FastVID: Dynamic Density Pruning for Fast Video Large Language Models
作者: Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Pengzhang Liu, Sicheng Zhao, Guiguang Ding
分类: cs.CV
发布日期: 2025-03-14 (更新: 2025-12-14)
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
FastVID:面向快速视频大语言模型的动态密度剪枝
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 动态剪枝 密度剪枝 时空冗余 计算效率 视频理解 LLM加速
📋 核心要点
- 视频大语言模型推理成本高昂,主要由于视频tokens的冗余,现有剪枝方法未能充分利用视频的时空冗余性。
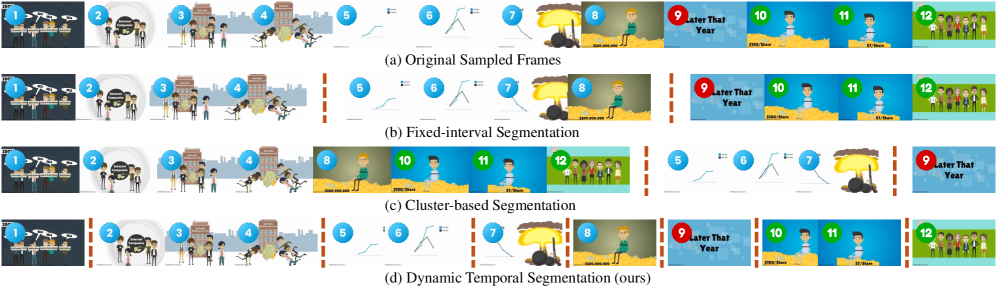
- FastVID通过动态划分视频片段来保留时间结构,并采用基于密度的token剪枝策略来维护关键的时空信息。
- 实验表明,FastVID在多个视频LLM上实现了显著的计算效率提升,同时保持了接近原始模型的准确率。
📝 摘要(中文)
视频大语言模型(Video LLMs)展现了强大的视频理解能力,但冗余的视频tokens导致巨大的推理成本,阻碍了它们的实际部署。现有的剪枝技术未能有效利用视频数据中存在的时空冗余。为了弥补这一差距,我们从时间上下文和视觉上下文两个角度系统地分析了视频冗余。基于这些见解,我们提出了用于快速视频LLM的动态密度剪枝方法,称为FastVID。具体来说,FastVID动态地将视频划分为时间顺序的片段以保留时间结构,并应用基于密度的token剪枝策略来维护必要的空间和时间信息。我们的方法显著降低了计算开销,同时保持了时间和视觉完整性。广泛的评估表明,FastVID在包括LLaVA-OneVision、LLaVA-Video、Qwen2-VL和Qwen2.5-VL在内的领先Video LLM上,在各种短视频和长视频基准测试中实现了最先进的性能。值得注意的是,在LLaVA-OneVision-7B上,FastVID有效地剪枝了$ extbf{90.3%}$的视频tokens,将FLOPs降低到$ extbf{8.3%}$,并将LLM预填充阶段加速了$ extbf{7.1} imes$,同时保持了$ extbf{98.0%}$的原始准确率。代码可在https://github.com/LunarShen/FastVID获取。
🔬 方法详解
问题定义:视频大语言模型在推理时面临高昂的计算成本,这主要是由于视频中存在大量的冗余tokens。现有的剪枝方法通常无法有效地利用视频数据的时空冗余性,导致剪枝后的模型性能下降或计算效率提升不明显。因此,如何高效地去除视频中的冗余信息,同时保持模型的理解能力,是本文要解决的核心问题。
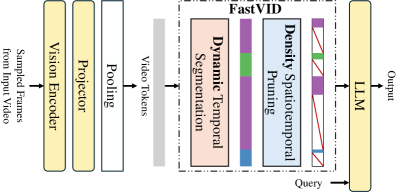
核心思路:FastVID的核心思路是动态地根据视频内容的时空特性进行token剪枝。它首先将视频分割成时间上有序的片段,以保留视频的时间结构。然后,针对每个片段,采用基于密度的token剪枝策略,去除冗余的tokens,同时保留关键的空间和时间信息。这种动态剪枝策略能够更好地适应视频内容的变化,从而在保证模型性能的同时,显著降低计算成本。
技术框架:FastVID的整体框架主要包括两个阶段:视频分割和动态密度剪枝。首先,视频被分割成多个时间上有序的片段。然后,对于每个片段,计算每个token的密度,并根据密度值进行剪枝。剪枝后的tokens被输入到视频大语言模型中进行后续处理。整个过程旨在减少输入LLM的token数量,从而加速推理过程。
关键创新:FastVID的关键创新在于其动态密度剪枝策略。与传统的静态剪枝方法不同,FastVID能够根据视频内容的变化动态地调整剪枝的比例和位置。这种动态性使得FastVID能够更好地适应不同类型的视频,从而在保证模型性能的同时,实现更高的计算效率。此外,基于密度的剪枝策略能够更有效地识别和去除冗余的tokens,从而进一步提高剪枝效果。
