FG-DFPN: Flow Guided Deformable Frame Prediction Network
作者: M. Akın Yılmaz, Ahmet Bilican, A. Murat Tekalp
分类: eess.IV, cs.CV
发布日期: 2025-03-14
备注: Submitted to 33th European Signal Processing Conference (EUSIPCO) 2025
💡 一句话要点
提出FG-DFPN,利用光流引导可变形卷积进行视频帧预测,显著提升预测精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频帧预测 光流估计 可变形卷积 时空建模 深度学习
📋 核心要点
- 现有视频帧预测方法难以有效建模复杂运动,尤其是在存在多种运动模式时,固定卷积核的局限性尤为明显。
- FG-DFPN利用光流估计引导可变形卷积,自适应地调整采样位置,从而更好地捕捉视频中的时空动态信息。
- 实验结果表明,FG-DFPN在多个MPEG测试序列上取得了state-of-the-art的性能,PSNR指标提升显著。
📝 摘要(中文)
视频帧预测是计算机视觉中的一项基础性挑战,对自动驾驶系统、视频压缩和媒体合成具有直接影响。本文提出了一种名为FG-DFPN的新型架构,它利用光流估计和可变形卷积之间的协同作用来建模复杂的时空动态。通过使用运动线索引导可变形采样,我们的方法解决了固定卷积核网络在处理各种运动模式时的局限性。多尺度设计使FG-DFPN能够以卓越的精度同时捕获全局场景变换和局部对象运动。实验表明,FG-DFPN在八个不同的MPEG测试序列上实现了最先进的性能,在保持具有竞争力的推理速度的同时,PSNR指标优于现有方法1dB。运动线索与自适应几何变换的结合使FG-DFPN成为需要高保真时间预测的下一代视频处理系统的一个有前途的解决方案。模型和复现结果的说明将在https://github.com/KUIS-AI-Tekalp-Research Group/frame-prediction上发布。
🔬 方法详解
问题定义:视频帧预测旨在根据已知的视频帧预测未来的帧,是视频处理中的关键任务。现有方法,特别是基于固定卷积核的方法,在处理包含复杂运动(例如,多个对象以不同速度和方向移动)的视频时,难以准确建模时空动态,导致预测模糊或失真。
核心思路:FG-DFPN的核心思路是利用光流估计提供的运动信息来引导可变形卷积。光流能够捕捉视频中像素级别的运动信息,而可变形卷积能够根据输入自适应地调整采样位置。通过将两者结合,FG-DFPN能够更准确地捕捉视频中的复杂运动模式,从而提高帧预测的准确性。
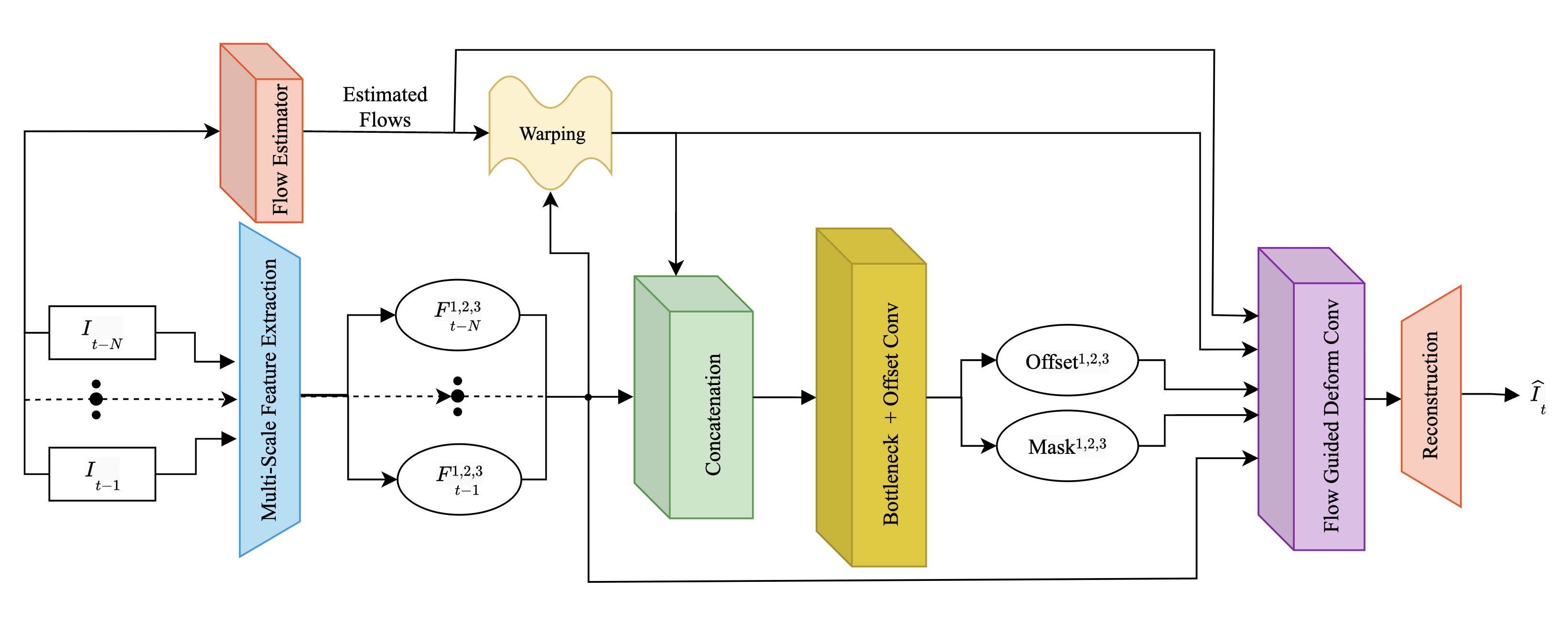
技术框架:FG-DFPN的整体架构是一个多尺度的编码器-解码器结构。编码器提取输入帧的多尺度特征,并估计光流。解码器利用编码器的特征和光流信息,通过可变形卷积生成预测帧。该框架包含以下主要模块:特征提取模块、光流估计模块、可变形卷积模块和帧重建模块。多尺度设计允许网络同时捕获全局场景变换和局部对象运动。
关键创新:FG-DFPN的关键创新在于将光流估计与可变形卷积相结合。传统的可变形卷积通常直接从特征图中学习偏移量,而FG-DFPN使用光流作为先验知识来引导偏移量的学习。这种方法能够更有效地利用运动信息,从而提高可变形卷积的采样效率和准确性。
关键设计:FG-DFPN的关键设计包括:1) 使用多尺度光流估计来捕捉不同尺度的运动信息;2) 使用光流引导的可变形卷积,其中光流用于初始化可变形卷积的偏移量;3) 使用残差连接来加速训练并提高模型的鲁棒性;4) 使用合适的损失函数(例如,L1损失或感知损失)来优化预测帧的质量。
