Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
作者: Weiming Ren, Wentao Ma, Huan Yang, Cong Wei, Ge Zhang, Wenhu Chen
分类: cs.CV
发布日期: 2025-03-14 (更新: 2025-07-16)
备注: ICCV 2025 Camera Ready Version. Project Page: https://tiger-ai-lab.github.io/Vamba/
💡 一句话要点
Vamba:混合Mamba-Transformer模型,用于理解小时级长视频
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 Mamba模型 Transformer模型 混合架构 线性复杂度
📋 核心要点
- Transformer模型处理长视频时,自注意力机制的平方复杂度导致计算成本过高,限制了其应用。
- VAMBA模型采用Mamba-2块以线性复杂度编码视频token,无需token缩减即可处理更长的视频序列。
- 实验表明,VAMBA在长视频理解任务中显著降低了GPU内存占用,提升了训练速度,并提高了准确率。
📝 摘要(中文)
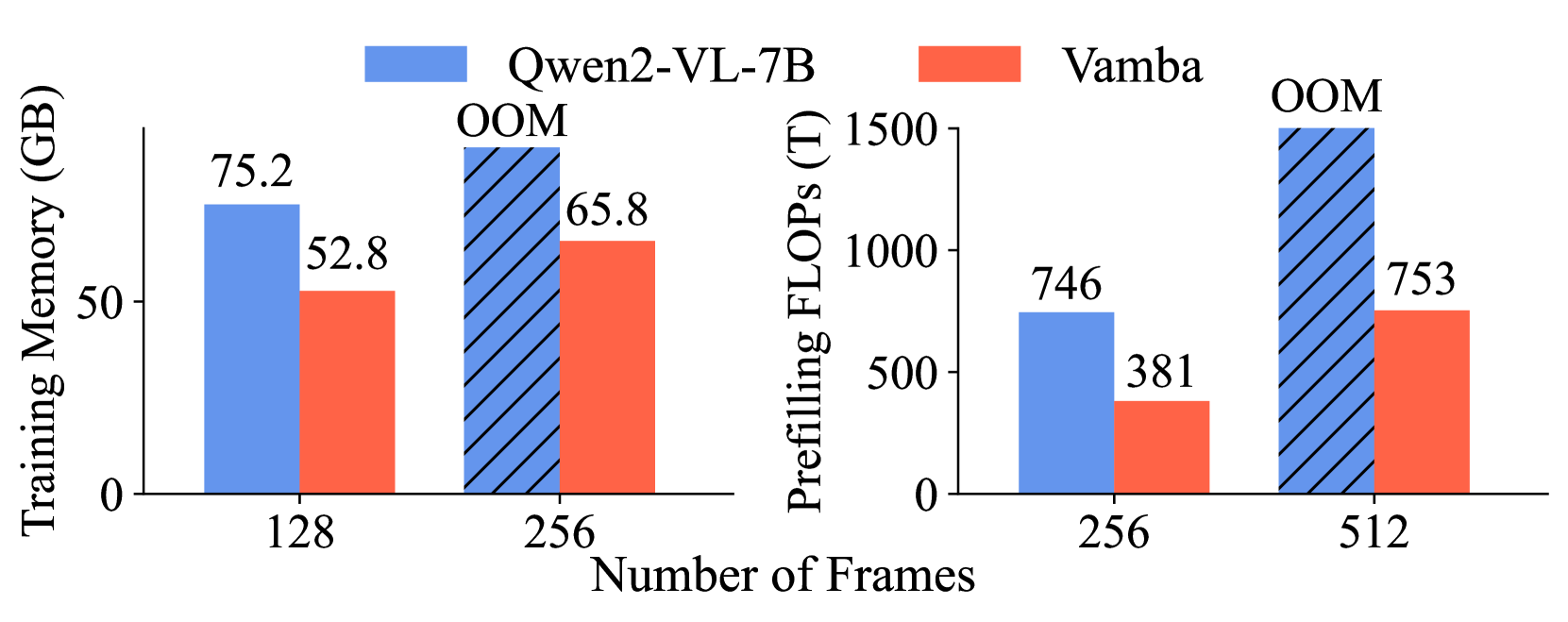
基于Transformer的大型多模态模型(LMMs)由于因果自注意力机制的平方复杂度,难以处理小时级长视频输入,导致训练和推理期间计算成本高昂。现有的基于token压缩的方法虽然减少了视频token的数量,但通常会造成信息丢失,并且对于极长的序列仍然效率低下。本文探索了一个正交的方向,构建了一个混合Mamba-Transformer模型(VAMBA),该模型采用Mamba-2块以线性复杂度编码视频token。在不进行任何token缩减的情况下,VAMBA可以在单个GPU上编码超过1024帧(640x360),而基于Transformer的模型只能编码256帧。在长视频输入上,VAMBA在训练和推理期间至少减少50%的GPU内存使用量,并且每个训练步骤的速度几乎是基于Transformer的LMM的两倍。实验结果表明,VAMBA在具有挑战性的小时级视频理解基准LVBench上,比之前的有效视频LMM提高了4.3%的准确率,并在广泛的长短视频理解任务中保持了强大的性能。
🔬 方法详解
