Cream of the Crop: Harvesting Rich, Scalable and Transferable Multi-Modal Data for Instruction Fine-Tuning
作者: Mengyao Lyu, Yan Li, Huasong Zhong, Wenhao Yang, Hui Chen, Jungong Han, Guiguang Ding, Zhenheng Yang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-03-17
备注: update comparison with sota and analysis
💡 一句话要点
提出mmSSR方法,用于高效、可扩展地筛选高质量、多样化的多模态指令微调数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 指令微调 数据选择 数据质量评估 视觉-语言 大型语言模型 数据多样性 模型泛化
📋 核心要点
- 现有指令微调方法依赖大量数据,但数据质量和多样性不足,影响模型稳定性和泛化能力。
- 提出mmSSR方法,通过多模态富评分器和风格器,选择高质量、多样化的指令数据,提升模型性能。
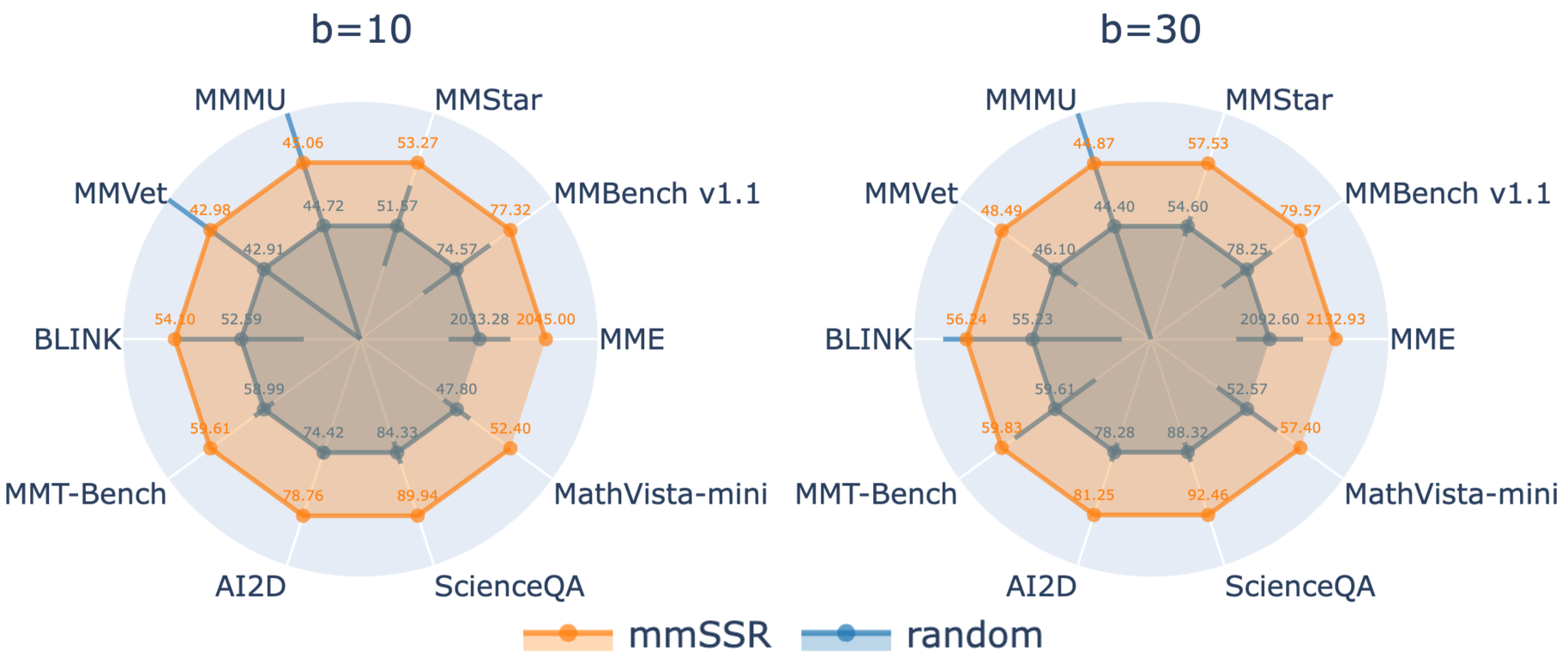
- 实验表明,mmSSR在多个基准测试中优于现有方法,仅用少量数据即可达到接近完整数据集的性能。
📝 摘要(中文)
本文针对多模态大型语言模型(MLLM)指令微调阶段数据选择的重要性和复杂性,提出了多模态富评分器和风格器(mmSSR)。该方法将数据质量细化为14个视觉-语言相关能力,并使用多模态富评分器评估候选数据的能力。为了促进多样性,mmSSR以交互风格作为多样性指标,并使用多模态富风格器识别数据指令模式。mmSSR无需基于嵌入的聚类或贪婪采样,能够高效地扩展到数百万数据,支持通用或特定能力获取的定制,并促进无训练泛化到新的数据筛选领域。在10多个实验设置和14个多模态基准测试中,验证了该方法相对于随机抽样、基线策略和最先进选择方法的持续改进,仅使用260万数据的30%就实现了99.1%的完整性能。
🔬 方法详解
问题定义:多模态大型语言模型(MLLM)的指令微调需要大量高质量的数据。然而,简单地使用所有数据不仅效率低下,而且可能由于数据质量参差不齐而损害模型的性能。现有的数据选择方法,如随机抽样或基于嵌入的聚类,无法保证所选数据的质量和多样性,并且难以扩展到大规模数据集。
核心思路:本文的核心思路是将数据质量分解为多个细粒度的视觉-语言相关能力,并使用专门设计的评分器来评估每个候选数据在这些能力上的表现。同时,为了保证数据的多样性,引入了风格器来识别不同的指令模式。通过结合评分器和风格器,可以筛选出既高质量又多样化的数据,从而提高指令微调的效率和效果。
技术框架:mmSSR方法主要包含两个核心模块:多模态富评分器(mmSR)和多模态富风格器(mmStyler)。mmSR负责评估数据的质量,它将数据质量分解为14个视觉-语言相关能力,并为每个能力训练一个评分模型。mmStyler负责评估数据的多样性,它以交互风格作为多样性指标,并识别不同的指令模式。整个流程首先使用mmSR对所有候选数据进行评分,然后使用mmStyler对数据进行风格分类,最后根据评分和风格信息选择最终的训练数据。
关键创新:mmSSR的关键创新在于将数据质量分解为多个细粒度的能力,并使用专门设计的评分器来评估每个候选数据在这些能力上的表现。这种细粒度的评估方式可以更准确地捕捉数据的质量,从而提高数据选择的准确性。此外,mmSSR还引入了风格器来保证数据的多样性,这有助于提高模型的泛化能力。
关键设计:mmSR使用了多个预训练的多模态模型作为基础模型,并针对每个视觉-语言相关能力微调这些模型,使其能够准确地评估数据在该能力上的表现。mmStyler使用了文本分类模型来识别不同的指令模式。在数据选择阶段,mmSSR根据评分和风格信息,使用一种基于预算约束的优化算法来选择最终的训练数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,mmSSR在10多个实验设置和14个多模态基准测试中,始终优于随机抽样、基线策略和最先进的数据选择方法。最显著的成果是,仅使用260万数据的30%(即78万条数据),mmSSR就实现了99.1%的完整性能,这表明该方法能够显著提高数据利用率,并降低训练成本。
🎯 应用场景
