DiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
作者: Jiazhe Guo, Yikang Ding, Xiwu Chen, Shuo Chen, Bohan Li, Yingshuang Zou, Xiaoyang Lyu, Feiyang Tan, Xiaojuan Qi, Zhiheng Li, Hao Zhao
分类: cs.CV
发布日期: 2025-03-19
💡 一句话要点
提出DiST-4D,用于生成具有度量深度信息的解耦时空扩散4D驾驶场景
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 4D场景生成 时空扩散模型 度量深度 新视角合成 自动驾驶仿真
📋 核心要点
- 现有生成模型难以合成支持时序外推和空间新视角合成的动态4D驾驶场景,缺乏有效的几何表示是关键挑战。
- DiST-4D利用度量深度作为核心几何表示,解耦时空扩散过程,分别处理时序预测和空间新视角合成。
- 实验结果表明,DiST-4D在时序预测和新视角合成任务中均取得了领先性能,并在规划相关评估中表现出色。
📝 摘要(中文)
本文提出DiST-4D,一种用于生成动态4D驾驶场景的解耦时空扩散框架,该框架无需针对每个场景进行优化,即可同时支持时间外推和空间新视角合成(NVS)。核心挑战在于找到一种高效且泛化的几何表示,以无缝连接时间和空间合成。DiST-4D利用度量深度作为核心几何表示,将问题分解为两个扩散过程:DiST-T直接从过去的观测预测未来的度量深度和多视角RGB序列;DiST-S仅在现有视角上训练,并通过强制循环一致性来实现空间NVS。这种循环一致性机制引入了前向-后向渲染约束,减少了观测视角和未观测视角之间的泛化差距。度量深度对于准确可靠的预测和精确的空间NVS至关重要,因为它提供了一种视角一致的几何表示,可以很好地推广到未见过的视角。实验表明,DiST-4D在时间预测和NVS任务中均实现了最先进的性能,同时在与规划相关的评估中也提供了具有竞争力的性能。
