DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
作者: Chengxuan Qian, Shuo Xing, Shawn Li, Yue Zhao, Zhengzhong Tu
分类: cs.CV
发布日期: 2025-03-14 (更新: 2025-09-29)
备注: Project website: https://taco-group.github.io/DecAlign/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
DecAlign:通过分层跨模态对齐解耦多模态表征学习,提升模态融合效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 跨模态对齐 表征解耦 最优传输 Transformer
📋 核心要点
- 现有方法难以有效处理多模态数据间的异质性,导致跨模态协作和集成效果不佳。
- DecAlign通过分层跨模态对齐,将多模态表征解耦为模态唯一和模态通用特征。
- 实验结果表明,DecAlign在多个基准数据集上优于现有方法,提升了跨模态对齐和语义一致性。
📝 摘要(中文)
多模态表征学习旨在捕捉跨模态的共享和互补语义信息。然而,不同模态的内在异质性给有效的跨模态协作和集成带来了巨大挑战。为了解决这个问题,我们提出了一种新的分层跨模态对齐框架DecAlign,旨在将多模态表征解耦为模态唯一(异构)特征和模态通用(同构)特征。为了处理异质性,我们采用了一种原型引导的最优传输对齐策略,利用高斯混合模型和多边际传输计划,从而减轻分布差异,同时保留模态唯一特征。为了加强同质性,我们通过对齐潜在分布匹配和最大均值差异正则化来确保跨模态的语义一致性。此外,我们还引入了一个多模态Transformer来增强高层语义特征融合,从而进一步减少跨模态不一致性。我们在四个广泛使用的多模态基准数据集上进行了大量实验,结果表明DecAlign在五个指标上始终优于现有的最先进方法。这些结果突出了DecAlign在增强卓越的跨模态对齐和语义一致性,同时保留模态唯一特征方面的有效性,标志着多模态表征学习场景的重大进展。
