HiTVideo: Hierarchical Tokenizers for Enhancing Text-to-Video Generation with Autoregressive Large Language Models
作者: Ziqin Zhou, Yifan Yang, Yuqing Yang, Tianyu He, Houwen Peng, Kai Qiu, Qi Dai, Lili Qiu, Chong Luo, Lingqiao Liu
分类: cs.CV, cs.AI
发布日期: 2025-03-14
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
HiTVideo:用于增强自回归大语言模型文本生成视频的分层 Tokenizer
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本生成视频 视频 Tokenizer 分层编码 3D VAE 自回归模型
📋 核心要点
- 现有文本生成视频方法难以有效编码视频数据,面临时空复杂性、冗余和领域差距等挑战。
- HiTVideo 采用分层 tokenizer 结构,利用 3D 因果 VAE 将视频编码为多层代码本,平衡压缩效率和重建质量。
- 实验表明,HiTVideo 能够有效编码长视频序列,显著降低每像素比特数,同时保持良好的重建质量。
📝 摘要(中文)
文本生成视频由于视频数据在时间和空间维度上的复杂性而面临巨大挑战。这种复杂性引入了额外的冗余、突变以及语言和视觉 token 之间的领域差距。为了应对这些挑战,需要一种有效的视频 tokenizer,它能够高效地编码视频数据,同时保留必要的语义和时空信息,从而充当文本和视觉之间的关键桥梁。受 VQ-VAE-2 和传统动画工作流程的启发,我们提出了 HiTVideo,一种用于文本生成视频的分层 tokenizer。它利用具有多层离散 token 框架的 3D 因果 VAE,将视频内容编码为分层结构的代码本。较高层以较高的压缩率捕获语义信息,而较低层则侧重于细粒度的时空细节,从而在压缩效率和重建质量之间取得平衡。我们的方法有效地编码了更长的视频序列(例如,8 秒,64 帧),与基线 tokenizer 相比,每像素比特数 (bpp) 降低了约 70%,同时保持了具有竞争力的重建质量。我们探讨了压缩和重建之间的权衡,同时强调了高压缩语义 token 在文本生成视频任务中的优势。HiTVideo 旨在解决现有视频 tokenizer 在文本生成视频任务中的潜在局限性,力求更高的压缩率并简化语言引导下的大语言模型建模,从而为推进文本生成视频提供一个可扩展且有前景的框架。
🔬 方法详解
问题定义:文本生成视频任务中,如何高效且完整地编码视频数据,是现有方法面临的关键问题。视频数据固有的时空复杂性、冗余信息以及语言和视觉模态间的差异,使得设计有效的视频 tokenizer 成为一项挑战。现有 tokenizer 往往难以在压缩效率和信息保留之间取得平衡,限制了文本生成视频模型的性能。
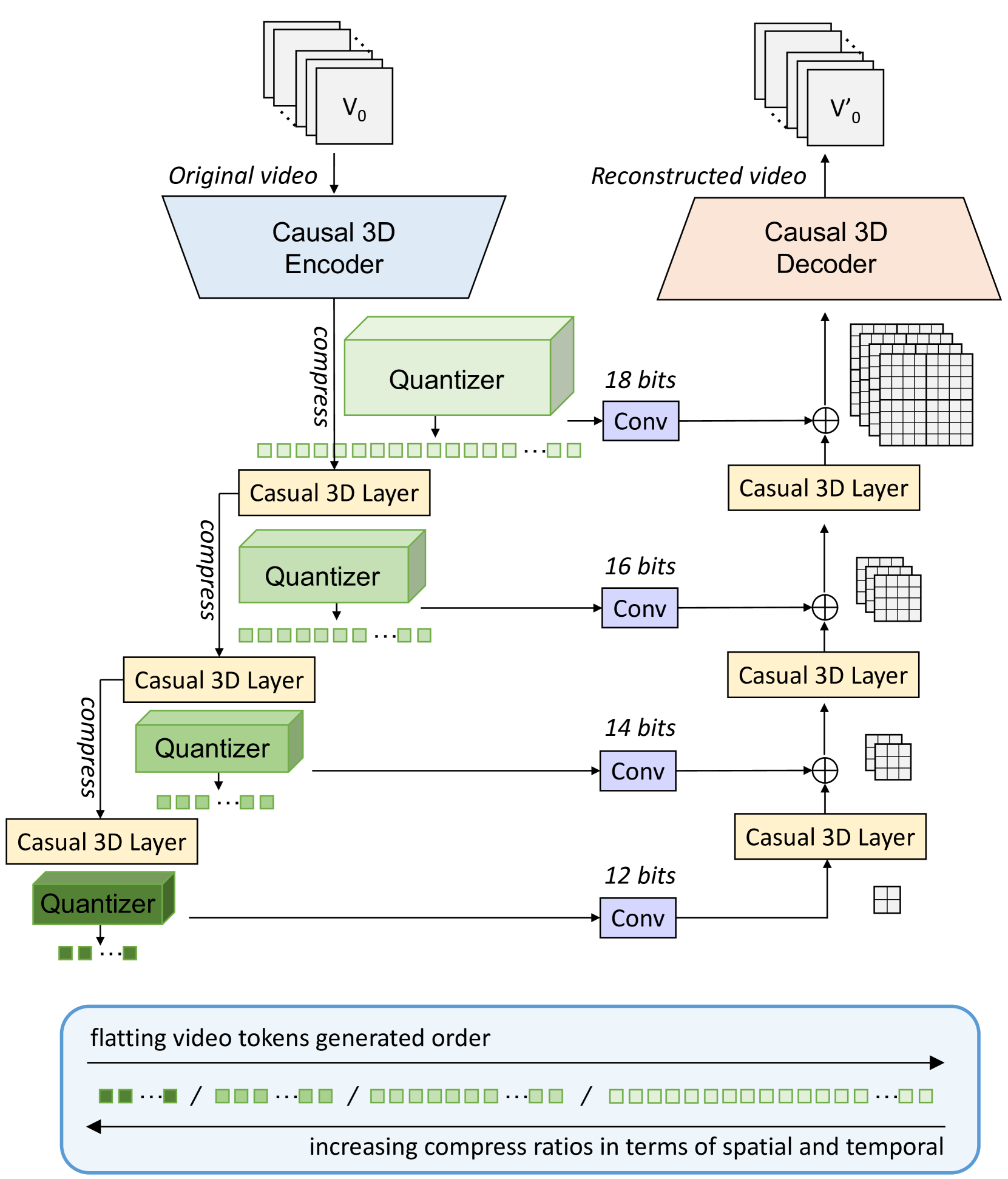
核心思路:HiTVideo 的核心思路是借鉴 VQ-VAE-2 的分层结构和传统动画制作流程,采用分层 tokenizer 来编码视频数据。通过多层离散 token 框架,将视频内容分解为不同抽象层次的表示,高层捕捉语义信息,低层保留细节信息,从而实现高效压缩和高质量重建。
技术框架:HiTVideo 的整体框架基于 3D 因果 VAE。视频首先被编码器压缩成一系列离散的 token,这些 token 分布在多个层级上。高层 token 捕捉视频的全局语义信息,低层 token 则负责细节的时空信息。解码器则根据这些分层 token 重建视频。整个过程是因果的,保证了生成视频的时序连贯性。
关键创新:HiTVideo 的关键创新在于其分层 tokenizer 结构。与传统的单层 tokenizer 相比,分层结构能够更好地捕捉视频数据的多尺度特征,在高压缩率下保留更多的语义信息。此外,3D 因果 VAE 的设计保证了生成视频的时序一致性。
关键设计:HiTVideo 使用了多层离散 token 框架,每一层都对应一个独立的码本。高层码本的维度较低,用于捕捉全局语义信息;低层码本的维度较高,用于保留细节信息。损失函数包括重建损失和量化损失,用于优化编码器和解码器,并保证 token 的离散性。
🖼️ 关键图片


📊 实验亮点
