Spot the Fake: Large Multimodal Model-Based Synthetic Image Detection with Artifact Explanation
作者: Siwei Wen, Junyan Ye, Peilin Feng, Hengrui Kang, Zichen Wen, Yize Chen, Jiang Wu, Wenjun Wu, Conghui He, Weijia Li
分类: cs.CV
发布日期: 2025-03-19 (更新: 2025-10-16)
🔗 代码/项目: GITHUB
💡 一句话要点
提出FakeVLM:基于大模型的多模态合成图像检测与伪造解释
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成图像检测 多模态模型 伪影解释 自然语言生成 深度伪造 AIGC 可解释性
📋 核心要点
- 现有图像真伪鉴别方法缺乏人类可解释性,难以应对日益复杂的合成数据。
- FakeVLM通过大型多模态模型,不仅能区分真假图像,还能用自然语言解释伪影。
- FakeVLM在多个数据集上表现优异,无需额外分类器,为合成图像检测设定新基准。
📝 摘要(中文)
随着人工智能生成内容(AIGC)技术的快速发展,合成图像日益普及,给图像真伪鉴别带来了新的挑战。现有方法在评估图像真实性和定位伪造区域方面取得了一定效果,但通常缺乏人类可解释性,并且不能完全应对日益复杂的合成数据。为了解决这些挑战,我们提出了FakeVLM,一个专门用于通用合成图像和DeepFake检测的大型多模态模型。FakeVLM不仅擅长区分真实图像和伪造图像,而且能够为图像伪影提供清晰的自然语言解释,从而增强了可解释性。此外,我们还提出了FakeClue,一个包含超过10万张图像的综合数据集,涵盖七个类别,并用自然语言标注了细粒度的伪影线索。FakeVLM的性能与专家模型相当,同时无需额外的分类器,使其成为合成数据检测的强大解决方案。在多个数据集上的广泛评估证实了FakeVLM在真实性分类和伪影解释任务中的优越性,为合成图像检测设定了新的基准。代码、模型权重和数据集可在https://github.com/opendatalab/FakeVLM 找到。
