DeepPerception: Advancing R1-like Cognitive Visual Perception in MLLMs for Knowledge-Intensive Visual Grounding
作者: Xinyu Ma, Ziyang Ding, Zhicong Luo, Chi Chen, Zonghao Guo, Derek F. Wong, Xiaoyi Feng, Maosong Sun
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-03-17 (更新: 2025-03-18)
🔗 代码/项目: GITHUB
💡 一句话要点
DeepPerception:提升MLLM在知识密集型视觉定位中的认知视觉感知能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉定位 知识密集型任务 认知视觉感知 强化学习 数据合成 跨领域泛化
📋 核心要点
- 现有多模态大语言模型(MLLM)在利用领域知识进行细粒度视觉区分方面存在不足,无法有效整合推理与视觉感知。
- DeepPerception通过自动数据合成和两阶段训练框架,提升MLLM的认知视觉感知能力,从而解决知识密集型视觉定位(KVG)任务。
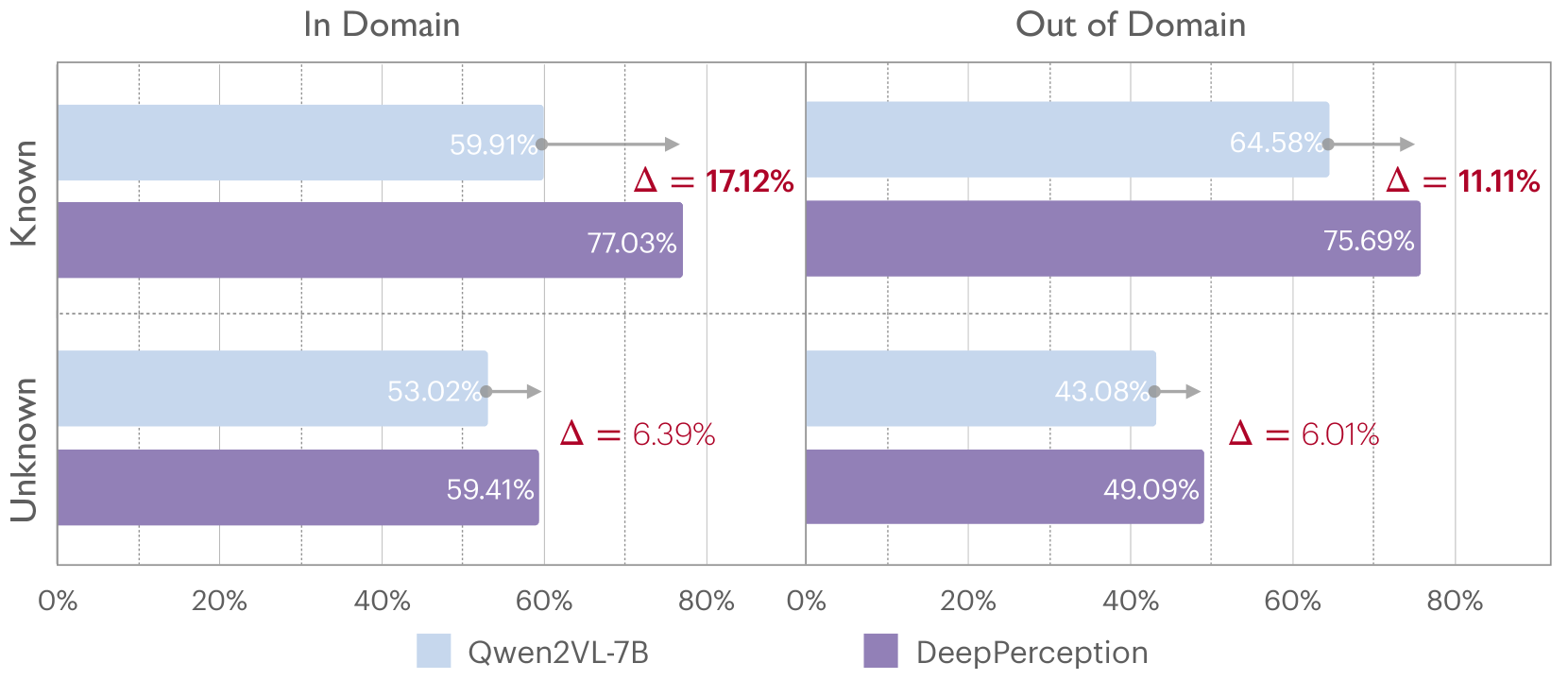
- 实验结果表明,DeepPerception在KVG-Bench上显著优于现有方法,准确率提升8.08%,跨领域泛化能力提升4.60%。
📝 摘要(中文)
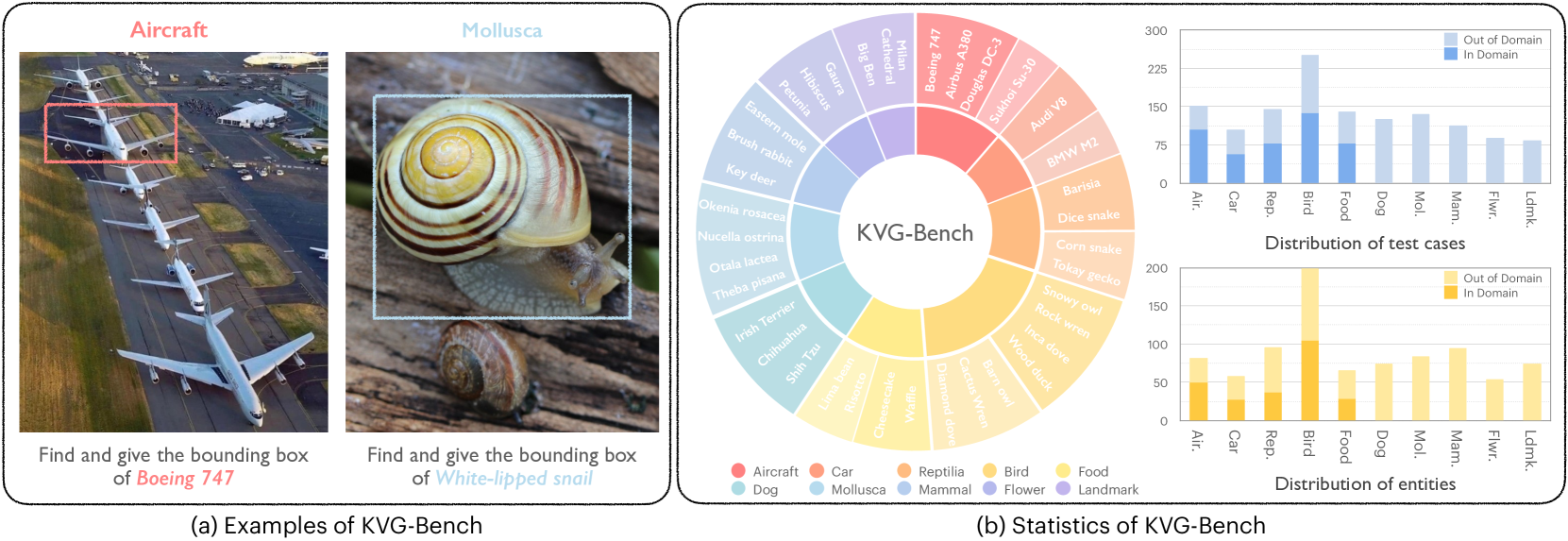
本文提出了一种名为知识密集型视觉定位(KVG)的新型视觉定位任务,该任务需要细粒度的感知和特定领域的知识整合。为了解决KVG的挑战,本文提出DeepPerception,一种增强了认知视觉感知能力的MLLM。该方法包括:(1)一个自动数据合成管道,用于生成高质量、知识对齐的训练样本;(2)一个两阶段训练框架,结合了用于认知推理支架的监督微调和用于优化感知-认知协同的强化学习。为了评估性能,本文引入了KVG-Bench,一个包含10个领域和1.3K个手动策划的测试用例的综合数据集。实验结果表明,DeepPerception显著优于直接微调,在KVG-Bench上实现了+8.08%的准确率提升,并且比基线方法表现出+4.60%的卓越跨领域泛化能力。研究结果强调了将认知过程整合到MLLM中以实现类人视觉感知的重要性,并为多模态推理研究开辟了新的方向。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在知识密集型视觉定位(KVG)任务中的不足。现有MLLM虽然拥有丰富的知识,但难以将知识有效地融入到视觉感知中,导致在需要细粒度视觉区分和领域知识整合的任务中表现不佳。现有方法通常采用直接微调,缺乏对认知推理过程的建模和优化。
