Forensics-Bench: A Comprehensive Forgery Detection Benchmark Suite for Large Vision Language Models
作者: Jin Wang, Chenghui Lv, Xian Li, Shichao Dong, Huadong Li, kelu Yao, Chao Li, Wenqi Shao, Ping Luo
分类: cs.CV
发布日期: 2025-03-19 (更新: 2025-03-23)
备注: 31 pages, 19 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Forensics-Bench,用于全面评估大型视觉语言模型在伪造检测中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 伪造检测 大型视觉语言模型 基准测试 多模态学习 AIGC 视觉推理 图像篡改 虚假信息
📋 核心要点
- 现有方法难以全面评估大型视觉语言模型(LVLM)在各种伪造检测任务中的辨别能力,缺乏统一的评测标准。
- 提出Forensics-Bench基准测试套件,包含63292个多项选择题,覆盖112种伪造类型,从多个角度评估LVLM的伪造检测能力。
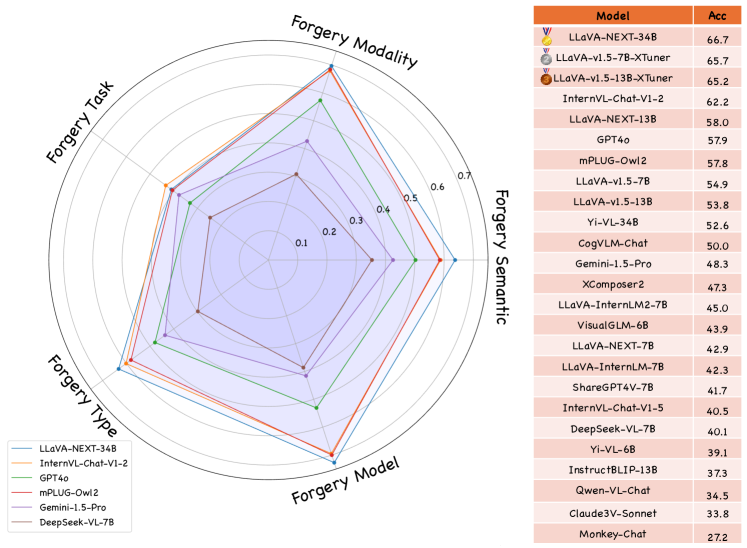
- 在22个开源LVLM和3个专有模型上进行了评估,结果表明现有LVLM在全面伪造检测方面仍面临重大挑战。
📝 摘要(中文)
近年来,AIGC的快速发展显著增加了互联网上虚假媒体的多样性,对社会安全、政治、法律等构成前所未有的威胁。为了检测AIGC时代日益增长的恶意虚假媒体,最近的研究提出利用大型视觉语言模型(LVLM)设计鲁棒的伪造检测器,因为它们在各种多模态任务上表现出色。然而,目前仍然缺乏一个全面的基准,用于全面评估LVLM在伪造媒体上的辨别能力。为了填补这一空白,我们提出了Forensics-Bench,一个新的伪造检测评估基准套件,用于评估LVLM在大量伪造检测任务中的能力,需要对各种伪造品进行全面的识别、定位和推理。Forensics-Bench包含63292个精心策划的多项选择视觉问题,涵盖来自5个角度的112种独特的伪造检测类型:伪造语义、伪造模态、伪造任务、伪造类型和伪造模型。我们对22个开源LVLM和3个专有模型GPT-4o、Gemini 1.5 Pro和Claude 3.5 Sonnet进行了彻底的评估,突出了Forensics-Bench提出的全面伪造检测的重大挑战。我们预计Forensics-Bench将激励社区推进LVLM的前沿,努力在AIGC时代实现全方位的伪造检测器。相关资源将在https://Forensics-Bench.github.io/上更新。
🔬 方法详解
问题定义:论文旨在解决缺乏全面、系统的基准来评估大型视觉语言模型(LVLM)在伪造检测任务中的能力的问题。现有方法无法有效衡量LVLM在识别、定位和推理各种伪造媒体方面的性能,阻碍了该领域的发展。