🔬 方法详解
问题定义:论文旨在解决合成图像检测和伪造解释问题。现有方法虽然能检测图像真伪,但缺乏可解释性,难以定位和解释图像中的伪影,无法有效应对日益复杂的AIGC生成图像。
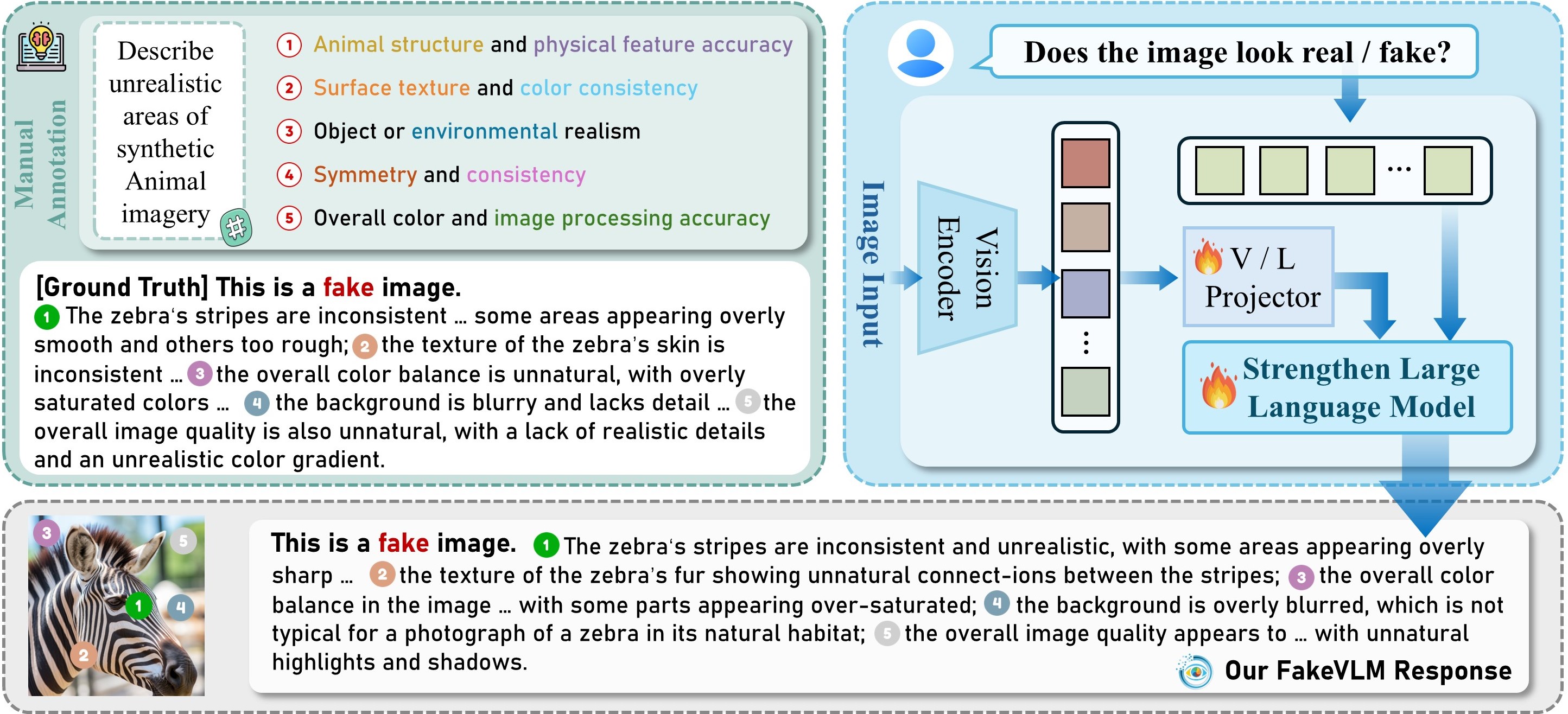
核心思路:论文的核心思路是利用大型多模态模型(Large Multimodal Model, LMM)的强大能力,使其不仅能区分真假图像,还能生成自然语言解释,说明图像中存在的伪影。通过结合视觉信息和语言信息,提高模型的可解释性和鲁棒性。
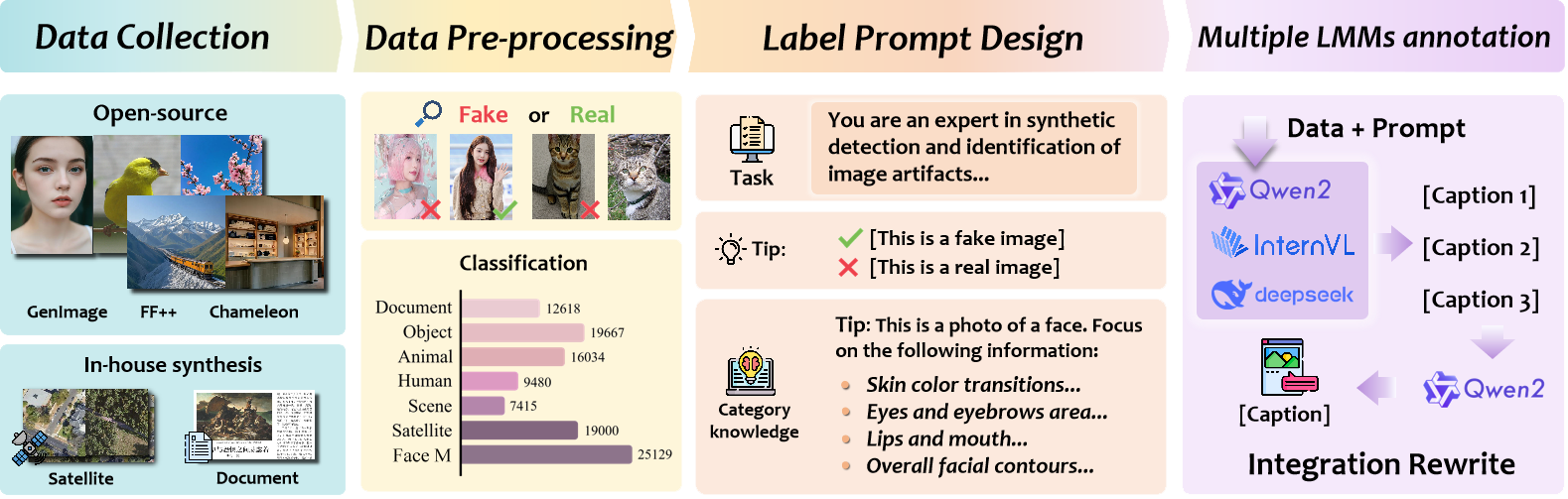
技术框架:FakeVLM的技术框架主要包含以下几个部分:1) 图像编码器:用于提取图像的视觉特征。2) 语言模型:用于生成自然语言解释。3) 多模态融合模块:将视觉特征和语言特征进行融合,用于真伪分类和伪影解释。整体流程是,输入图像首先通过图像编码器提取视觉特征,然后将视觉特征输入到多模态融合模块中,结合语言模型的先验知识,生成图像真伪的判断结果和伪影的自然语言解释。
关键创新:FakeVLM的关键创新在于:1) 提出了一个专门针对合成图像检测和伪造解释的大型多模态模型。2) 能够生成自然语言解释,提高了模型的可解释性。3) 构建了一个包含细粒度伪影线索的FakeClue数据集,用于训练和评估模型。4) 无需额外的分类器,即可达到与专家模型相当的性能。
关键设计:FakeVLM的关键设计包括:1) 图像编码器采用预训练的视觉Transformer模型,如ViT或CLIP,以提取高质量的视觉特征。2) 语言模型采用预训练的语言模型,如GPT或BERT,以生成流畅自然的语言解释。3) 多模态融合模块采用交叉注意力机制,将视觉特征和语言特征进行有效融合。4) 损失函数包括真伪分类损失和伪影解释损失,用于联合优化模型。