核心思路:论文的核心思路是通过增强MLLM的认知视觉感知能力,使其能够像人类专家一样,利用领域知识来提升视觉感知能力。具体来说,通过构建高质量的知识对齐训练数据,并采用两阶段训练框架,引导模型学习如何将视觉信息与领域知识进行有效整合,从而提升在KVG任务中的表现。
技术框架:DeepPerception的技术框架主要包含两个部分:数据合成管道和两阶段训练框架。数据合成管道负责自动生成高质量、知识对齐的训练样本,为模型的训练提供充足的数据支持。两阶段训练框架首先使用监督微调(SFT)来构建认知推理的支架,然后使用强化学习(RL)来优化感知和认知之间的协同作用。
关键创新:论文的关键创新在于提出了一个能够有效提升MLLM认知视觉感知能力的方法。该方法通过自动数据合成和两阶段训练,使得模型能够更好地利用领域知识进行视觉推理。此外,论文还提出了KVG-Bench数据集,为评估模型在知识密集型视觉定位任务中的性能提供了一个标准化的平台。
关键设计:在数据合成方面,论文设计了一个自动化的流程,能够根据给定的领域知识生成高质量的图像-文本对。在两阶段训练方面,SFT阶段使用交叉熵损失函数来训练模型,RL阶段使用奖励函数来鼓励模型生成更准确、更符合领域知识的答案。具体的网络结构细节(如backbone选择)在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
DeepPerception在KVG-Bench数据集上取得了显著的性能提升,相比直接微调的方法,准确率提升了8.08%。此外,DeepPerception在跨领域泛化能力方面也表现出色,相比基线方法提升了4.60%。这些实验结果表明,DeepPerception能够有效地提升MLLM在知识密集型视觉定位任务中的表现。
🎯 应用场景
DeepPerception在医疗诊断、工业检测、农业分析等领域具有广泛的应用前景。例如,在医疗诊断中,可以帮助医生识别医学影像中的细微病灶;在工业检测中,可以用于检测产品表面的缺陷;在农业分析中,可以用于识别农作物的病虫害。该研究有助于提升人工智能在复杂视觉任务中的表现,推动相关领域的智能化发展。
📄 摘要(原文)
Human experts excel at fine-grained visual discrimination by leveraging domain knowledge to refine perceptual features, a capability that remains underdeveloped in current Multimodal Large Language Models (MLLMs). Despite possessing vast expert-level knowledge, MLLMs struggle to integrate reasoning into visual perception, often generating direct responses without deeper analysis. To bridge this gap, we introduce knowledge-intensive visual grounding (KVG), a novel visual grounding task that requires both fine-grained perception and domain-specific knowledge integration. To address the challenges of KVG, we propose DeepPerception, an MLLM enhanced with cognitive visual perception capabilities. Our approach consists of (1) an automated data synthesis pipeline that generates high-quality, knowledge-aligned training samples, and (2) a two-stage training framework combining supervised fine-tuning for cognitive reasoning scaffolding and reinforcement learning to optimize perception-cognition synergy. To benchmark performance, we introduce KVG-Bench a comprehensive dataset spanning 10 domains with 1.3K manually curated test cases. Experimental results demonstrate that DeepPerception significantly outperforms direct fine-tuning, achieving +8.08\% accuracy improvements on KVG-Bench and exhibiting +4.60\% superior cross-domain generalization over baseline approaches. Our findings highlight the importance of integrating cognitive processes into MLLMs for human-like visual perception and open new directions for multimodal reasoning research. The data, codes, and models are released at https://github.com/thunlp/DeepPerception.