NF-SLAM: Effective, Normalizing Flow-supported Neural Field representations for object-level visual SLAM in automotive applications
作者: Li Cui, Yang Ding, Richard Hartley, Zirui Xie, Laurent Kneip, Zhenghua Yu
分类: cs.CV
发布日期: 2025-03-14
备注: 9 pages, 5 figures, IROS 2024
💡 一句话要点
提出NF-SLAM以解决汽车应用中的对象级视觉SLAM问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉SLAM 归一化流 神经场表示 汽车应用 3D重建 稀疏数据 深度学习
📋 核心要点
- 现有的SLAM方法在处理稀疏和噪声数据时表现不佳,难以实现高精度的3D形状重建。
- 本研究提出了一种基于归一化流网络的神经场表示,能够有效处理汽车应用中的对象级SLAM问题。
- 实验结果表明,该方法在仅使用稀疏3D点的情况下,仍能提供稳定且准确的性能,优于传统方法。
📝 摘要(中文)
我们提出了一种新颖的仅基于视觉的对象级SLAM框架,专为汽车应用设计,通过隐式有符号距离函数表示3D形状。我们的关键创新在于通过归一化流网络增强标准神经表示,从而实现对特定类别道路车辆的强表示能力,使用仅16维的潜在编码。此外,在稀疏和噪声数据的情况下,新架构表现出显著的性能提升。该模块嵌入到基于立体视觉的框架后端,实现联合增量形状优化。损失函数结合了稀疏3D点基础的SDF损失、稀疏渲染损失和基于语义掩码的轮廓一致性项。我们还利用语义信息来确定前端关键点提取的密度。最后,真实数据的实验结果显示出与使用直接深度读数的替代框架相当的准确性和可靠性。
🔬 方法详解
问题定义:本论文旨在解决现有视觉SLAM方法在稀疏和噪声数据条件下的性能不足,特别是在汽车应用中的对象级3D形状重建问题。现有方法往往依赖于密集的深度信息,导致在数据稀缺时效果不佳。
核心思路:论文的核心思路是通过引入归一化流网络来增强标准神经表示,从而提高对特定类别道路车辆的表示能力。通过使用紧凑的16维潜在编码,能够有效捕捉复杂的3D形状信息。
技术框架:整体架构包括前端和后端两个主要模块。前端负责关键点提取和语义信息的利用,后端则进行增量形状优化,结合稀疏3D点、稀疏渲染损失和轮廓一致性项进行训练。
关键创新:最重要的技术创新在于将归一化流网络与神经场表示结合,显著提升了在稀疏和噪声数据下的表现能力。这一设计使得模型在处理特定对象时更加高效。
关键设计:损失函数设计为稀疏3D点基础的SDF损失、稀疏渲染损失和基于语义掩码的轮廓一致性项的组合,确保模型在训练过程中能够有效学习到目标形状的特征。
🖼️ 关键图片

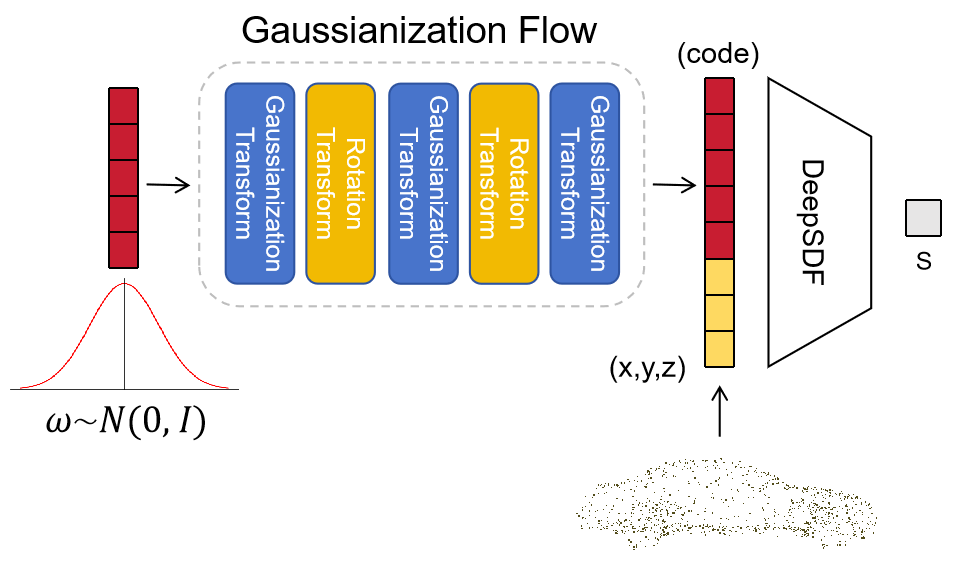

📊 实验亮点
实验结果显示,所提出的方法在仅使用稀疏3D点的情况下,能够实现与使用直接深度读数的替代框架相当的准确性和可靠性。具体而言,在合成数据上的对比实验中,性能提升幅度显著,证明了该方法在处理噪声和稀疏数据时的优势。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶汽车、智能交通系统以及机器人导航等。通过提升SLAM系统在复杂环境中的表现,能够为自动驾驶技术的安全性和可靠性提供支持,推动智能交通的进一步发展。
📄 摘要(原文)
We propose a novel, vision-only object-level SLAM framework for automotive applications representing 3D shapes by implicit signed distance functions. Our key innovation consists of augmenting the standard neural representation by a normalizing flow network. As a result, achieving strong representation power on the specific class of road vehicles is made possible by compact networks with only 16-dimensional latent codes. Furthermore, the newly proposed architecture exhibits a significant performance improvement in the presence of only sparse and noisy data, which is demonstrated through comparative experiments on synthetic data. The module is embedded into the back-end of a stereo-vision based framework for joint, incremental shape optimization. The loss function is given by a combination of a sparse 3D point-based SDF loss, a sparse rendering loss, and a semantic mask-based silhouette-consistency term. We furthermore leverage semantic information to determine keypoint extraction density in the front-end. Finally, experimental results on real-world data reveal accurate and reliable performance comparable to alternative frameworks that make use of direct depth readings. The proposed method performs well with only sparse 3D points obtained from bundle adjustment, and eventually continues to deliver stable results even under exclusive use of the mask-consistency term.