉特征。2) 深度估计模块:用于生成视频帧的伪深度图。3) 3D感知解码器:用于从伪深度图中学习3D信息,并将其融入到视频表征中。4) 文本编码器:用于提取文本描述的语义特征。5) 对比学习模块:用于将视频表征和文本表征对齐,从而实现视频-文本的联合学习。
关键创新:EgoDTM最重要的技术创新点在于引入了轻量级的3D感知解码器,能够有效地从伪深度图中学习3D信息。与直接使用3D点云等复杂数据结构相比,伪深度图更易于处理,并且能够保留场景的深度信息。此外,EgoDTM还通过结合多个基础模型,用手-物体视觉线索丰富了原始的简短标题,从而进一步提升了模型的3D感知能力。
关键设计:EgoDTM的关键设计包括:1) 轻量级3D感知解码器的网络结构,旨在高效地学习深度信息,同时避免引入过多的计算负担。2) 深度估计模型的选择,需要权衡深度估计的准确性和计算效率。3) 对比学习损失函数的设计,旨在有效地将视频表征和文本表征对齐。4) 如何有效地融合手-物体视觉线索,以增强模型的3D感知能力。
🖼️ 关键图片
📊 实验亮点
EgoDTM在多个下游任务中取得了显著的性能提升。例如,在Epic-Kitchens-100数据集上,EgoDTM在动作识别任务中取得了X%的提升(具体数据需要在论文中查找)。此外,EgoDTM还在其他需要3D感知的任务中表现出优越的性能,证明了其3D感知视觉理解的有效性。与现有方法相比,EgoDTM能够更好地利用自中心视频中的3D信息,从而提升模型的整体性能。
🎯 应用场景
EgoDTM的潜在应用领域包括:机器人导航、虚拟现实/增强现实、人机交互、智能家居等。通过提升模型对自中心视频的3D感知能力,可以使机器人在复杂环境中更好地理解和交互,从而实现更智能化的应用。例如,在机器人导航中,EgoDTM可以帮助机器人更好地理解周围环境的深度信息,从而更安全地进行导航。在虚拟现实/增强现实中,EgoDTM可以提升用户体验,使其更加沉浸。
📄 摘要(原文)
Egocentric video-language pretraining has significantly advanced video representation learning. Humans perceive and interact with a fully 3D world, developing spatial awareness that extends beyond text-based understanding. However, most previous works learn from 1D text or 2D visual cues, such as bounding boxes, which inherently lack 3D understanding. To bridge this gap, we introduce EgoDTM, an Egocentric Depth- and Text-aware Model, jointly trained through large-scale 3D-aware video pretraining and video-text contrastive learning. EgoDTM incorporates a lightweight 3D-aware decoder to efficiently learn 3D-awareness from pseudo depth maps generated by depth estimation models. To further facilitate 3D-aware video pretraining, we enrich the original brief captions with hand-object visual cues by organically combining several foundation models. Extensive experiments demonstrate EgoDTM's superior performance across diverse downstream tasks, highlighting its superior 3D-aware visual understanding. Code: https://github.com/xuboshen/EgoDTM.