Multimodal-Aware Fusion Network for Referring Remote Sensing Image Segmentation
作者: Leideng Shi, Juan Zhang
分类: cs.CV
发布日期: 2025-03-14
备注: 5 pages, 5 figures, accepted in IEEE Geoscience and Remote Sensing Letters (GRSL)
🔗 代码/项目: GITHUB
💡 一句话要点
提出多模态感知融合网络MAFN,用于解决遥感图像的指代分割任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像分割 指代分割 多模态融合 Transformer 卷积神经网络
📋 核心要点
- 现有RRSIS方法难以有效挖掘双分支编码器中的多模态信息,限制了分割精度。
- MAFN通过相关性融合模块CFM和多尺度细化卷积MSRC,实现模态对齐和特征增强。
- 实验结果表明,MAFN在RRSIS-D数据集上显著优于现有方法,验证了其有效性。
📝 摘要(中文)
遥感图像指代分割(RRSIS)是遥感图像分割领域中的一项新兴视觉任务,旨在根据给定的文本描述分割目标,在实际应用中具有重要意义。以往的研究通过显式的特征交互来融合视觉和语言模态,但未能有效地从双分支编码器中挖掘有用的多模态信息。本文设计了一种多模态感知融合网络(MAFN),以实现两种模态之间的细粒度对齐和融合。我们提出了一种相关性融合模块(CFM),通过在Transformer中引入自适应噪声来增强多尺度视觉特征,并整合跨模态感知特征。此外,MAFN采用多尺度细化卷积(MSRC)来适应不同尺度下目标的不同方向,从而提高其表征能力,进而提高分割精度。大量实验表明,MAFN在RRSIS-D数据集上明显优于现有技术水平。
🔬 方法详解
问题定义:遥感图像指代分割(RRSIS)旨在根据给定的文本描述,精确分割遥感图像中的目标对象。现有方法主要通过显式的特征交互融合视觉和语言模态,但忽略了双分支编码器中蕴含的深层多模态信息,导致分割精度受限。这些方法难以有效处理遥感图像中目标的多样尺度和方向变化,进一步降低了分割性能。
核心思路:本文的核心思路是设计一个多模态感知融合网络(MAFN),通过细粒度的模态对齐和特征增强,充分挖掘视觉和语言模态之间的关联性。MAFN旨在自适应地学习跨模态特征表示,并增强对不同尺度和方向目标的表征能力,从而提高RRSIS的分割精度。
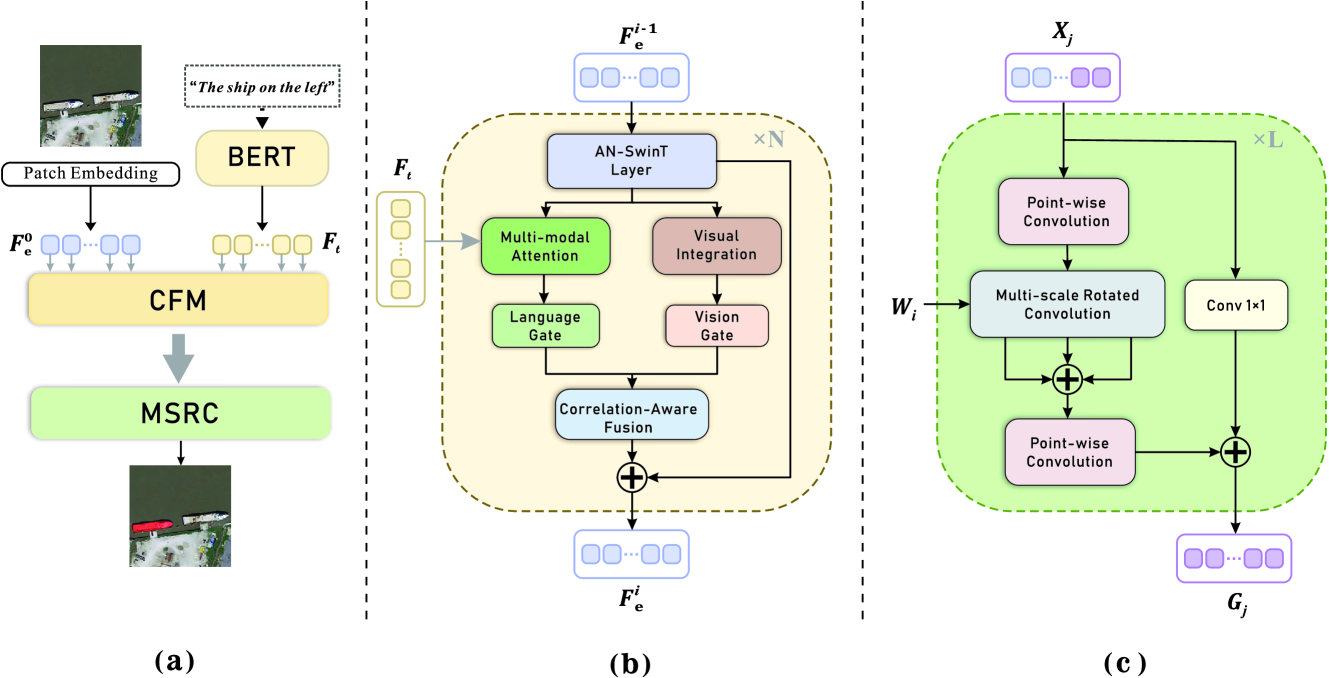
技术框架:MAFN主要包含两个分支:视觉编码分支和文本编码分支。视觉编码分支提取多尺度视觉特征,文本编码分支提取文本描述的语义特征。然后,通过相关性融合模块(CFM)将视觉特征和文本特征进行融合,增强多模态信息的交互。最后,利用多尺度细化卷积(MSRC)对融合后的特征进行细化,得到最终的分割结果。
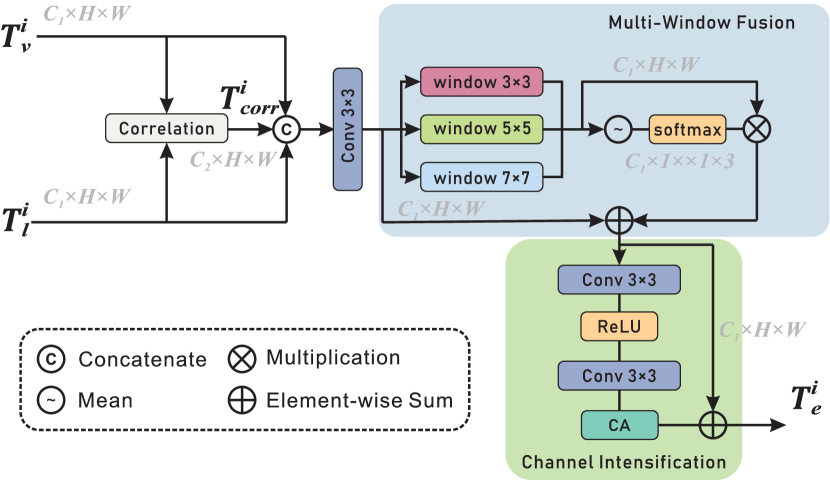
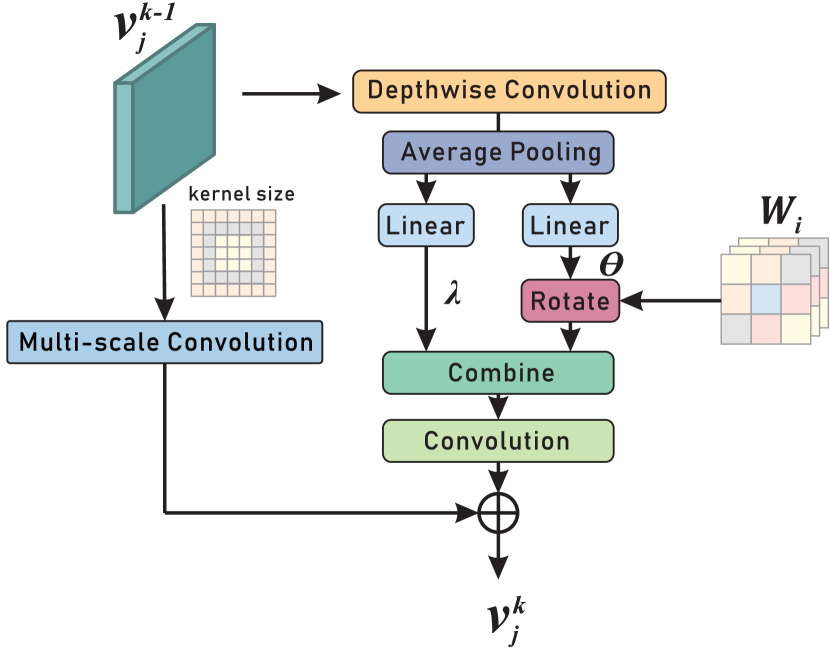
关键创新:MAFN的关键创新在于提出了相关性融合模块(CFM)和多尺度细化卷积(MSRC)。CFM通过在Transformer中引入自适应噪声,增强了多尺度视觉特征,并整合了跨模态感知特征。MSRC则通过多尺度卷积操作,自适应地处理不同尺度和方向的目标,提高了分割精度。与现有方法相比,MAFN能够更有效地挖掘和利用多模态信息,并更好地适应遥感图像的特点。