🖼️ 关键图片
📊 实验亮点
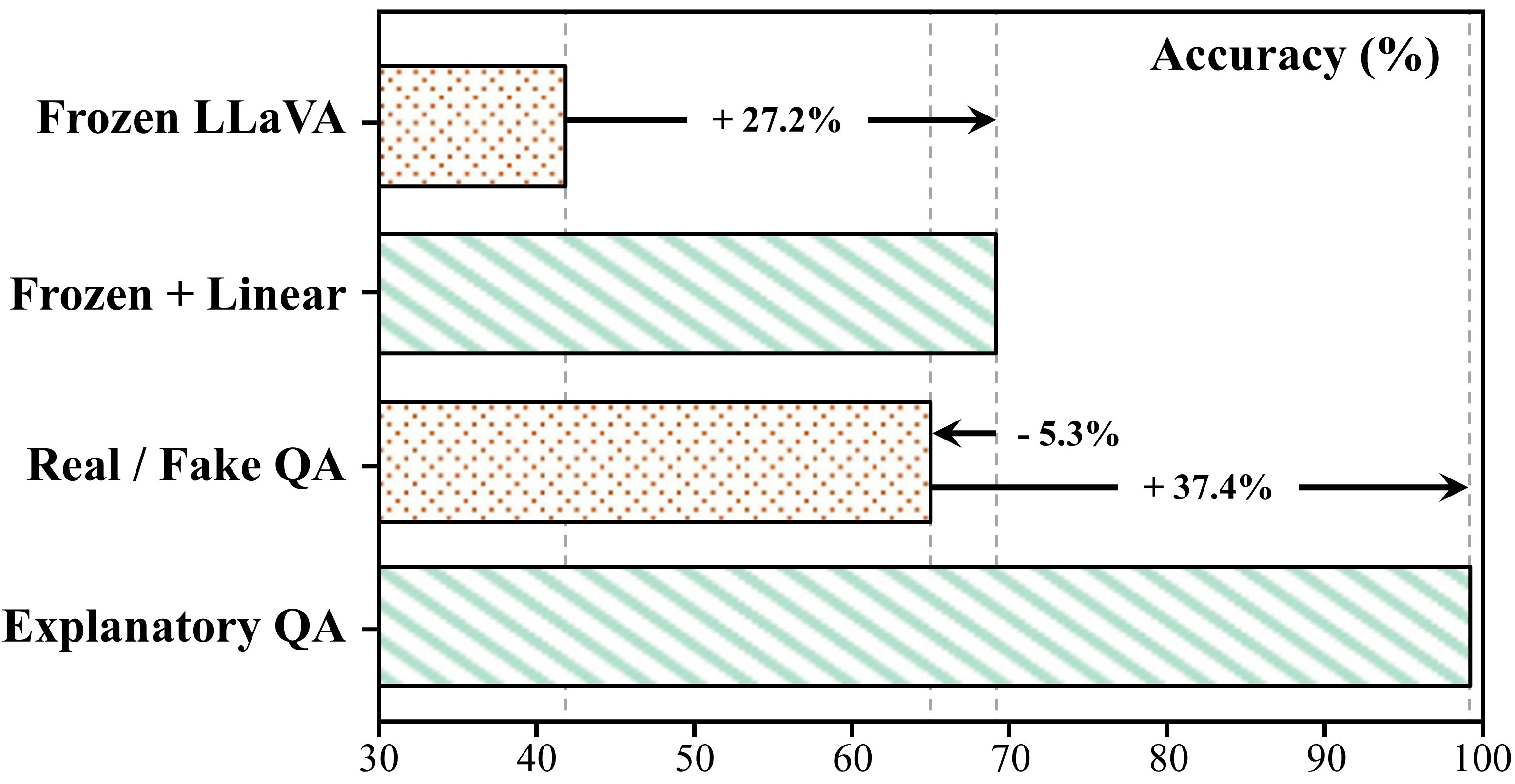
FakeVLM在多个数据集上进行了广泛评估,包括FakeClue、以及其他公开数据集。实验结果表明,FakeVLM在真实性分类和伪影解释任务中均取得了显著的性能提升,与现有方法相比,FakeVLM能够生成更准确、更具可解释性的伪影解释,并且无需额外的分类器即可达到与专家模型相当的性能。
🎯 应用场景
FakeVLM可应用于社交媒体平台的内容审核,新闻媒体的图像真实性验证,以及金融领域的欺诈检测等。该研究有助于提高公众对AIGC生成内容的辨别能力,减少虚假信息传播,维护网络安全和信息安全。未来可进一步扩展到视频、音频等其他模态的合成内容检测。
📄 摘要(原文)
With the rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, synthetic images have become increasingly prevalent in everyday life, posing new challenges for authenticity assessment and detection. Despite the effectiveness of existing methods in evaluating image authenticity and locating forgeries, these approaches often lack human interpretability and do not fully address the growing complexity of synthetic data. To tackle these challenges, we introduce FakeVLM, a specialized large multimodal model designed for both general synthetic image and DeepFake detection tasks. FakeVLM not only excels in distinguishing real from fake images but also provides clear, natural language explanations for image artifacts, enhancing interpretability. Additionally, we present FakeClue, a comprehensive dataset containing over 100,000 images across seven categories, annotated with fine-grained artifact clues in natural language. FakeVLM demonstrates performance comparable to expert models while eliminating the need for additional classifiers, making it a robust solution for synthetic data detection. Extensive evaluations across multiple datasets confirm the superiority of FakeVLM in both authenticity classification and artifact explanation tasks, setting a new benchmark for synthetic image detection. The code, model weights, and dataset can be found here: https://github.com/opendatalab/FakeVLM.