UPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
作者: Qihui Zhang, Munan Ning, Zheyuan Liu, Yanbo Wang, Jiayi Ye, Yue Huang, Shuo Yang, Xiao Chen, Yibing Song, Li Yuan
分类: cs.CV
发布日期: 2025-03-19
备注: Accepted by CVPR 2025
💡 一句话要点
提出UPME:一种无监督多模态大语言模型评估框架,缓解人工标注依赖。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型评估 无监督学习 同行评审 视觉问答 视觉-语言评分
📋 核心要点
- 现有MLLM评估方法依赖大量人工标注的问答对,成本高昂且规模受限,自动化评估则易引入偏差。
- UPME框架利用无监督方式,仅需图像数据即可让模型自动生成问题并进行同行评审,降低人工成本。
- 实验表明UPME与人类评估结果高度相关,在MMstar和ScienceQA数据集上分别达到0.944和0.814的Pearson相关性。
📝 摘要(中文)
多模态大语言模型(MLLM)在视觉问答(VQA)领域取得了显著进展,对这些模型进行客观评估成为新的研究重点。现有的评估方法由于需要大量人工设计视觉图像的问答对,在规模和范围上受到限制。虽然自动化的MLLM-as-judge方法试图减少人工工作量,但往往引入偏差。为了解决这些问题,我们提出了一个无监督的同行评审MLLM评估框架UPME。该框架仅使用图像数据,允许模型自动生成问题并对其他模型的答案进行同行评审评估,有效减轻了对人工的依赖。此外,我们引入了视觉-语言评分系统来缓解偏差问题,该系统侧重于三个方面:(i)响应正确性;(ii)视觉理解和推理;(iii)图像-文本相关性。实验结果表明,UPME在MMstar数据集上与人类评估实现了0.944的Pearson相关性,在ScienceQA数据集上实现了0.814的Pearson相关性,表明我们的框架与人类设计的基准和内在的人类偏好高度一致。
🔬 方法详解
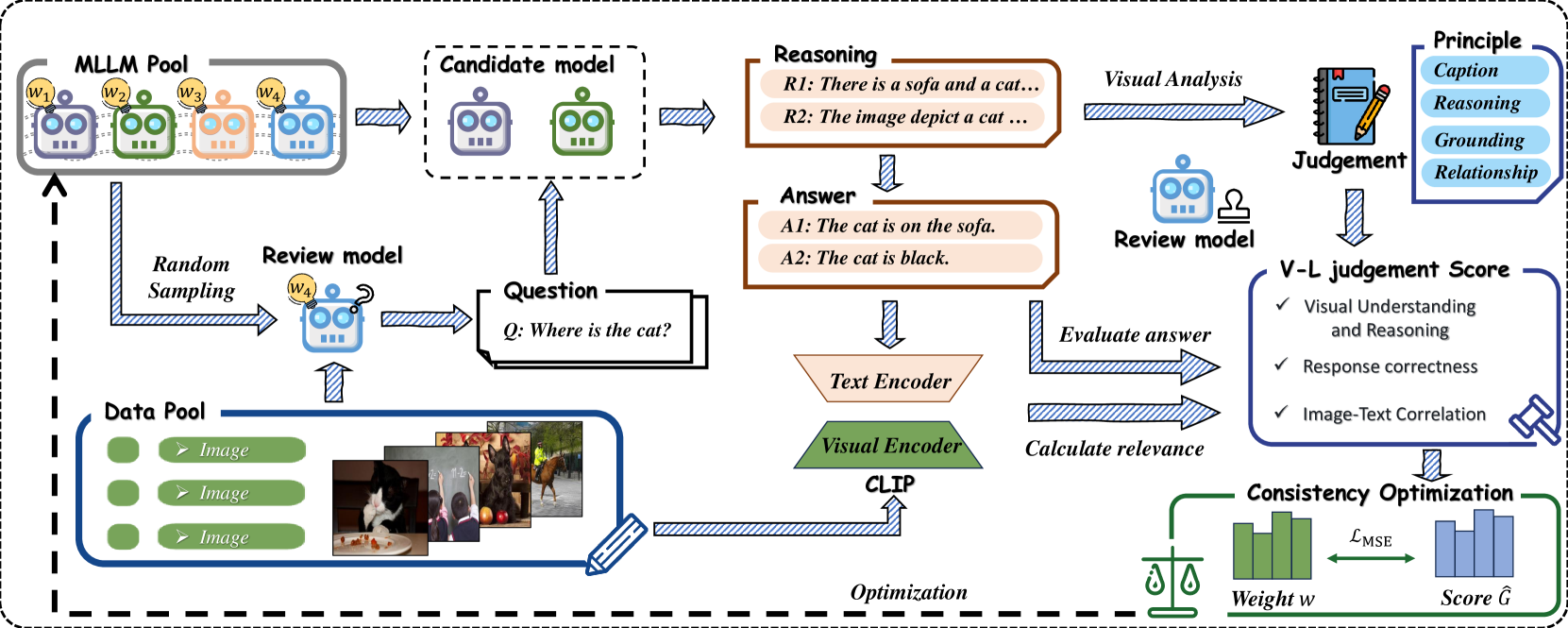
问题定义:现有的多模态大语言模型(MLLM)评估方法主要面临两个问题:一是依赖大量人工标注的视觉问答对,这导致评估成本高昂且难以扩展到大规模数据集;二是自动化评估方法,例如使用MLLM作为评判者,容易引入偏差,影响评估的客观性。因此,如何设计一种高效、客观的MLLM评估框架,减少人工干预并降低偏差,是本文要解决的核心问题。
核心思路:UPME的核心思路是利用无监督学习的方式,让MLLM模型在没有人工标注的情况下,自动生成问题并对其他模型的答案进行同行评审。通过这种方式,可以显著降低对人工标注的依赖,并实现大规模的MLLM评估。同时,为了减少评估偏差,UPME引入了视觉-语言评分系统,从多个维度评估答案的质量。
技术框架:UPME框架主要包含以下几个阶段:1) 问题生成:给定一张图像,MLLM模型自动生成与图像内容相关的问答对。2) 答案生成:使用不同的MLLM模型对生成的问题进行回答。3) 同行评审:使用MLLM模型对不同模型的答案进行评估,判断答案的质量。4) 视觉-语言评分:引入视觉-语言评分系统,从响应正确性、视觉理解和推理、图像-文本相关性三个方面对答案进行评分。
关键创新:UPME最重要的创新点在于其无监督的评估方式。与传统的依赖人工标注的评估方法不同,UPME仅使用图像数据,通过自动生成问题和同行评审的方式,实现了高效、可扩展的MLLM评估。此外,视觉-语言评分系统的引入,有助于减少评估偏差,提高评估的客观性。
关键设计:在问题生成阶段,可以使用不同的prompt策略来引导MLLM模型生成高质量的问题。在视觉-语言评分阶段,需要设计合适的评分指标和权重,以平衡不同评估维度的重要性。例如,可以采用基于规则或基于学习的方法来设计评分指标,并使用交叉验证等技术来优化权重。