问题定义:现有基于Transformer的大型多模态模型在处理小时级长视频时面临计算瓶颈。自注意力机制的复杂度随序列长度呈平方增长,导致训练和推理成本过高。现有的token压缩方法虽然能减少计算量,但会损失关键信息,且对于极长序列效果不佳。
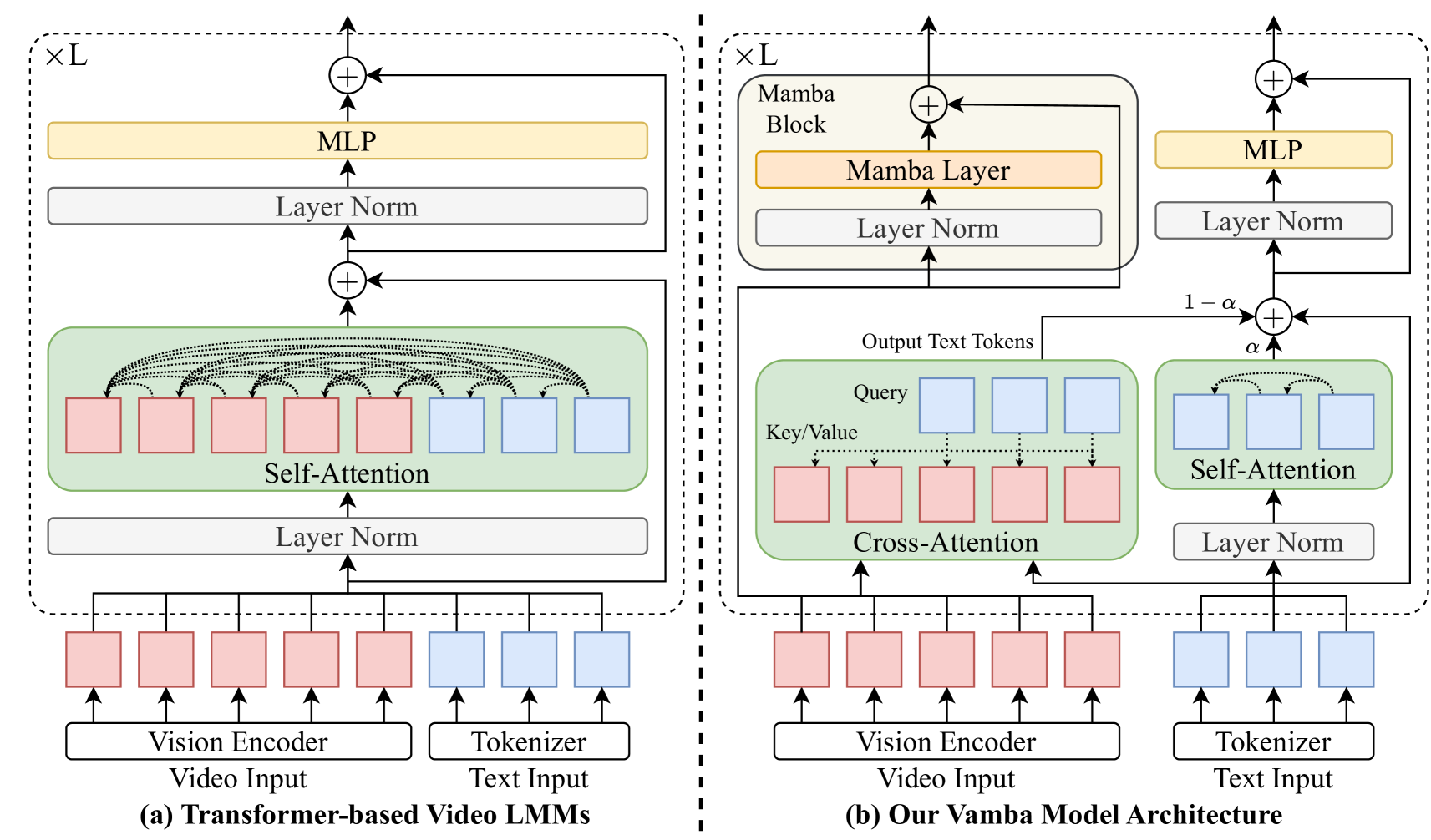
核心思路:VAMBA的核心思路是利用Mamba模型的线性复杂度特性,替代Transformer中的自注意力机制来编码视频token。Mamba模型通过选择性状态空间模型(Selective State Space Model, S6)实现高效的序列建模,避免了全局注意力计算,从而降低了计算复杂度。
技术框架:VAMBA采用混合架构,将Mamba-2块与Transformer结合。具体而言,视频帧首先被编码为视觉token,然后输入到Mamba-2块中进行序列建模,提取时序特征。提取的特征再输入到Transformer解码器中,用于完成下游任务,例如视频问答、视频摘要等。
关键创新:VAMBA的关键创新在于使用Mamba-2块替代Transformer中的自注意力机制,从而将计算复杂度从平方降低到线性。这种混合架构既保留了Transformer强大的表示能力,又克服了其在长序列处理上的局限性。
关键设计:VAMBA使用Mamba-2作为其核心序列建模模块,Mamba-2是Mamba模型的改进版本,具有更高的效率和性能。论文中没有明确提及损失函数和网络结构的具体参数设置,但强调了Mamba-2块在整体架构中的重要作用。
🖼️ 关键图片

📊 实验亮点
VAMBA在LVBench长视频理解基准测试中,相比之前的有效视频LMM,准确率提高了4.3%。在长视频输入上,VAMBA在训练和推理期间至少减少了50%的GPU内存使用量,并且每个训练步骤的速度几乎是基于Transformer的LMM的两倍。这些结果表明VAMBA在长视频处理方面具有显著的优势。
🎯 应用场景
VAMBA模型在长视频理解领域具有广泛的应用前景,例如智能监控、视频会议分析、电影内容理解、在线教育等。该模型能够高效处理长时间的视频数据,提取关键信息,为各种下游任务提供支持,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
State-of-the-art transformer-based large multimodal models (LMMs) struggle to handle hour-long video inputs due to the quadratic complexity of the causal self-attention operations, leading to high computational costs during training and inference. Existing token compression-based methods reduce the number of video tokens but often incur information loss and remain inefficient for extremely long sequences. In this paper, we explore an orthogonal direction to build a hybrid Mamba-Transformer model (VAMBA) that employs Mamba-2 blocks to encode video tokens with linear complexity. Without any token reduction, VAMBA can encode more than 1024 frames (640$\times$360) on a single GPU, while transformer-based models can only encode 256 frames. On long video input, VAMBA achieves at least 50% reduction in GPU memory usage during training and inference, and nearly doubles the speed per training step compared to transformer-based LMMs. Our experimental results demonstrate that VAMBA improves accuracy by 4.3% on the challenging hour-long video understanding benchmark LVBench over prior efficient video LMMs, and maintains strong performance on a broad spectrum of long and short video understanding tasks.