关键设计:FastVID的关键设计包括:1) 动态视频片段划分策略,用于保留视频的时间结构;2) 基于密度的token重要性评估方法,用于识别和去除冗余的tokens;3) 剪枝比例的动态调整机制,用于根据视频内容的变化自适应地调整剪枝比例。具体的密度计算方法和剪枝阈值的选择可能需要根据不同的视频数据集和模型进行调整。损失函数方面,FastVID的目标是在剪枝的同时尽可能地保持原始模型的性能,因此可以使用与原始模型相同的损失函数。
🖼️ 关键图片

📊 实验亮点
FastVID在LLaVA-OneVision-7B上表现出色,能够有效剪枝$ extbf{90.3%}$的视频tokens,将FLOPs降低到$ extbf{8.3%}$,并将LLM预填充阶段加速$ extbf{7.1} imes$,同时保持$ extbf{98.0%}$的原始准确率。这些结果表明,FastVID在降低计算成本的同时,能够有效地保持视频大语言模型的性能。
🎯 应用场景
FastVID具有广泛的应用前景,包括视频监控、自动驾驶、视频会议、在线教育等领域。通过降低视频大语言模型的计算成本,FastVID可以使得这些模型更容易部署在资源受限的设备上,例如移动设备和嵌入式系统。此外,FastVID还可以用于加速视频内容的分析和理解,从而提高相关应用的效率和性能。未来,FastVID有望成为视频智能领域的重要组成部分。
📄 摘要(原文)
Video Large Language Models have demonstrated strong video understanding capabilities, yet their practical deployment is hindered by substantial inference costs caused by redundant video tokens. Existing pruning techniques fail to effectively exploit the spatiotemporal redundancy present in video data. To bridge this gap, we perform a systematic analysis of video redundancy from two perspectives: temporal context and visual context. Leveraging these insights, we propose Dynamic Density Pruning for Fast Video LLMs termed FastVID. Specifically, FastVID dynamically partitions videos into temporally ordered segments to preserve temporal structure and applies a density-based token pruning strategy to maintain essential spatial and temporal information. Our method significantly reduces computational overhead while maintaining temporal and visual integrity. Extensive evaluations show that FastVID achieves state-of-the-art performance across various short- and long-video benchmarks on leading Video LLMs, including LLaVA-OneVision, LLaVA-Video, Qwen2-VL, and Qwen2.5-VL. Notably, on LLaVA-OneVision-7B, FastVID effectively prunes $\textbf{90.3%}$ of video tokens, reduces FLOPs to $\textbf{8.3%}$, and accelerates the LLM prefill stage by $\textbf{7.1}\times$, while maintaining $\textbf{98.0%}$ of the original accuracy. The code is available at https://github.com/LunarShen/FastVID.