VisNumBench: Evaluating Number Sense of Multimodal Large Language Models
作者: Tengjin Weng, Jingyi Wang, Wenhao Jiang, Zhong Ming
分类: cs.CV
发布日期: 2025-03-19 (更新: 2025-07-31)
备注: accepted by ICCV 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出VisNumBench,用于评估多模态大语言模型(MLLMs)的数字感知能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 数字感知 视觉数字基准 模型评估 视觉推理
📋 核心要点
- 现有MLLM在视觉数字任务中缺乏类似人类的直观数字感知能力,这限制了其在实际场景中的应用。
- VisNumBench通过构建包含多种视觉数字属性和估计任务的基准,系统性地评估MLLM的数字感知能力。
- 实验表明,现有MLLM在数字感知方面表现不佳,即使是大型模型和CoT方法也未能显著提升性能。
📝 摘要(中文)
本文提出了视觉数字基准(VisNumBench),旨在评估多模态大语言模型(MLLMs)在各种视觉数字任务中的数字感知能力。VisNumBench包含约1900个多项选择题-答案对,这些数据来源于合成和真实世界的视觉数据,涵盖了七个视觉数字属性和四种类型的视觉数字估计任务。在VisNumBench上的实验表明:(i)包括Qwen2.5-VL和InternVL2.5等开源模型,以及GPT-4o和Gemini 2.0 Flash等专有模型在内的17个MLLM在数字感知相关任务中的表现远低于人类水平。(ii)多模态数学模型和多模态思维链(CoT)模型在数字感知能力方面没有表现出显著的改进。(iii)参数规模更大、通用能力更强的MLLM在数字感知能力方面表现出适度的提升。VisNumBench将为研究界提供有价值的资源,鼓励进一步提升MLLM的数字感知能力。
🔬 方法详解
问题定义:论文旨在评估多模态大语言模型(MLLMs)的数字感知能力,即模型理解和处理视觉场景中数字信息的能力。现有方法缺乏系统的评估基准,难以准确衡量MLLMs在这一方面的表现。现有模型在处理视觉数字任务时,往往表现出与人类直觉不符的结果,例如无法准确估计物体数量、比较大小等。
核心思路:论文的核心思路是构建一个全面的视觉数字基准(VisNumBench),包含多种类型的视觉数字任务,从而系统地评估MLLMs的数字感知能力。通过分析模型在不同任务上的表现,可以深入了解模型在数字感知方面的优势和不足,为后续改进提供指导。
技术框架:VisNumBench包含以下几个主要组成部分:1) 数据集构建:收集和生成包含视觉数字信息的图像和问题-答案对。数据集涵盖合成数据和真实世界数据,以保证评估的全面性。2) 任务定义:定义七个视觉数字属性(例如数量、大小、比例)和四种类型的视觉数字估计任务(例如计数、比较、排序、估计)。3) 模型评估:使用VisNumBench评估各种MLLMs的性能,并分析其在不同任务上的表现。4) 结果分析:对实验结果进行深入分析,找出模型在数字感知方面的弱点,并提出改进建议。
关键创新:VisNumBench的关键创新在于其全面性和系统性。它不仅包含多种类型的视觉数字任务,还涵盖了合成数据和真实世界数据,从而能够更准确地评估MLLMs的数字感知能力。此外,VisNumBench还提供了一个统一的评估框架,方便研究人员比较不同模型在数字感知方面的表现。
关键设计:VisNumBench的数据集包含约1900个多项选择题-答案对。数据集的构建过程中,作者精心设计了问题,以考察模型在不同方面的数字感知能力。例如,一些问题需要模型估计图像中物体的数量,另一些问题需要模型比较不同物体的大小。此外,作者还考虑了不同视觉属性对模型性能的影响,例如物体的大小、颜色、形状等。
