Tables Guide Vision: Learning to See the Heart through Tabular Data
作者: Marta Hasny, Maxime Di Folco, Keno Bressem, Julia Schnabel
分类: cs.CV
发布日期: 2025-03-19 (更新: 2025-10-06)
💡 一句话要点
提出表格引导的对比学习框架,提升心血管影像表征学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对比学习 医学影像 心血管影像 表格数据 零样本学习
📋 核心要点
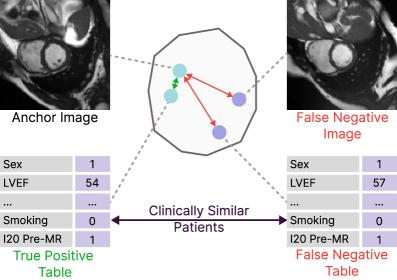
- 现有对比学习方法忽略了样本间的语义关系,在医学影像领域易产生错误的负样本。
- 提出表格引导的对比学习框架,利用表格数据构建更具语义信息的样本对,提升表征学习效果。
- 实验表明,该方法在心血管影像下游任务中表现优于传统方法,并在自然图像数据集上具有泛化能力。
📝 摘要(中文)
对比学习方法通常依赖于图像增强或多模态预训练来对齐不同模态的信息。然而,这些方法忽略了实例间的语义关系,导致将语义相似的样本视为负样本。在心血管医学影像中,人口统计学和临床属性对于评估疾病风险至关重要。本文提出了一种表格引导的对比学习框架,利用临床相关的表格数据来识别患者层面的相似性,构建更有意义的样本对,从而实现语义对齐的表征学习,无需跨模态联合嵌入。此外,本文还改进了k-NN算法用于零样本预测,克服了单模态表征缺乏零样本能力的问题。在大量的心脏短轴磁共振图像和临床属性数据集上的实验表明,表格数据能更有效地帮助区分患者亚群。在下游任务(包括微调、线性探测以及心血管动脉疾病和心脏表型的零样本预测)上的评估表明,结合表格数据指导能够产生比传统方法更强的视觉表征。该方法在汽车广告数据集上也表现出良好的泛化能力。
🔬 方法详解
问题定义:现有对比学习方法在医学影像领域,尤其是在心血管影像分析中,存在将具有相似临床特征的患者图像错误地视为负样本的问题。这是因为这些方法主要依赖图像增强或多模态对齐,而忽略了患者的临床信息,例如年龄、性别、病史等。这些临床信息对于区分不同的疾病亚型和预测患者预后至关重要。
核心思路:本文的核心思路是利用与图像相关的表格数据(如患者的临床信息)来指导对比学习过程。通过表格数据,可以更准确地识别语义相似的患者,从而构建更可靠的对比样本对。这样,模型就能学习到更具有临床意义的图像表征,从而提高在下游任务中的性能。
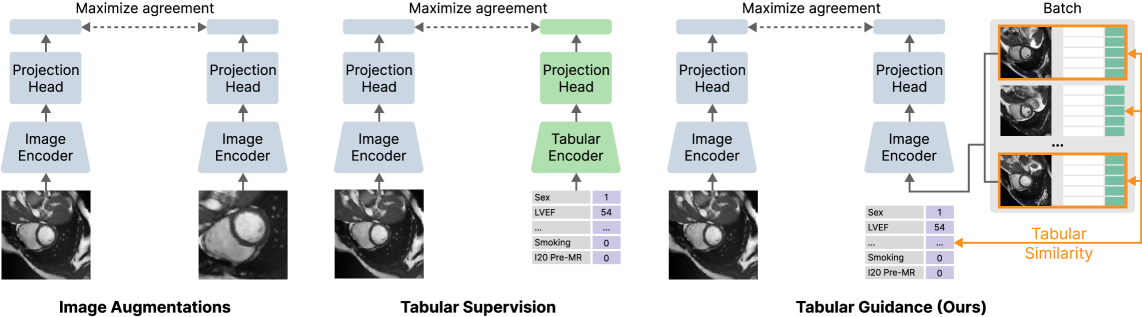
技术框架:该框架主要包含两个阶段:1) 表格引导的对比学习:首先,利用表格数据计算患者之间的相似度,然后根据相似度构建对比学习的样本对。图像通过标准的对比学习流程进行训练,但负样本的选择受到表格数据的引导。2) 改进的k-NN零样本预测:为了克服单模态表征的零样本能力不足,作者改进了k-NN算法,使其能够利用学习到的图像表征进行零样本预测。
关键创新:该方法最重要的创新点在于将表格数据引入到对比学习框架中,从而实现了语义对齐的表征学习。与传统的对比学习方法相比,该方法能够更好地利用患者的临床信息,从而学习到更具有临床意义的图像表征。此外,改进的k-NN算法也提高了零样本预测的性能。
关键设计:在表格引导的对比学习中,作者使用了一种基于距离度量的相似度计算方法,根据表格数据计算患者之间的相似度。对比学习损失函数采用标准的InfoNCE损失。在改进的k-NN算法中,作者使用学习到的图像表征作为特征向量,并根据k个最近邻的标签进行预测。具体的网络结构和参数设置在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
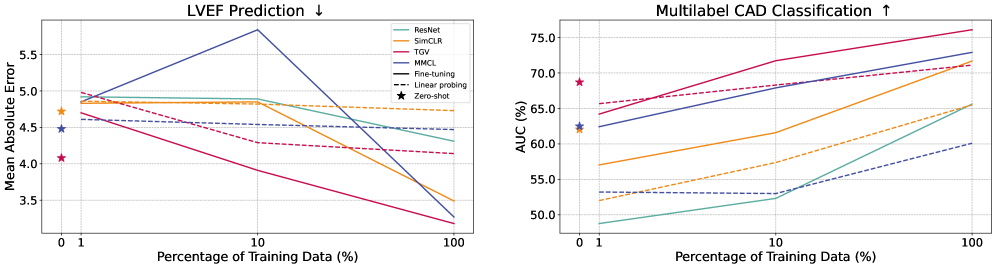
实验结果表明,该方法在心血管影像的下游任务中表现优于传统的对比学习方法。例如,在心血管动脉疾病和心脏表型的零样本预测任务中,该方法取得了显著的性能提升。此外,该方法在汽车广告数据集上也表现出良好的泛化能力,证明了其有效性。
🎯 应用场景
