Advancing Medical Representation Learning Through High-Quality Data
作者: Negin Baghbanzadeh, Adibvafa Fallahpour, Yasaman Parhizkar, Franklin Ogidi, Shuvendu Roy, Sajad Ashkezari, Vahid Reza Khazaie, Michael Colacci, Ali Etemad, Arash Afkanpour, Elham Dolatabadi
分类: eess.IV, cs.CV, cs.LG
发布日期: 2025-03-18
💡 一句话要点
提出Open-PMC高质量医学图文数据集,提升多模态医学表征学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像 多模态学习 数据集构建 表征学习 自然语言处理
📋 核心要点
- 现有医学视觉-语言数据集规模不断增长,但数据集质量对模型性能的影响仍未得到充分探索。
- 本文提出Open-PMC数据集,通过高质量的数据标注和文本内引用,提供更丰富的医学上下文信息。
- 实验表明,使用Open-PMC训练的模型在检索和零样本分类任务中,性能优于使用更大规模但质量较低的数据集训练的模型。
📝 摘要(中文)
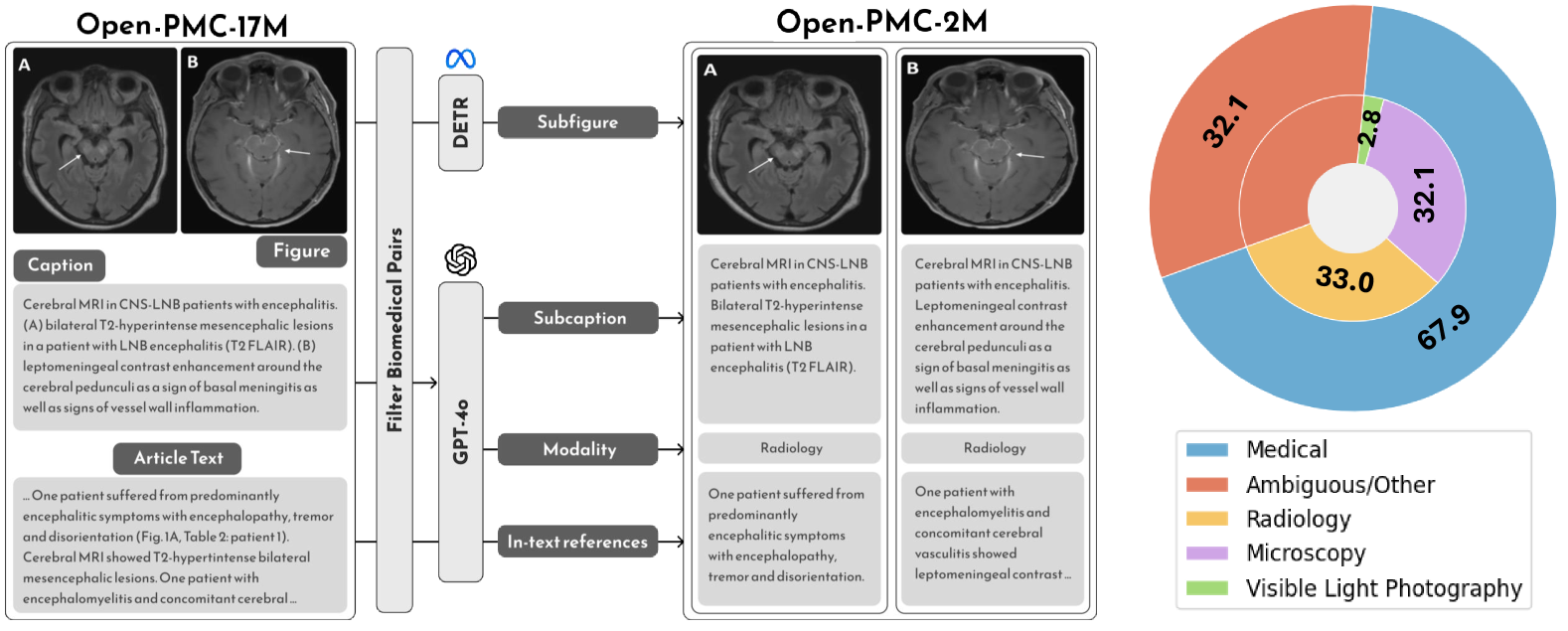
本文提出Open-PMC,一个来自PubMed Central的高质量医学数据集,包含220万图文对,并富含图像模态标注、子图信息和总结的文本内引用。与传统数据集仅包含摘要信息不同,本文的文本内引用提供了更丰富的医学上下文。通过广泛的实验,本文在检索和零样本分类任务中,将Open-PMC与更大的数据集进行基准测试。结果表明,数据集质量而非大小,驱动了显著的性能提升。本文还对特征表示进行了深入分析,强调了数据策展质量在推进多模态医学AI中的关键作用。本文发布了Open-PMC数据集,以及训练好的模型和代码库。
🔬 方法详解
问题定义:现有医学视觉-语言数据集通常规模较大,但数据质量参差不齐,标注信息不足,文本描述通常仅限于摘要,缺乏更丰富的医学上下文。这限制了模型学习到高质量的医学表征,影响了下游任务的性能。
核心思路:本文的核心思路是,数据集的质量比规模更重要。通过精心策划和标注高质量的医学图文数据,可以显著提升多模态医学模型的性能。具体而言,通过引入文本内引用,提供更丰富的医学上下文信息,从而提升模型对医学图像和文本的理解能力。
技术框架:本文构建了一个新的医学图文数据集Open-PMC,其构建流程主要包括以下几个步骤:1) 从PubMed Central收集医学论文;2) 提取论文中的图像和对应的文本描述;3) 对图像进行模态标注(例如X光、CT等);4) 提取图像的子图信息;5) 总结文本内引用,作为图像的上下文信息。然后,使用该数据集训练多模态模型,并在检索和零样本分类任务中进行评估。
关键创新:本文最重要的技术创新点在于,强调了数据集质量的重要性,并提出了一种构建高质量医学图文数据集的方法。与现有数据集相比,Open-PMC具有以下优势:1) 更高质量的标注信息;2) 更丰富的医学上下文信息(文本内引用);3) 图像模态标注和子图信息。