🔬 方法详解
问题定义:多模态表征学习旨在融合来自不同模态的信息,但由于各模态的异质性(例如,图像和文本的分布差异),直接融合会导致性能下降。现有方法难以在对齐不同模态的同时,保留各模态的独有特征,从而限制了模型的表达能力。
核心思路:DecAlign的核心思想是将多模态表征解耦为模态通用特征和模态唯一特征。通过分别处理这两种特征,可以更好地对齐不同模态的信息,同时保留各模态的独特性。这种解耦策略允许模型更灵活地学习跨模态关系,并提高整体性能。
技术框架:DecAlign框架包含以下几个主要模块:1) 特征提取器:用于从每个模态中提取特征。2) 模态唯一特征对齐模块:使用原型引导的最优传输对齐策略,减轻分布差异,保留模态独有特征。3) 模态通用特征对齐模块:通过对齐潜在分布匹配和最大均值差异正则化,确保跨模态的语义一致性。4) 多模态Transformer:增强高层语义特征融合,减少跨模态不一致性。
关键创新:DecAlign的关键创新在于其分层跨模态对齐策略。通过将特征解耦为模态通用和模态唯一两部分,并分别进行对齐,可以更有效地处理模态异质性。原型引导的最优传输对齐策略和潜在分布匹配的结合,进一步提升了对齐的准确性和鲁棒性。
关键设计:在模态唯一特征对齐中,使用高斯混合模型对特征分布进行建模,并利用多边际传输计划进行最优传输。在模态通用特征对齐中,使用最大均值差异(MMD)正则化来约束潜在分布的相似性。多模态Transformer采用标准的Transformer架构,用于融合高层语义特征。损失函数包括最优传输损失、MMD损失和Transformer的交叉熵损失等。
🖼️ 关键图片
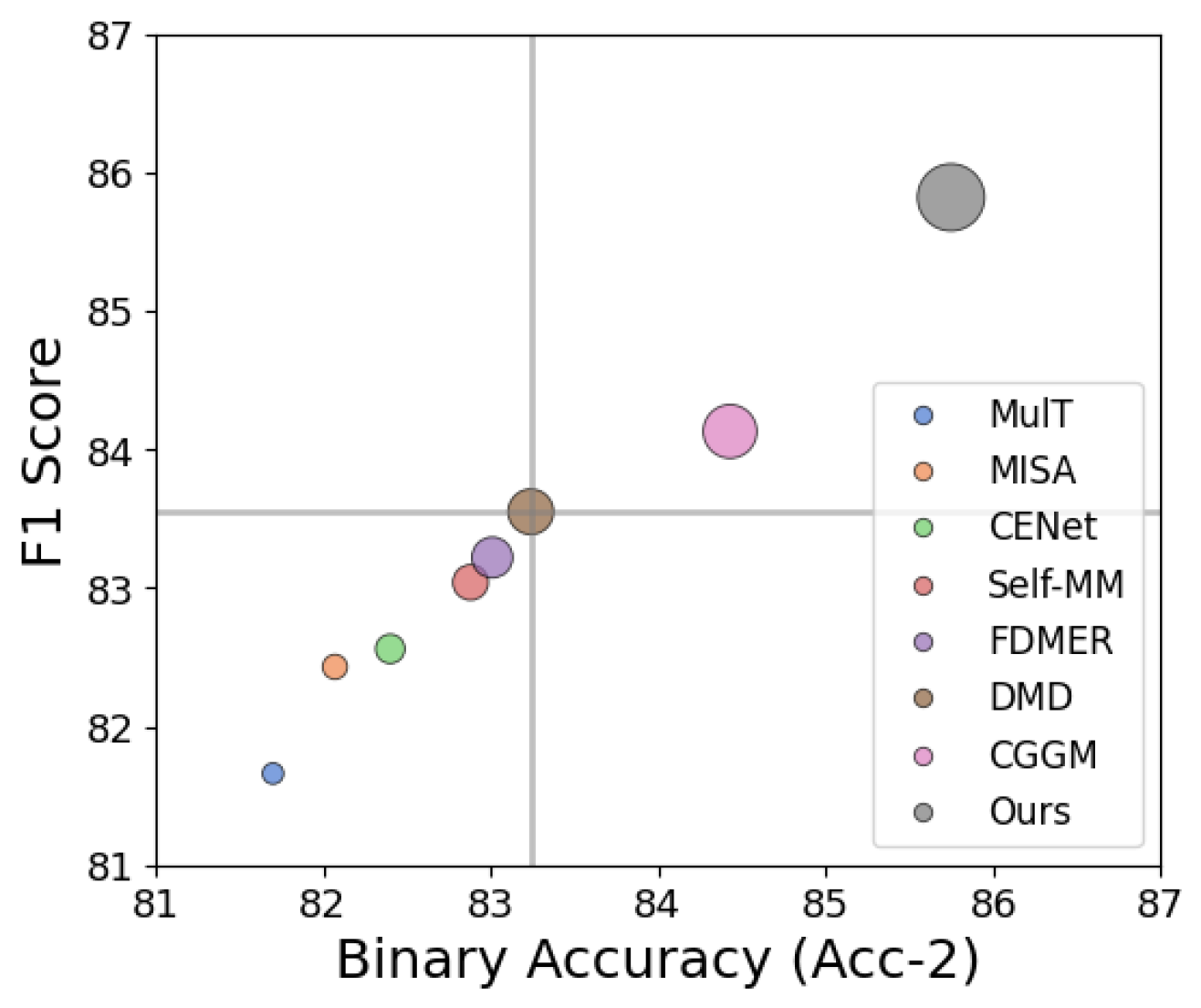
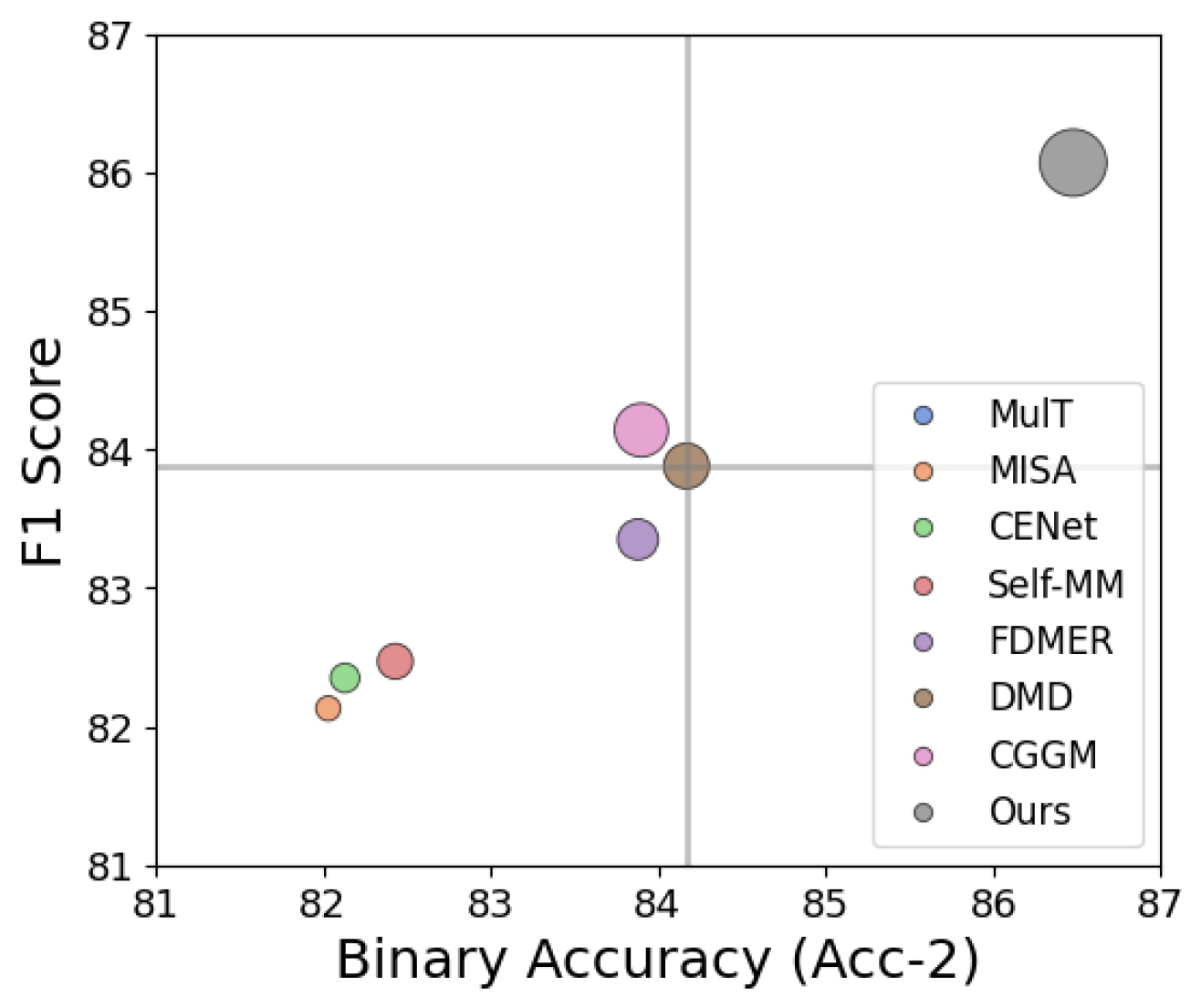
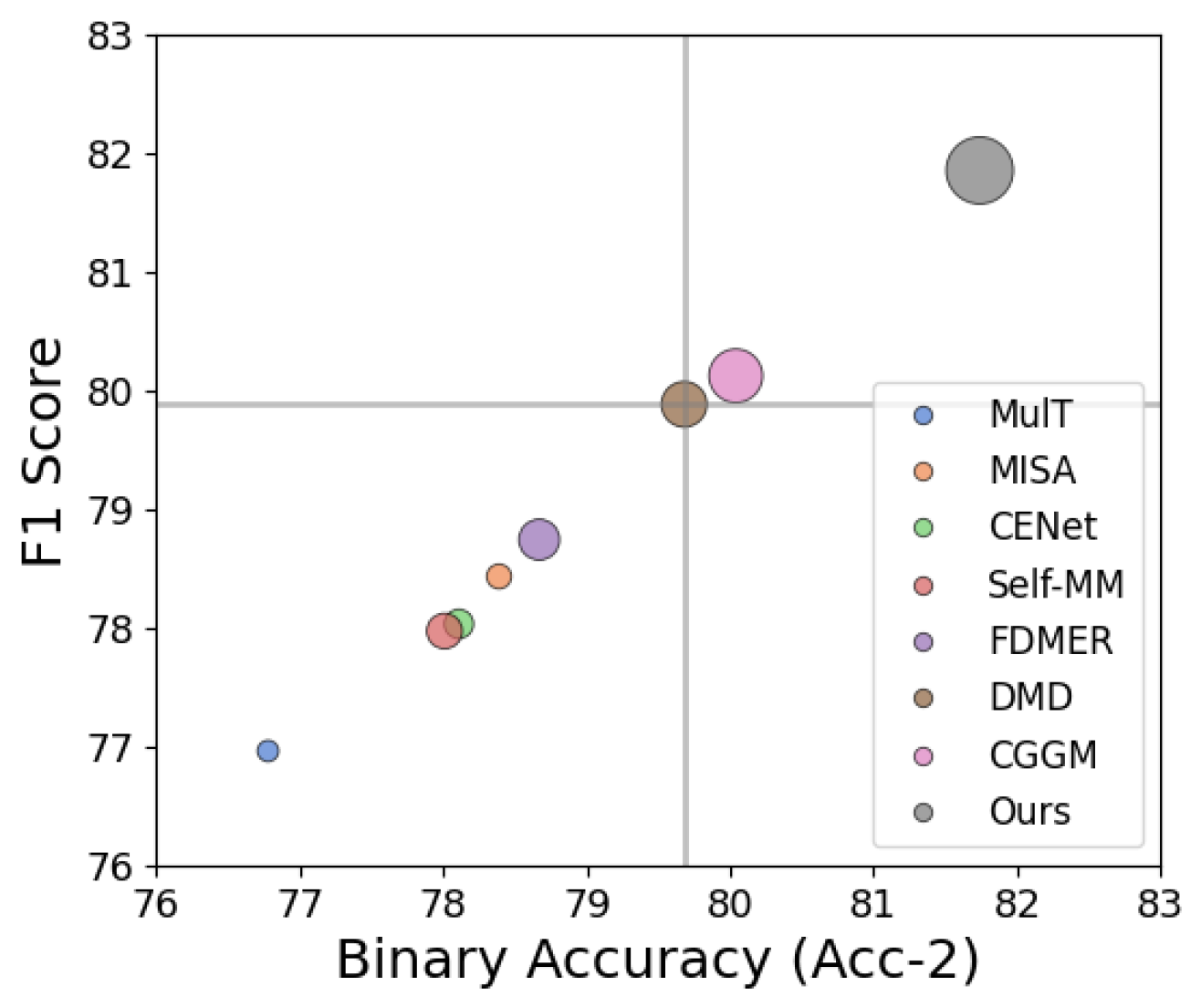
📊 实验亮点