HiTVideo 在长视频序列(8 秒,64 帧)上实现了显著的压缩性能提升,与基线 tokenizer 相比,每像素比特数 (bpp) 降低了约 70%,同时保持了具有竞争力的重建质量。这表明 HiTVideo 能够更有效地编码视频数据,为后续的文本生成视频任务提供更好的基础。
🎯 应用场景
HiTVideo 有潜力广泛应用于各种文本生成视频的场景,例如:AI 电影制作、游戏内容生成、虚拟现实内容创作等。通过高效压缩视频数据,HiTVideo 可以降低存储和传输成本,并简化大语言模型的建模过程,从而推动文本生成视频技术的发展。
📄 摘要(原文)
Text-to-video generation poses significant challenges due to the inherent complexity of video data, which spans both temporal and spatial dimensions. It introduces additional redundancy, abrupt variations, and a domain gap between language and vision tokens while generation. Addressing these challenges requires an effective video tokenizer that can efficiently encode video data while preserving essential semantic and spatiotemporal information, serving as a critical bridge between text and vision. Inspired by the observation in VQ-VAE-2 and workflows of traditional animation, we propose HiTVideo for text-to-video generation with hierarchical tokenizers. It utilizes a 3D causal VAE with a multi-layer discrete token framework, encoding video content into hierarchically structured codebooks. Higher layers capture semantic information with higher compression, while lower layers focus on fine-grained spatiotemporal details, striking a balance between compression efficiency and reconstruction quality. Our approach efficiently encodes longer video sequences (e.g., 8 seconds, 64 frames), reducing bits per pixel (bpp) by approximately 70\% compared to baseline tokenizers, while maintaining competitive reconstruction quality. We explore the trade-offs between compression and reconstruction, while emphasizing the advantages of high-compressed semantic tokens in text-to-video tasks. HiTVideo aims to address the potential limitations of existing video tokenizers in text-to-video generation tasks, striving for higher compression ratios and simplify LLMs modeling under language guidance, offering a scalable and promising framework for advancing text to video generation. Demo page: https://ziqinzhou66.github.io/project/HiTVideo.