该研究成果可应用于心血管疾病的诊断、风险评估和预后预测。通过学习更具临床意义的图像表征,可以提高计算机辅助诊断系统的准确性和可靠性。此外,该方法还可以推广到其他医学影像领域,例如肿瘤学和神经影像学,以及其他具有表格数据的视觉任务。
📄 摘要(原文)
Contrastive learning methods in computer vision typically rely on augmented views of the same image or multimodal pretraining strategies that align paired modalities. However, these approaches often overlook semantic relationships between distinct instances, leading to false negatives when semantically similar samples are treated as negatives. This limitation is especially critical in medical imaging domains such as cardiology, where demographic and clinical attributes play a critical role in assessing disease risk and patient outcomes. We introduce a tabular-guided contrastive learning framework that leverages clinically relevant tabular data to identify patient-level similarities and construct more meaningful pairs, enabling semantically aligned representation learning without requiring joint embeddings across modalities. Additionally, we adapt the k-NN algorithm for zero-shot prediction to overcome the lack of zero-shot capability in unimodal representations. We demonstrate the strength of our methods using a large cohort of short-axis cardiac MR images and clinical attributes, where tabular data helps to more effectively distinguish between patient subgroups. Evaluation on downstream tasks, including fine-tuning, linear probing, and zero-shot prediction of cardiovascular artery diseases and cardiac phenotypes, shows that incorporating tabular data guidance yields stronger visual representations than conventional methods that rely solely on image augmentation or combined image-tabular embeddings. Further, we show that our method can generalize to natural images by evaluating it on a car advertisement dataset. The code will be available on GitHub upon acceptance.