🖼️ 关键图片


📊 实验亮点
UPME在MMstar和ScienceQA数据集上进行了实验验证。在MMstar数据集上,UPME与人类评估实现了0.944的Pearson相关性,表明UPME的评估结果与人类的判断高度一致。在ScienceQA数据集上,UPME也取得了0.814的Pearson相关性。这些结果表明,UPME能够有效地评估MLLM的性能,并与人类的偏好相符。
🎯 应用场景
UPME框架可广泛应用于多模态大语言模型的开发和评估。它可以帮助研究人员和开发者快速评估不同模型的性能,发现模型的优势和不足,从而指导模型的改进和优化。此外,UPME还可以用于构建大规模的MLLM评估基准,促进多模态学习领域的发展。该框架的无监督特性使其具有很高的应用价值和潜力。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have emerged to tackle the challenges of Visual Question Answering (VQA), sparking a new research focus on conducting objective evaluations of these models. Existing evaluation methods face limitations due to the significant human workload required to design Q&A pairs for visual images, which inherently restricts the scale and scope of evaluations. Although automated MLLM-as-judge approaches attempt to reduce the human workload through automatic evaluations, they often introduce biases. To address these problems, we propose an Unsupervised Peer review MLLM Evaluation framework. It utilizes only image data, allowing models to automatically generate questions and conduct peer review assessments of answers from other models, effectively alleviating the reliance on human workload. Additionally, we introduce the vision-language scoring system to mitigate the bias issues, which focuses on three aspects: (i) response correctness; (ii) visual understanding and reasoning; and (iii) image-text correlation. Experimental results demonstrate that UPME achieves a Pearson correlation of 0.944 with human evaluations on the MMstar dataset and 0.814 on the ScienceQA dataset, indicating that our framework closely aligns with human-designed benchmarks and inherent human preferences.