🖼️ 关键图片
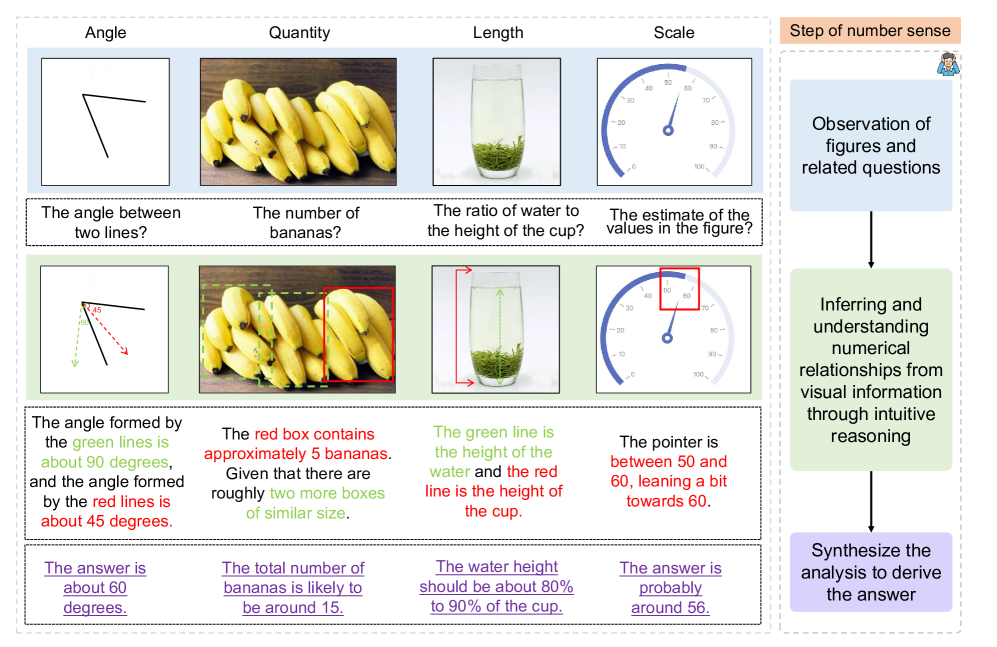

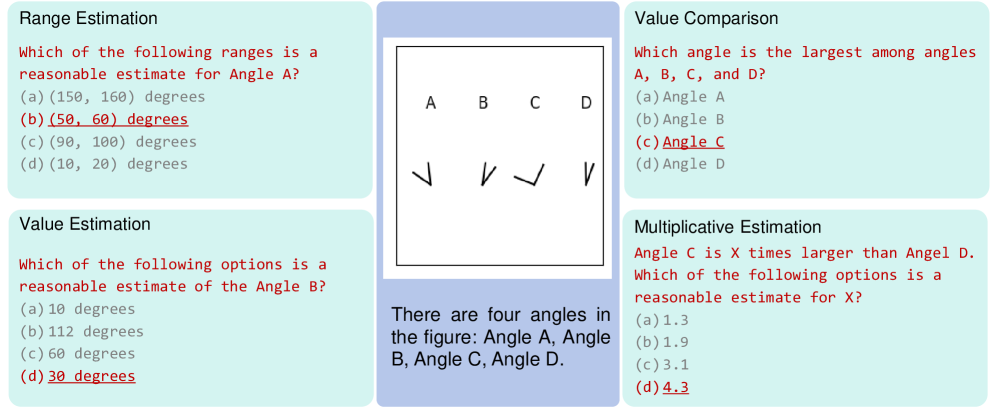
📊 实验亮点
实验结果表明,现有MLLM在VisNumBench上的表现远低于人类水平,即使是GPT-4o和Gemini 2.0 Flash等先进模型也未能达到令人满意的性能。多模态数学模型和CoT模型在数字感知能力方面没有表现出显著的改进。参数规模更大的MLLM在数字感知能力方面表现出适度的提升,但仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在需要数字感知的实际场景中的性能,例如智能零售中商品数量估计、自动驾驶中车辆数量判断、医学影像中病灶大小评估等。通过提高模型对视觉数字信息的理解能力,可以使其更好地服务于人类生活。
📄 摘要(原文)
Can Multimodal Large Language Models (MLLMs) develop an intuitive number sense similar to humans? Targeting this problem, we introduce Visual Number Benchmark (VisNumBench) to evaluate the number sense abilities of MLLMs across a wide range of visual numerical tasks. VisNumBench consists of about 1,900 multiple-choice question-answer pairs derived from both synthetic and real-world visual data, covering seven visual numerical attributes and four types of visual numerical estimation tasks. Our experiments on VisNumBench led to the following key findings: (i) The 17 MLLMs we tested, including open-source models such as Qwen2.5-VL and InternVL2.5, as well as proprietary models like GPT-4o and Gemini 2.0 Flash, perform significantly below human levels in number sense-related tasks. (ii) Multimodal mathematical models and multimodal chain-of-thought (CoT) models did not exhibit significant improvements in number sense abilities. (iii) Stronger MLLMs with larger parameter sizes and broader general abilities demonstrate modest gains in number sense abilities. We believe VisNumBench will serve as a valuable resource for the research community, encouraging further advancements in enhancing MLLMs' number sense abilities. Code and dataset are available at https://wwwtttjjj.github.io/VisNumBench/.