核心思路:论文的核心思路是构建一个包含大量多样化伪造检测任务的基准测试套件,从而全面评估LVLM的性能。通过涵盖不同的伪造语义、模态、任务、类型和模型,该基准旨在揭示LVLM在处理复杂伪造场景时的优势和不足。
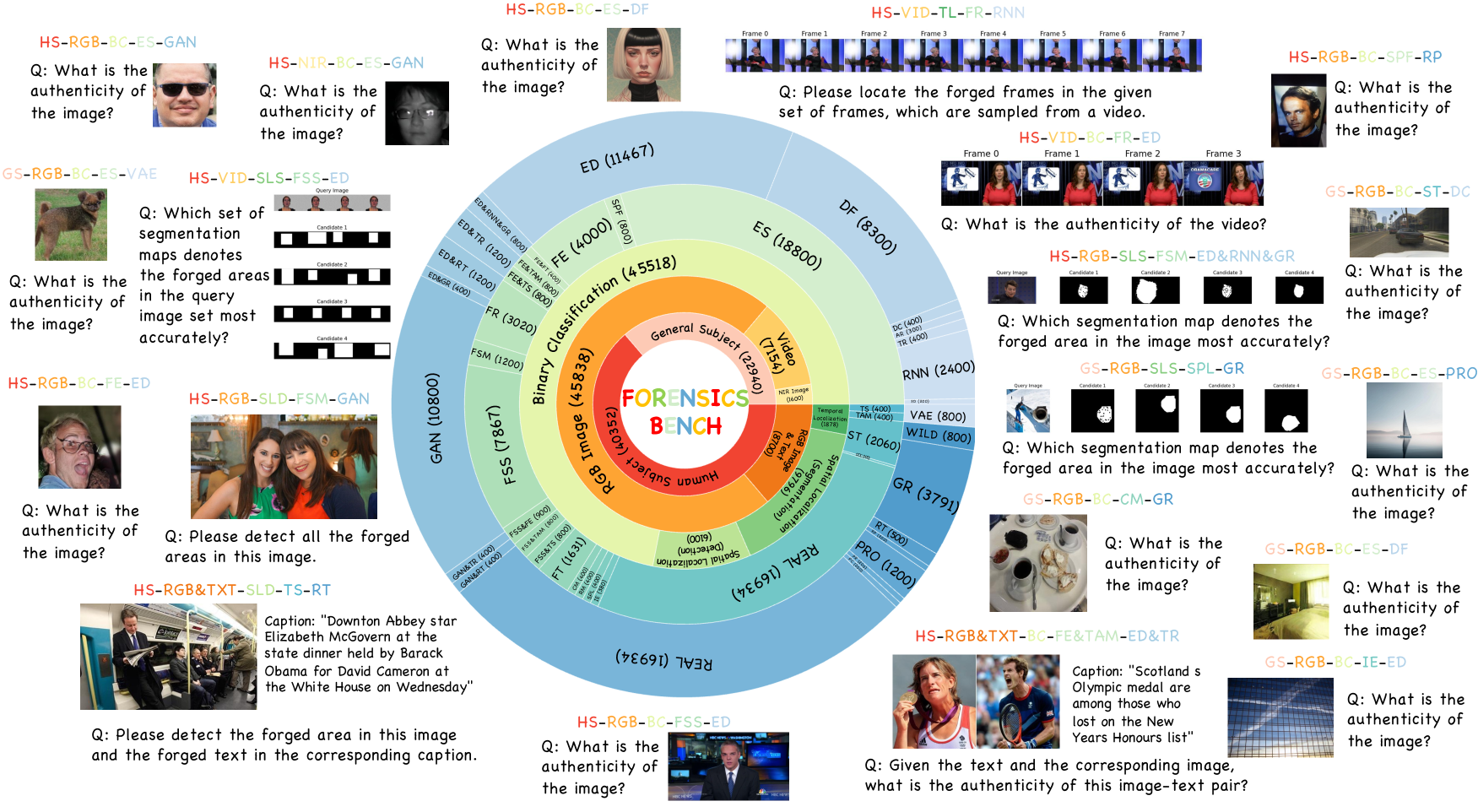
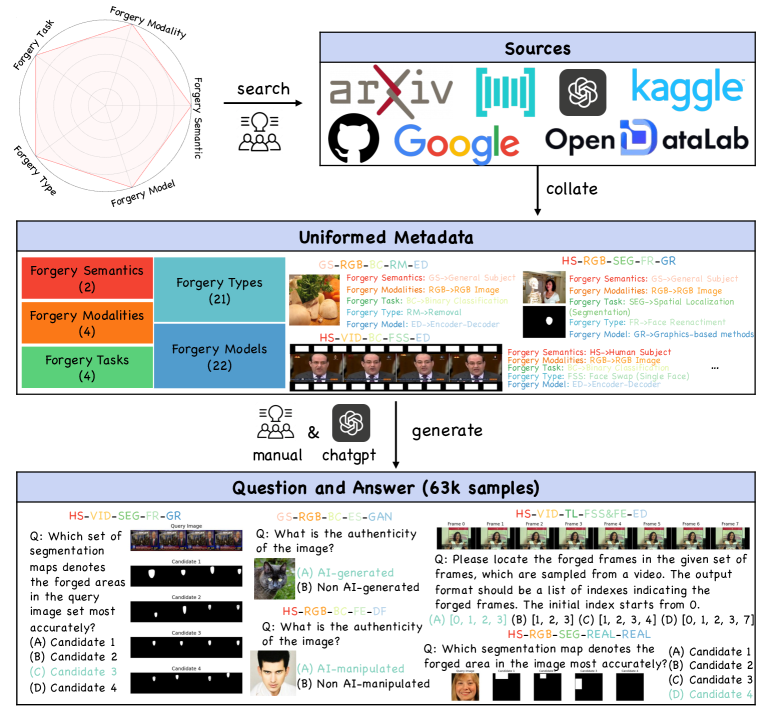
技术框架:Forensics-Bench基准测试套件包含63292个多项选择视觉问题,涵盖112种独特的伪造检测类型。这些问题从五个角度进行组织:伪造语义(例如,对象替换、属性修改)、伪造模态(例如,图像、视频、文本)、伪造任务(例如,分类、定位、推理)、伪造类型(例如,DeepFake、图像合成)和伪造模型(例如,StyleGAN、Stable Diffusion)。整个流程包括数据收集、问题生成、人工标注和评估指标定义。
关键创新:该基准测试套件的关键创新在于其全面性和多样性。它不仅涵盖了各种伪造类型和模态,还设计了需要复杂推理能力的视觉问题,从而更真实地反映了实际应用场景中的挑战。此外,该基准还考虑了不同的伪造模型,从而能够评估LVLM对不同生成技术的鲁棒性。
关键设计:Forensics-Bench的关键设计包括:1) 多样化的伪造数据来源,确保基准的代表性;2) 精心设计的视觉问题,涵盖识别、定位和推理等不同层次的能力;3) 明确的评估指标,用于量化LVLM在不同任务上的性能;4) 对比不同LVLM的性能,为研究人员提供参考。
🖼️ 关键图片
📊 实验亮点
对22个开源LVLM和3个专有模型(GPT-4o、Gemini 1.5 Pro和Claude 3.5 Sonnet)的评估结果表明,现有LVLM在Forensics-Bench上表现出显著的性能差距,突显了全面伪造检测的挑战。这些结果为未来研究提供了明确的方向,并为开发更强大的伪造检测器提供了基准。
🎯 应用场景
Forensics-Bench可应用于评估和提升大型视觉语言模型在检测虚假信息、识别篡改图像和视频方面的能力。该基准测试套件有助于开发更可靠的伪造检测系统,从而在新闻媒体、社交平台、安全监控等领域发挥重要作用,维护社会安全和信息安全。
📄 摘要(原文)
Recently, the rapid development of AIGC has significantly boosted the diversities of fake media spread in the Internet, posing unprecedented threats to social security, politics, law, and etc. To detect the ever-increasingly diverse malicious fake media in the new era of AIGC, recent studies have proposed to exploit Large Vision Language Models (LVLMs) to design robust forgery detectors due to their impressive performance on a wide range of multimodal tasks. However, it still lacks a comprehensive benchmark designed to comprehensively assess LVLMs' discerning capabilities on forgery media. To fill this gap, we present Forensics-Bench, a new forgery detection evaluation benchmark suite to assess LVLMs across massive forgery detection tasks, requiring comprehensive recognition, location and reasoning capabilities on diverse forgeries. Forensics-Bench comprises 63,292 meticulously curated multi-choice visual questions, covering 112 unique forgery detection types from 5 perspectives: forgery semantics, forgery modalities, forgery tasks, forgery types and forgery models. We conduct thorough evaluations on 22 open-sourced LVLMs and 3 proprietary models GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet, highlighting the significant challenges of comprehensive forgery detection posed by Forensics-Bench. We anticipate that Forensics-Bench will motivate the community to advance the frontier of LVLMs, striving for all-around forgery detectors in the era of AIGC. The deliverables will be updated at https://Forensics-Bench.github.io/.