Temporal-Consistent Video Restoration with Pre-trained Diffusion Models
作者: Hengkang Wang, Yang Liu, Huidong Liu, Chien-Chih Wang, Yanhui Guo, Hongdong Li, Bryan Wang, Ju Sun
分类: cs.CV
发布日期: 2025-03-19
💡 一句话要点
提出基于预训练扩散模型的时序一致性视频修复框架,提升视觉质量和时序稳定性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频修复 扩散模型 时序一致性 最大后验估计 光流估计
📋 核心要点
- 现有基于预训练扩散模型的视频修复方法在反向扩散过程中存在近似误差,导致修复质量受限,且时序一致性不足。
- 该论文提出一种最大后验框架,直接在扩散模型的种子空间中参数化视频帧,避免了近似误差,并提升了修复质量。
- 实验结果表明,该方法在视觉质量和时序一致性方面均优于现有技术,尤其是在虚拟现实任务中表现突出。
📝 摘要(中文)
本文提出了一种基于预训练扩散模型(DMs)的时序一致性视频修复(VR)方法,旨在从退化的视频中恢复高质量的视频。现有基于DMs的零样本VR方法存在反向扩散过程中的近似误差和时序一致性不足的问题,并且处理3D视频数据时计算量大。本文将DMs中的反向过程视为一个函数,提出了一个新颖的最大后验(MAP)框架,该框架直接参数化DMs种子空间中的视频帧,消除了近似误差。此外,还引入了促进双层时序一致性的策略:通过利用种子空间中的聚类结构来实现语义一致性,并通过光流细化的渐进式扭曲来实现像素级一致性。在多个虚拟现实任务上的大量实验表明,与最先进的方法相比,本文方法实现了卓越的视觉质量和时序一致性。
🔬 方法详解
问题定义:视频修复旨在从低质量或损坏的视频中恢复高质量的视频内容。现有的基于预训练扩散模型的视频修复方法,在反向扩散过程中会引入近似误差,导致修复后的视频质量下降。此外,这些方法在保持视频帧之间的时间一致性方面表现不足,容易出现闪烁等伪影。同时,直接处理3D视频数据计算量巨大,限制了其应用范围。