🔬 方法详解
问题定义:现有方法在生成动态4D驾驶场景时,难以同时保证时序外推和空间新视角合成的质量,通常需要针对每个场景进行优化,泛化能力较差。核心痛点在于缺乏一种能够有效连接时间和空间信息,并且具有良好泛化性的几何表示。
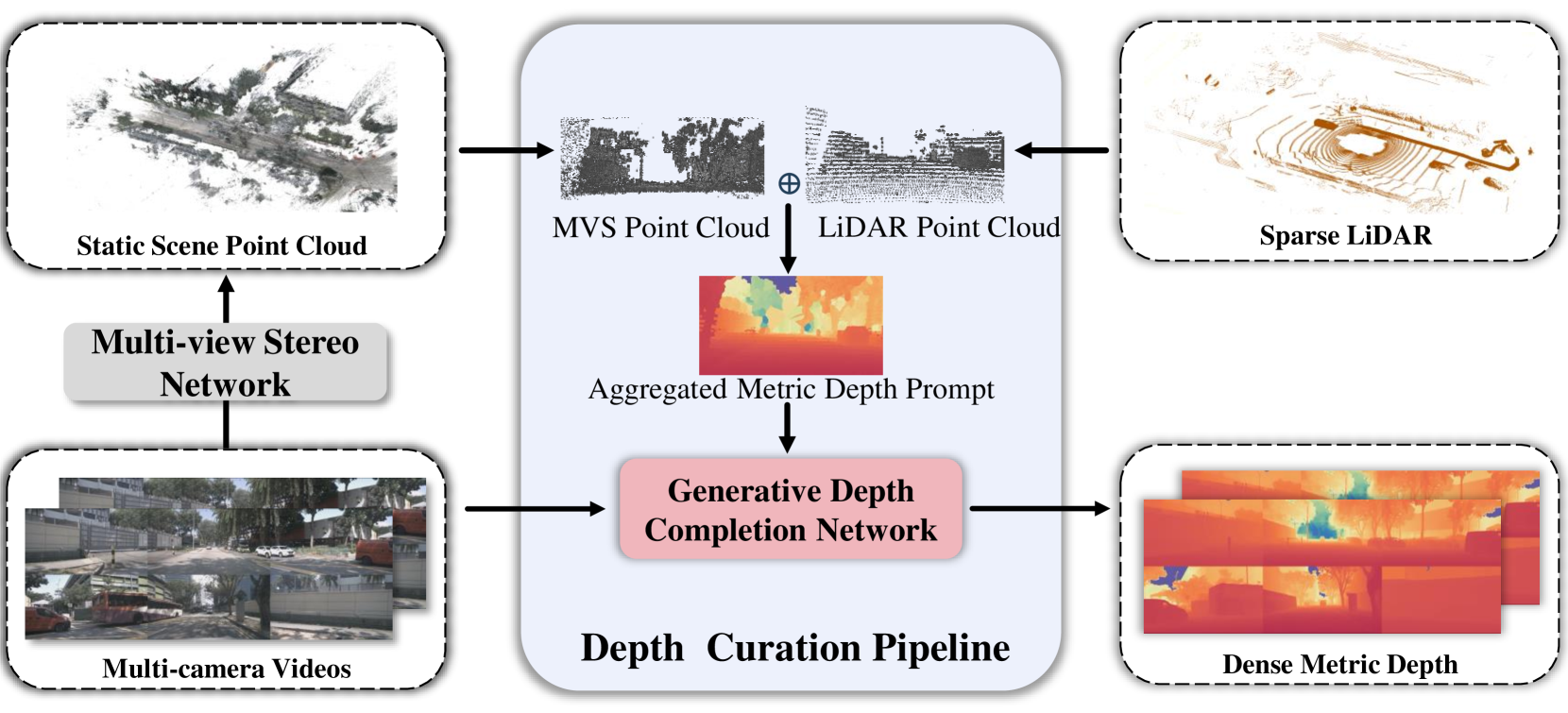
核心思路:DiST-4D的核心思路是将4D驾驶场景生成问题分解为时序预测和空间新视角合成两个解耦的扩散过程,并利用度量深度作为连接这两个过程的关键几何表示。度量深度具有视角一致性,能够很好地泛化到未见过的视角,从而提高新视角合成的质量。
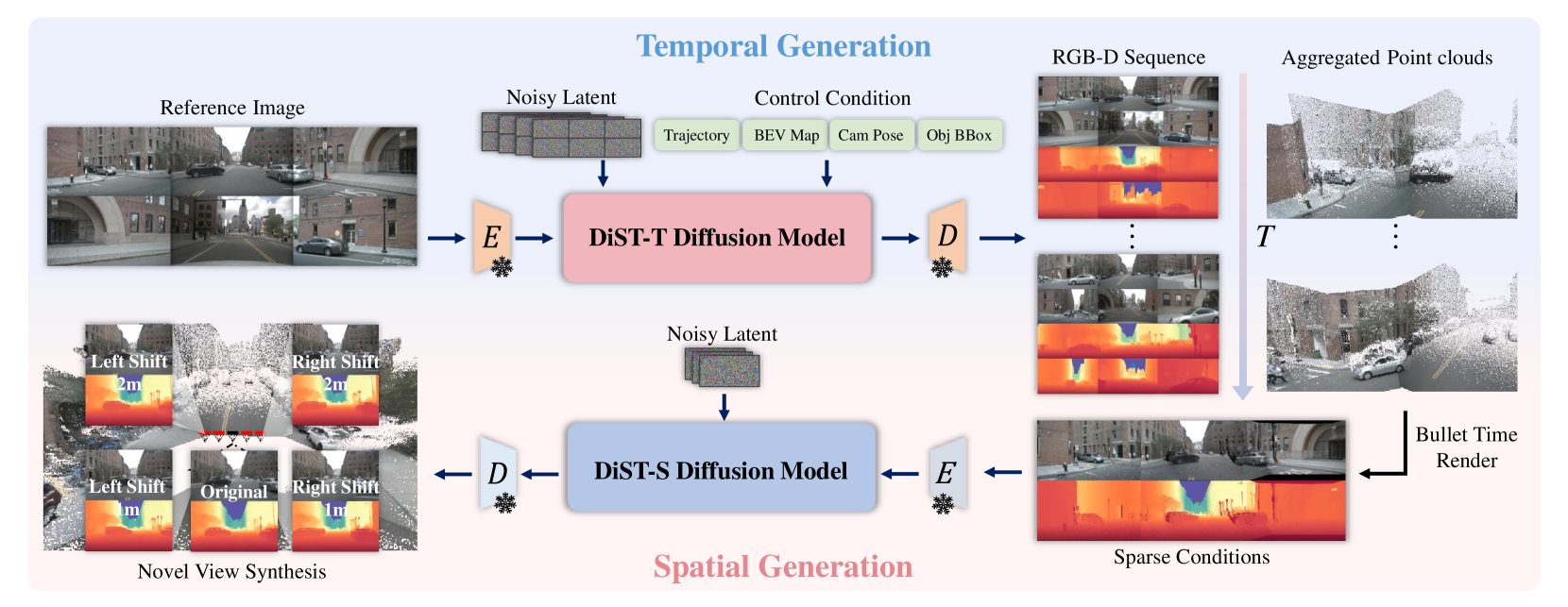
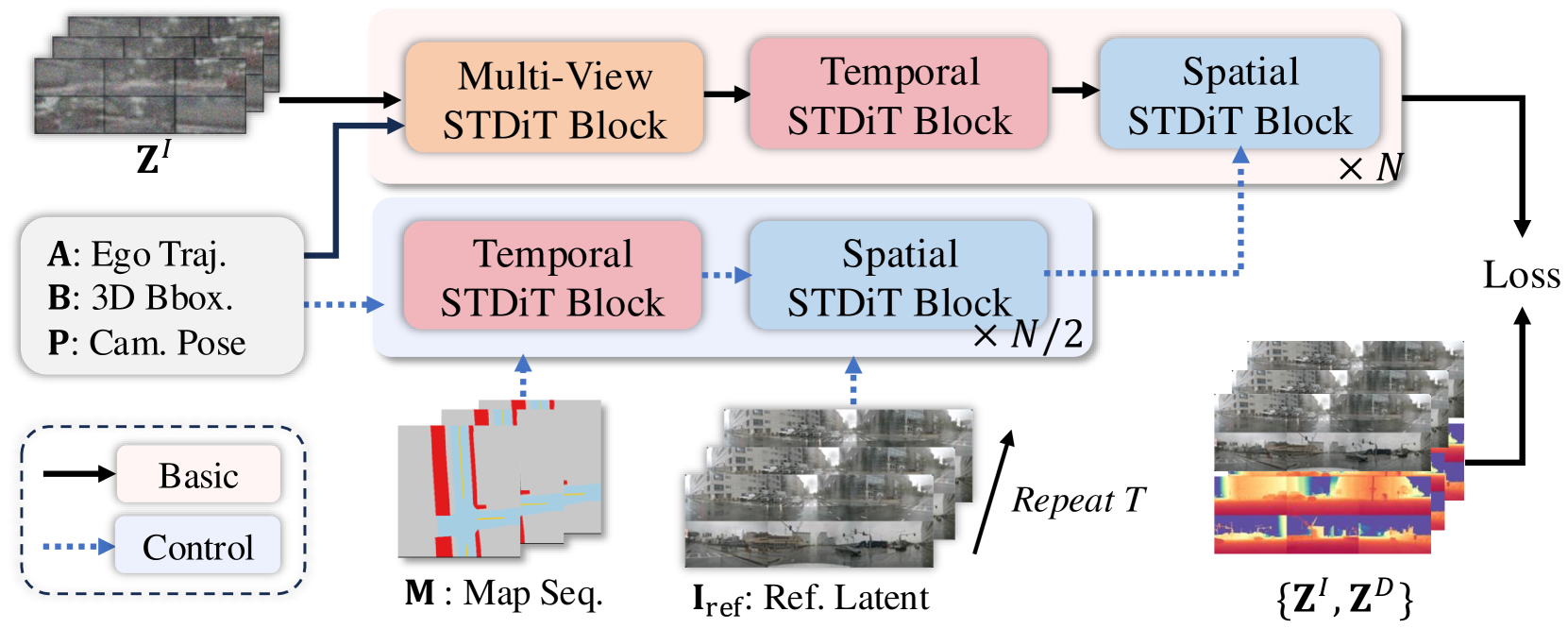
技术框架:DiST-4D框架包含两个主要的扩散过程:DiST-T和DiST-S。DiST-T负责从过去的观测数据预测未来的度量深度和多视角RGB序列,实现时序外推。DiST-S负责利用现有的视角信息进行空间新视角合成,并通过循环一致性约束来提高合成质量。整体流程是先通过DiST-T预测未来场景的度量深度和RGB序列,然后利用DiST-S进行新视角的合成。
关键创新:DiST-4D的关键创新在于提出了一个解耦的时空扩散框架,并利用度量深度作为连接时间和空间信息的桥梁。通过解耦时空过程,可以分别优化时序预测和空间合成,从而提高整体生成质量。循环一致性约束的引入,进一步减少了观测视角和未观测视角之间的泛化差距。
关键设计:DiST-T和DiST-S均采用扩散模型作为生成器,具体网络结构未知。循环一致性约束通过前向渲染和后向渲染来实现,具体损失函数未知。度量深度的预测可能采用了特定的损失函数来保证其准确性和视角一致性,具体细节未知。
