NuPlanQA: A Large-Scale Dataset and Benchmark for Multi-View Driving Scene Understanding in Multi-Modal Large Language Models
作者: Sung-Yeon Park, Can Cui, Yunsheng Ma, Ahmadreza Moradipari, Rohit Gupta, Kyungtae Han, Ziran Wang
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-03-17 (更新: 2025-08-05)
🔗 代码/项目: GITHUB
💡 一句话要点
提出NuPlanQA数据集与BEV-LLM模型,提升多模态大语言模型在自动驾驶场景理解能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 自动驾驶 场景理解 鸟瞰图 视觉问答
📋 核心要点
- 现有多模态大语言模型在驾驶场景理解方面能力不足,尤其是在处理多视角信息时面临挑战。
- 提出NuPlanQA数据集和BEV-LLM模型,通过大规模数据和BEV特征融合提升模型对驾驶场景的理解。
- 实验表明,BEV-LLM在多个子任务上优于其他模型,验证了BEV集成在驾驶场景理解中的有效性。
📝 摘要(中文)
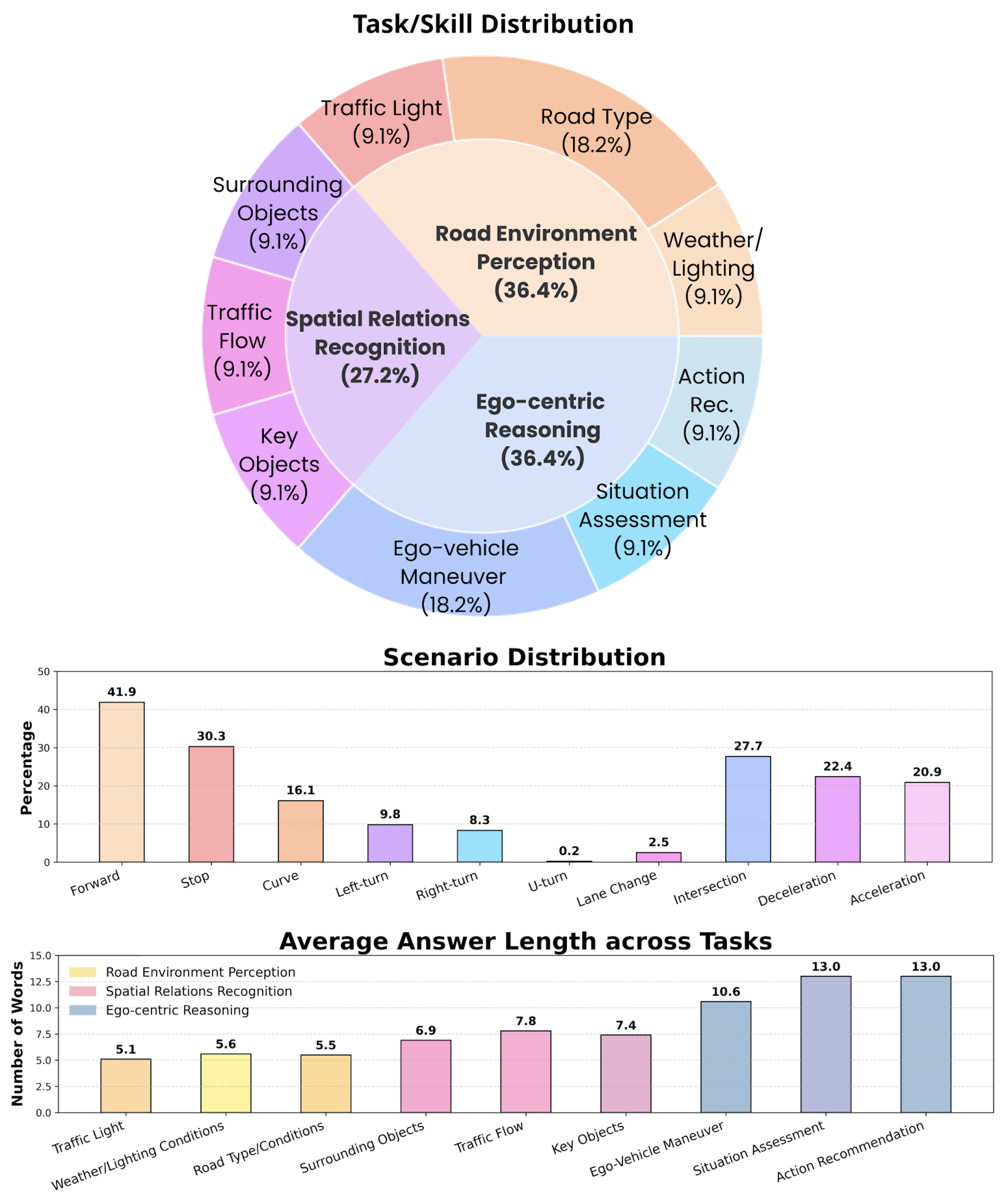
本文提出了NuPlanQA-Eval,一个用于评估多模态大语言模型在驾驶场景理解能力的多视角、多模态评估基准。为了进一步支持模型在多视角驾驶场景中的泛化能力,还提出了NuPlanQA-1M,一个包含100万个真实世界视觉问答(VQA)对的大规模数据集。为了对交通场景进行上下文感知的分析,该数据集被分为九个子任务,涵盖了道路环境感知、空间关系识别和以自我为中心的推理这三个核心技能。此外,本文还提出了BEV-LLM,将来自多视角图像的鸟瞰图(BEV)特征集成到多模态大语言模型中。评估结果揭示了现有模型在驾驶场景特定感知和以自我为中心的空间推理方面面临的关键挑战。相比之下,BEV-LLM展示了对该领域的显著适应性,在九个子任务中的六个中优于其他模型。这些发现强调了BEV集成如何增强多视角多模态大语言模型,同时也指出了有效适应驾驶场景需要进一步改进的关键领域。为了促进进一步的研究,NuPlanQA已公开发布。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLMs)在各种领域都表现出了强大的性能,但它们理解驾驶场景的能力仍有待验证。驾驶场景的复杂性,特别是多视角信息的处理,对现有的MLLMs提出了重大挑战。因此,需要一个专门针对驾驶场景的多视角、多模态评估基准和数据集,以推动该领域的发展。