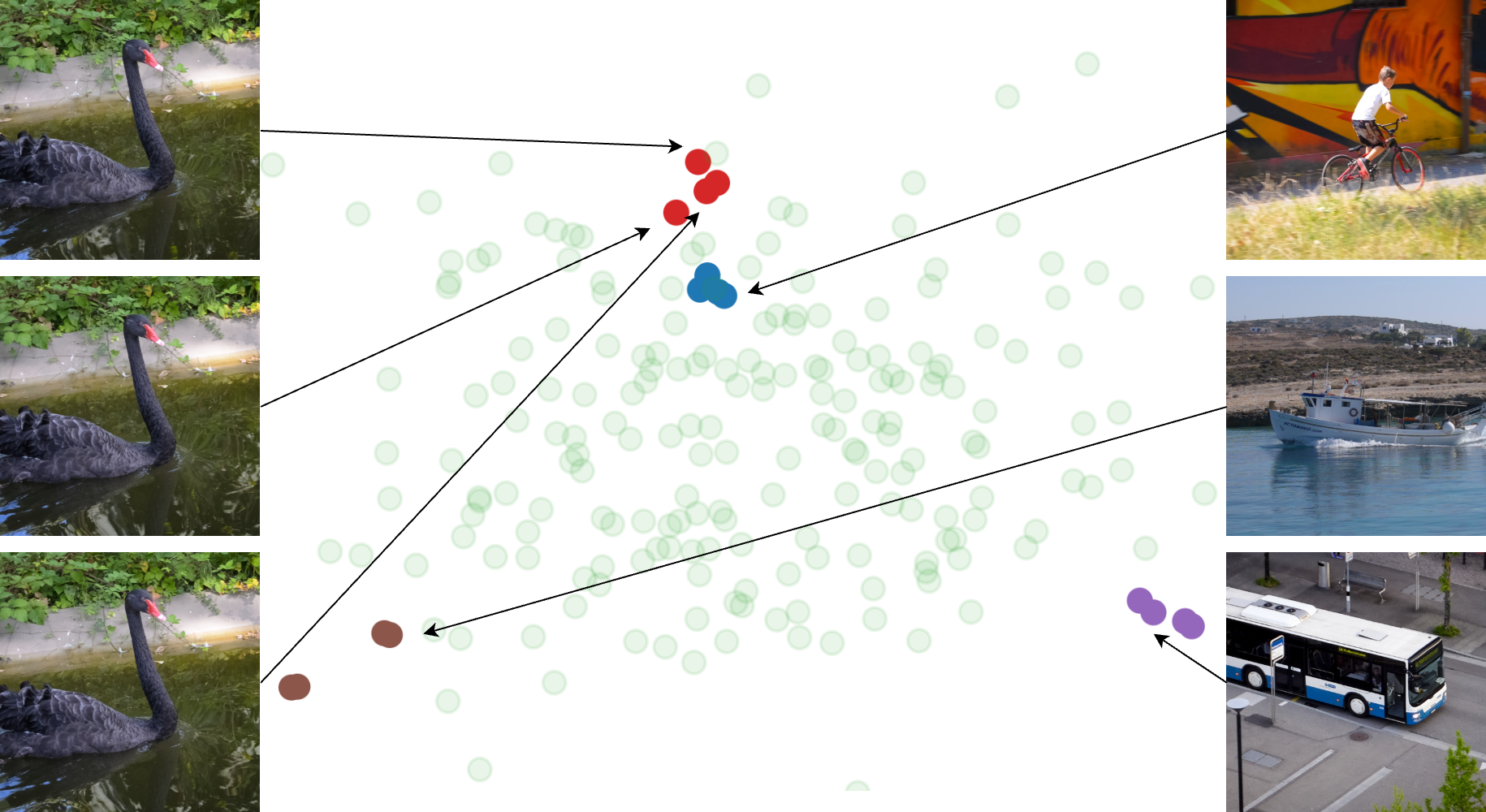
核心思路:该论文的核心思路是将扩散模型的反向过程视为一个函数,并直接在扩散模型的种子空间中参数化视频帧。通过这种方式,可以避免反向扩散过程中的近似误差,从而提高视频修复的质量。此外,论文还通过引入语义一致性和像素级一致性来增强视频的时序一致性。
技术框架:该方法基于最大后验(MAP)框架,主要包括以下几个阶段:1)初始化:将退化的视频帧编码到扩散模型的种子空间中。2)优化:通过优化种子空间中的参数,使得修复后的视频帧在视觉质量和时序一致性方面达到最佳。3)解码:将优化后的种子空间参数解码为修复后的视频帧。该框架利用光流估计进行像素级别的对齐,并利用种子空间的聚类结构保持语义一致性。
关键创新:该论文的关键创新在于:1)直接在扩散模型的种子空间中参数化视频帧,避免了反向扩散过程中的近似误差。2)提出了双层时序一致性策略,包括基于种子空间聚类的语义一致性和基于光流细化的像素级一致性。这两种策略有效地提高了修复后视频的时序稳定性。
关键设计:论文使用预训练的扩散模型作为先验知识,并设计了相应的损失函数来约束种子空间中的参数。损失函数包括:1)重构损失,用于保证修复后的视频帧与原始视频帧的一致性。2)时序一致性损失,用于保证视频帧之间的时间一致性。3)光流损失,用于约束光流估计的准确性。此外,论文还采用了渐进式扭曲策略,逐步提高像素级一致性。
🖼️ 关键图片

📊 实验亮点
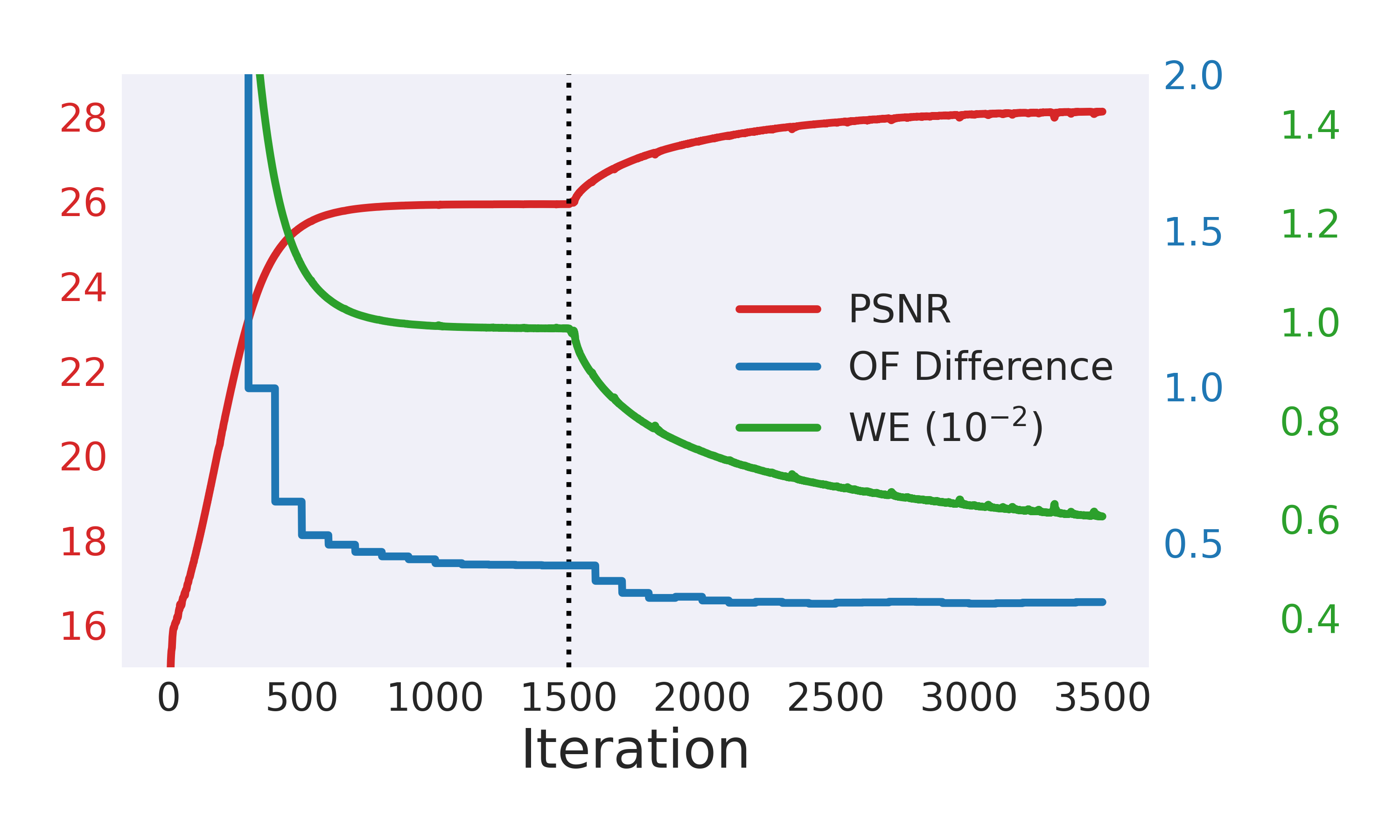
实验结果表明,该方法在多个视频修复任务上取得了显著的性能提升。例如,在常用的视频修复数据集上,该方法在PSNR和SSIM等指标上均优于现有最先进的方法。此外,该方法在时序一致性方面也表现出色,有效减少了修复后视频中的闪烁等伪影。
🎯 应用场景
该研究成果可广泛应用于视频监控、老旧视频修复、电影制作等领域。例如,可以用于修复监控录像中模糊或损坏的视频片段,提高视频分析的准确性;也可以用于修复老电影,使其焕发新的生命力。此外,该技术还可以应用于虚拟现实和增强现实等领域,提供更高质量的视频体验。
📄 摘要(原文)
Video restoration (VR) aims to recover high-quality videos from degraded ones. Although recent zero-shot VR methods using pre-trained diffusion models (DMs) show good promise, they suffer from approximation errors during reverse diffusion and insufficient temporal consistency. Moreover, dealing with 3D video data, VR is inherently computationally intensive. In this paper, we advocate viewing the reverse process in DMs as a function and present a novel Maximum a Posterior (MAP) framework that directly parameterizes video frames in the seed space of DMs, eliminating approximation errors. We also introduce strategies to promote bilevel temporal consistency: semantic consistency by leveraging clustering structures in the seed space, and pixel-level consistency by progressive warping with optical flow refinements. Extensive experiments on multiple virtual reality tasks demonstrate superior visual quality and temporal consistency achieved by our method compared to the state-of-the-art.