🖼️ 关键图片
📊 实验亮点
DiST-4D在时间预测和新视角合成任务中均取得了state-of-the-art的性能,具体指标未知。同时,在与规划相关的评估中也表现出了具有竞争力的性能,表明生成的场景具有较高的真实性和可用性。相较于现有方法,DiST-4D无需针对每个场景进行优化,具有更好的泛化能力。
🎯 应用场景
DiST-4D可应用于自动驾驶仿真、虚拟现实场景生成、游戏开发等领域。通过生成逼真的动态驾驶场景,可以为自动驾驶算法的训练和测试提供高质量的数据,加速自动驾驶技术的研发。此外,该技术还可以用于创建沉浸式的虚拟现实体验,例如驾驶模拟器和虚拟旅游。
📄 摘要(原文)
Current generative models struggle to synthesize dynamic 4D driving scenes that simultaneously support temporal extrapolation and spatial novel view synthesis (NVS) without per-scene optimization. A key challenge lies in finding an efficient and generalizable geometric representation that seamlessly connects temporal and spatial synthesis. To address this, we propose DiST-4D, the first disentangled spatiotemporal diffusion framework for 4D driving scene generation, which leverages metric depth as the core geometric representation. DiST-4D decomposes the problem into two diffusion processes: DiST-T, which predicts future metric depth and multi-view RGB sequences directly from past observations, and DiST-S, which enables spatial NVS by training only on existing viewpoints while enforcing cycle consistency. This cycle consistency mechanism introduces a forward-backward rendering constraint, reducing the generalization gap between observed and unseen viewpoints. Metric depth is essential for both accurate reliable forecasting and accurate spatial NVS, as it provides a view-consistent geometric representation that generalizes well to unseen perspectives. Experiments demonstrate that DiST-4D achieves state-of-the-art performance in both temporal prediction and NVS tasks, while also delivering competitive performance in planning-related evaluations.