🖼️ 关键图片


📊 实验亮点
FG-DFPN在八个不同的MPEG测试序列上实现了state-of-the-art的性能,PSNR指标优于现有方法1dB。这意味着在相同码率下,FG-DFPN能够提供更高质量的视频预测结果。此外,FG-DFPN在保持竞争力的推理速度的同时,显著提高了预测精度,使其在实际应用中更具优势。
🎯 应用场景
FG-DFPN在视频监控、自动驾驶、视频压缩和媒体合成等领域具有广泛的应用前景。例如,在视频监控中,它可以用于预测异常事件;在自动驾驶中,它可以用于预测车辆周围环境的变化;在视频压缩中,它可以用于减少冗余信息;在媒体合成中,它可以用于生成逼真的视频内容。该研究的实际价值在于提高视频处理系统的性能和效率,并为未来的视频处理技术发展提供新的思路。
📄 摘要(原文)
Video frame prediction remains a fundamental challenge in computer vision with direct implications for autonomous systems, video compression, and media synthesis. We present FG-DFPN, a novel architecture that harnesses the synergy between optical flow estimation and deformable convolutions to model complex spatio-temporal dynamics. By guiding deformable sampling with motion cues, our approach addresses the limitations of fixed-kernel networks when handling diverse motion patterns. The multi-scale design enables FG-DFPN to simultaneously capture global scene transformations and local object movements with remarkable precision. Our experiments demonstrate that FG-DFPN achieves state-of-the-art performance on eight diverse MPEG test sequences, outperforming existing methods by 1dB PSNR while maintaining competitive inference speeds. The integration of motion cues with adaptive geometric transformations makes FG-DFPN a promising solution for next-generation video processing systems that require high-fidelity temporal predictions. The model and instructions to reproduce our results will be released at: https://github.com/KUIS-AI-Tekalp-Research Group/frame-prediction