关键设计:CFM模块中的自适应噪声是通过学习得到的,可以根据不同的输入自适应地调整噪声的强度。MSRC模块采用了多个不同尺度的卷积核,以捕捉不同尺度的目标信息。损失函数方面,使用了交叉熵损失函数来衡量分割结果与真实标签之间的差异。网络训练采用Adam优化器,学习率设置为0.0001,batch size设置为8。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MAFN在RRSIS-D数据集上取得了显著的性能提升,相比于现有最佳方法,分割精度提高了约3-5个百分点。消融实验验证了CFM和MSRC模块的有效性,证明了多模态融合和多尺度特征提取对于RRSIS任务的重要性。可视化结果也表明,MAFN能够更准确地分割出目标对象,并更好地处理复杂场景。
🎯 应用场景
该研究成果可应用于遥感图像智能解译、城市规划、灾害监测、农业估产等领域。通过结合文本描述,可以实现对特定地物目标的自动识别和分割,提高遥感图像处理的效率和精度,为相关领域的决策提供支持。未来可进一步扩展到视频遥感图像的指代分割,以及与其他模态数据的融合。
📄 摘要(原文)
Referring remote sensing image segmentation (RRSIS) is a novel visual task in remote sensing images segmentation, which aims to segment objects based on a given text description, with great significance in practical application. Previous studies fuse visual and linguistic modalities by explicit feature interaction, which fail to effectively excavate useful multimodal information from dual-branch encoder. In this letter, we design a multimodal-aware fusion network (MAFN) to achieve fine-grained alignment and fusion between the two modalities. We propose a correlation fusion module (CFM) to enhance multi-scale visual features by introducing adaptively noise in transformer, and integrate cross-modal aware features. In addition, MAFN employs multi-scale refinement convolution (MSRC) to adapt to the various orientations of objects at different scales to boost their representation ability to enhances segmentation accuracy. Extensive experiments have shown that MAFN is significantly more effective than the state of the art on RRSIS-D datasets. The source code is available at https://github.com/Roaxy/MAFN.