VEGGIE: Instructional Editing and Reasoning Video Concepts with Grounded Generation
作者: Shoubin Yu, Difan Liu, Ziqiao Ma, Yicong Hong, Yang Zhou, Hao Tan, Joyce Chai, Mohit Bansal
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-03-18 (更新: 2025-10-25)
备注: ICCV 2025; First three authors contributed equally. Project page: https://veggie-gen.github.io/
💡 一句话要点
VEGGIE:提出基于指令的视频编辑框架,实现概念编辑、定位和推理的统一
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频编辑 指令学习 多模态大语言模型 扩散模型 视频生成 对象定位 推理分割
📋 核心要点
- 现有的视频扩散模型在视频编辑方面有所提升,但难以在统一框架内处理指令编辑和多样化任务(例如,添加、删除、更改)。
- VEGGIE通过MLLM理解用户指令并将其与视频内容对齐,生成帧级别的任务查询,再由扩散模型渲染生成编辑后的视频。
- VEGGIE在指令视频编辑、视频对象定位和推理分割方面表现出色,并通过数据合成流程生成高质量的视频编辑训练数据。
📝 摘要(中文)
本文提出VEGGIE,一个基于指令的视频编辑器,通过端到端框架统一视频概念编辑、定位和推理,能够处理多样化的用户指令。VEGGIE首先利用多模态大语言模型(MLLM)理解指令中的用户意图,并将其与视频上下文对齐,生成帧级别的、基于像素空间的任务查询。然后,扩散模型渲染这些规划,生成符合用户意图的编辑视频。为了支持多样化的任务和复杂指令,采用课程学习策略:首先利用大规模指令图像编辑数据对齐MLLM和视频扩散模型,然后在高质量的多任务视频数据上进行端到端微调。此外,还引入了一种新的数据合成流程,通过图像到视频模型注入动态性,将静态图像数据转换为多样化、高质量的视频编辑样本,用于模型训练。VEGGIE在具有不同编辑技巧的指令视频编辑方面表现出强大的性能,作为一个通用模型优于最佳指令基线,而其他模型难以胜任多任务处理。VEGGIE在视频对象定位和推理分割方面也表现出色,而其他基线模型则失败。进一步揭示了多个任务如何相互帮助,并突出了零样本多模态指令和上下文视频编辑等有前景的应用。
🔬 方法详解
问题定义:论文旨在解决视频编辑领域中,现有方法难以统一处理指令编辑和多样化任务的问题。现有方法在处理复杂指令、多任务编辑以及视频对象定位和推理方面存在局限性,缺乏通用性和鲁棒性。
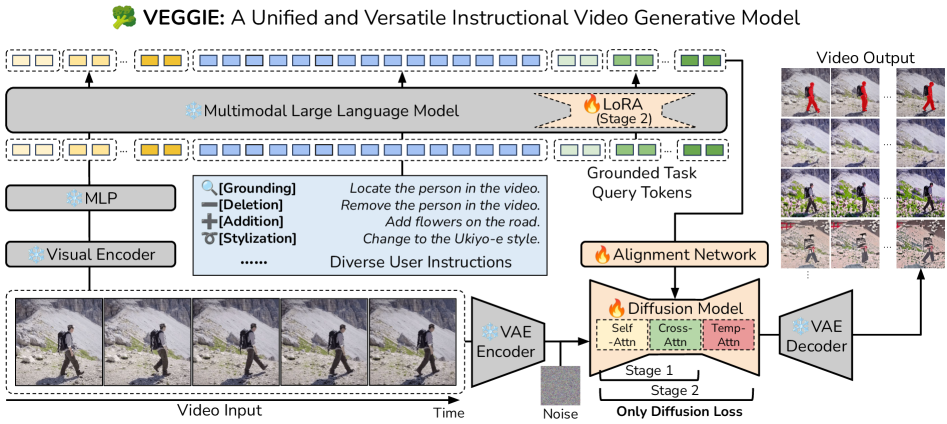
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)理解用户指令,并将其与视频内容对齐,从而生成针对特定帧的任务查询。然后,利用扩散模型根据这些查询生成编辑后的视频。这种方法将指令理解、内容定位和视频生成结合起来,实现了一个统一的视频编辑框架。
技术框架:VEGGIE框架主要包含以下几个模块:1) MLLM指令解析模块:负责解析用户输入的文本指令,并将其与视频内容进行对齐,生成帧级别的任务查询。2) 扩散模型视频生成模块:根据MLLM生成的任务查询,利用扩散模型生成编辑后的视频帧。3) 课程学习训练策略:首先使用大规模图像编辑数据对齐MLLM和扩散模型,然后使用高质量多任务视频数据进行端到端微调。4) 数据合成流程:利用图像到视频模型将静态图像数据转换为动态视频编辑样本,用于模型训练。
关键创新:VEGGIE的关键创新在于:1) 提出了一个统一的框架,能够处理多种视频编辑任务,包括概念编辑、对象定位和推理。2) 利用MLLM进行指令理解和内容对齐,提高了模型对用户意图的理解能力。3) 提出了一个数据合成流程,能够生成高质量的视频编辑训练数据。
关键设计:在训练过程中,采用了课程学习策略,逐步提高模型的复杂度和泛化能力。损失函数方面,可能采用了重建损失、对抗损失等,以保证生成视频的质量和真实性。具体网络结构细节未知,但MLLM和扩散模型的选择和配置是关键。
🖼️ 关键图片


📊 实验亮点
VEGGIE在指令视频编辑任务上优于现有的最佳基线模型,尤其是在处理多任务编辑时表现出色。在视频对象定位和推理分割任务上,VEGGIE也取得了显著的成果,而其他基线模型则难以完成这些任务。这些实验结果表明VEGGIE具有强大的通用性和鲁棒性。
🎯 应用场景
VEGGIE具有广泛的应用前景,包括视频内容创作、视频修复、视频风格迁移、教育视频制作等。该研究可以应用于自动化视频编辑工具,帮助用户更轻松地编辑和修改视频内容。此外,该技术还可以应用于智能监控、机器人导航等领域,提高机器对视频内容的理解和处理能力。
📄 摘要(原文)
Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.