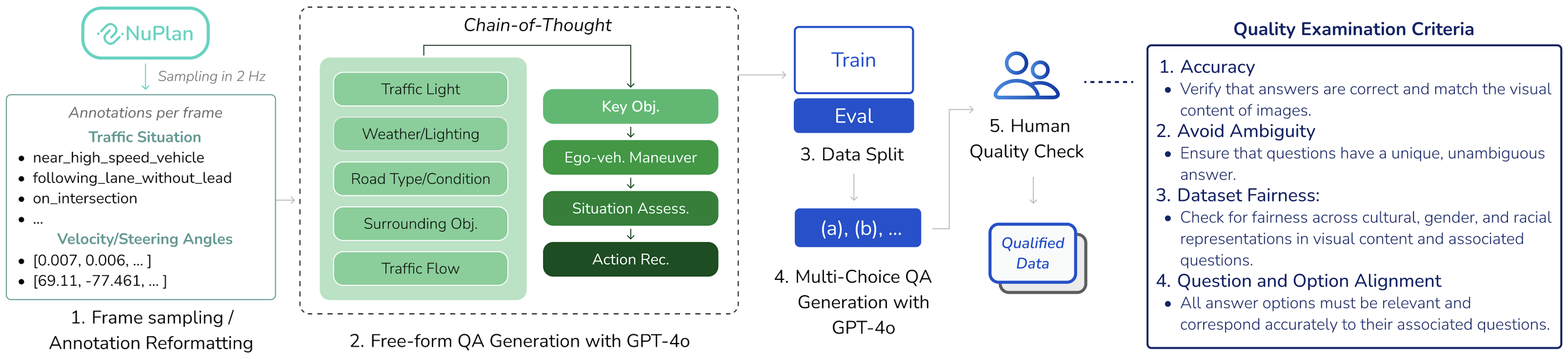
核心思路:本文的核心思路是将多视角图像信息转换为鸟瞰图(BEV)特征,然后将这些BEV特征融入到MLLM中。这种方法旨在利用BEV表示来更好地捕捉驾驶场景中的空间关系和环境信息,从而提高MLLM的理解能力。通过大规模的视觉问答数据集进行训练和评估,可以有效地提升模型在驾驶场景中的泛化能力。
技术框架:整体框架包括以下几个主要模块:1) 多视角图像输入;2) BEV特征提取模块,将多视角图像转换为BEV表示;3) BEV特征融合模块,将BEV特征与文本信息进行融合;4) MLLM,利用融合后的特征进行问答。该框架通过端到端的方式进行训练,以优化模型在驾驶场景理解任务上的性能。
关键创新:最重要的技术创新点在于BEV特征的集成。与直接使用原始图像特征相比,BEV特征能够更好地捕捉驾驶场景中的空间布局和交通参与者的位置关系。此外,NuPlanQA-1M数据集的构建也为该领域的研究提供了宝贵的数据资源。
关键设计:BEV特征提取模块可以使用现有的BEV感知模型,例如Lift-Splat-Shoot。BEV特征融合模块可以使用注意力机制或其他融合方法,将BEV特征与文本信息进行有效融合。MLLM可以使用现有的预训练模型,例如LLaMA或GPT系列模型。损失函数可以使用交叉熵损失或其他适用于视觉问答任务的损失函数。具体参数设置需要根据实际情况进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BEV-LLM在NuPlanQA-Eval基准测试中表现出色,在九个子任务中的六个中优于其他模型。这证明了BEV集成在增强多视角MLLM在驾驶场景理解方面的有效性。具体性能数据在论文中给出,与其他基线模型进行了详细的对比分析,展示了显著的性能提升。
🎯 应用场景
该研究成果可应用于自动驾驶、高级驾驶辅助系统(ADAS)、智能交通管理等领域。通过提升模型对驾驶场景的理解能力,可以提高自动驾驶系统的安全性、可靠性和智能化水平,例如更准确地识别交通信号、预测其他车辆的行驶轨迹、以及进行更合理的驾驶决策。未来,该技术还可以扩展到其他需要多视角信息理解的场景,例如机器人导航和智能监控。
📄 摘要(原文)
Recent advances in multi-modal large language models (MLLMs) have demonstrated strong performance across various domains; however, their ability to comprehend driving scenes remains less proven. The complexity of driving scenarios, which includes multi-view information, poses significant challenges for existing MLLMs. In this paper, we introduce NuPlanQA-Eval, a multi-view, multi-modal evaluation benchmark for driving scene understanding. To further support generalization to multi-view driving scenarios, we also propose NuPlanQA-1M, a large-scale dataset comprising 1M real-world visual question-answering (VQA) pairs. For context-aware analysis of traffic scenes, we categorize our dataset into nine subtasks across three core skills: Road Environment Perception, Spatial Relations Recognition, and Ego-Centric Reasoning. Furthermore, we present BEV-LLM, integrating Bird's-Eye-View (BEV) features from multi-view images into MLLMs. Our evaluation results reveal key challenges that existing MLLMs face in driving scene-specific perception and spatial reasoning from ego-centric perspectives. In contrast, BEV-LLM demonstrates remarkable adaptability to this domain, outperforming other models in six of the nine subtasks. These findings highlight how BEV integration enhances multi-view MLLMs while also identifying key areas that require further refinement for effective adaptation to driving scenes. To facilitate further research, we publicly release NuPlanQA at https://github.com/sungyeonparkk/NuPlanQA.