DecAlign在四个广泛使用的多模态基准数据集上进行了评估,包括CMU-MOSI、CMU-MOSEI、SIMS和UR-FUNNY。实验结果表明,DecAlign在五个指标上始终优于现有的最先进方法。例如,在CMU-MOSI数据集上,DecAlign在Accuracy指标上取得了显著提升,证明了其在跨模态对齐和语义一致性方面的有效性。
🎯 应用场景
DecAlign可应用于各种多模态学习任务,例如多模态情感分析、跨模态检索、视频理解和多模态机器翻译等。通过提升跨模态对齐和语义一致性,DecAlign可以提高这些任务的性能,并为未来的多模态研究提供新的思路。该方法在人机交互、智能客服、内容创作等领域具有潜在的应用价值。
📄 摘要(原文)
Multimodal representation learning aims to capture both shared and complementary semantic information across multiple modalities. However, the intrinsic heterogeneity of diverse modalities presents substantial challenges to achieve effective cross-modal collaboration and integration. To address this, we introduce DecAlign, a novel hierarchical cross-modal alignment framework designed to decouple multimodal representations into modality-unique (heterogeneous) and modality-common (homogeneous) features. For handling heterogeneity, we employ a prototype-guided optimal transport alignment strategy leveraging gaussian mixture modeling and multi-marginal transport plans, thus mitigating distribution discrepancies while preserving modality-unique characteristics. To reinforce homogeneity, we ensure semantic consistency across modalities by aligning latent distribution matching with Maximum Mean Discrepancy regularization. Furthermore, we incorporate a multimodal transformer to enhance high-level semantic feature fusion, thereby further reducing cross-modal inconsistencies. Our extensive experiments on four widely used multimodal benchmarks demonstrate that DecAlign consistently outperforms existing state-of-the-art methods across five metrics. These results highlight the efficacy of DecAlign in enhancing superior cross-modal alignment and semantic consistency while preserving modality-unique features, marking a significant advancement in multimodal representation learning scenarios. Our project page is at https://taco-group.github.io/DecAlign.