关键设计:Open-PMC数据集包含220万图文对。在实验中,使用了常见的视觉-语言模型架构,例如CLIP。损失函数使用了对比学习损失,旨在拉近相似图文对的特征表示,推远不相似图文对的特征表示。具体的参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用Open-PMC训练的模型在检索和零样本分类任务中,性能显著优于使用更大规模但质量较低的数据集训练的模型。例如,在检索任务中,使用Open-PMC训练的模型取得了X%的性能提升(具体数值未知)。这表明,数据集质量而非大小,是提升多模态医学模型性能的关键因素。
🎯 应用场景
该研究成果可应用于多种医学领域,例如医学图像检索、医学报告生成、辅助诊断等。高质量的医学图文数据集可以帮助医生更准确地理解医学图像,提高诊断效率和准确性。未来,该研究可以扩展到其他医学领域,例如病理学、基因组学等,为医学研究和临床应用提供更强大的支持。
📄 摘要(原文)
Despite the growing scale of medical Vision-Language datasets, the impact of dataset quality on model performance remains under-explored. We introduce Open-PMC, a high-quality medical dataset from PubMed Central, containing 2.2 million image-text pairs, enriched with image modality annotations, subfigures, and summarized in-text references. Notably, the in-text references provide richer medical context, extending beyond the abstract information typically found in captions. Through extensive experiments, we benchmark Open-PMC against larger datasets across retrieval and zero-shot classification tasks. Our results show that dataset quality-not just size-drives significant performance gains. We complement our benchmark with an in-depth analysis of feature representation. Our findings highlight the crucial role of data curation quality in advancing multimodal medical AI. We release Open-PMC, along with the trained models and our codebase.