该研究成果可广泛应用于多模态大型语言模型的指令微调,尤其是在数据资源有限或需要快速迭代的场景下。通过高效地筛选高质量、多样化的数据,可以显著降低训练成本,提高模型性能,并加速多模态AI技术的落地应用。未来,该方法还可扩展到其他模态的数据选择,例如音频、视频等。
📄 摘要(原文)
The hypothesis that pretrained large language models (LLMs) necessitate only minimal supervision during the fine-tuning (SFT) stage (Zhou et al., 2024) has been substantiated by recent advancements in data curation and selection research. However, their stability and generalizability are compromised due to the vulnerability to experimental setups and validation protocols, falling short of surpassing random sampling (Diddee & Ippolito, 2024; Xia et al., 2024b). Built upon LLMs, multi-modal LLMs (MLLMs), combined with the sheer token volume and heightened heterogeneity of data sources, amplify both the significance and complexity of data selection. To harvest multi-modal instructional data in a robust and efficient manner, we re-define the granularity of the quality metric by decomposing it into 14 vision-language-related capabilities, and introduce multi-modal rich scorers to evaluate the capabilities of each data candidate. To promote diversity, in light of the inherent objective of the alignment stage, we take interaction style as diversity indicator and use a multi-modal rich styler to identify data instruction patterns. In doing so, our multi-modal rich scorers and styler (mmSSR) guarantee that high-scoring information is conveyed to users in diversified forms. Free from embedding-based clustering or greedy sampling, mmSSR efficiently scales to millions of data with varying budget constraints, supports customization for general or specific capability acquisition, and facilitates training-free generalization to new domains for curation. Across 10+ experimental settings, validated by 14 multi-modal benchmarks, we demonstrate consistent improvements over random sampling, baseline strategies and state-of-the-art selection methods, achieving 99.1% of full performance with only 30% of the 2.6M data.