Pruning the Paradox: How CLIP's Most Informative Heads Enhance Performance While Amplifying Bias
作者: Avinash Madasu, Vasudev Lal, Phillip Howard
分类: cs.CV, cs.AI
发布日期: 2025-03-14 (更新: 2025-09-19)
💡 一句话要点
提出概念一致性分数(CCS),揭示CLIP模型性能与社会偏见之间的内在联系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CLIP模型 可解释性 社会偏见 注意力机制 概念一致性 软剪枝 视觉-语言
📋 核心要点
- CLIP模型在视觉-语言任务中表现出色,但其内部机制和潜在的社会偏见尚不明确。
- 提出概念一致性分数(CCS),用于衡量CLIP模型中注意力头与特定概念的一致性程度。
- 实验表明,高CCS的注意力头对模型性能至关重要,但也放大了社会偏见。
📝 摘要(中文)
CLIP是最流行的基础模型之一,被广泛应用于各种视觉-语言任务,但对其内部机制的了解仍然有限。随着CLIP在现实世界应用中的日益普及,理解其局限性和嵌入的社会偏见,以减轻潜在的有害下游影响变得至关重要。本文研究了类CLIP模型中注意力头的文本描述的概念一致性。具体来说,我们提出了一种新的可解释性指标——概念一致性分数(CCS),用于衡量CLIP模型中各个注意力头与特定概念的一致性程度。我们的软剪枝实验表明,高CCS的注意力头对于保持模型性能至关重要,因为剪枝它们会导致比剪枝随机或低CCS的注意力头更大的性能下降。值得注意的是,我们发现高CCS的注意力头捕获了基本概念,并在域外检测、概念特定推理和视频-语言理解中发挥着关键作用。此外,我们证明了高CCS的注意力头学习了虚假的相关性,从而放大了社会偏见。这些结果表明,CCS是一个强大的可解释性指标,揭示了CLIP模型中性能和社会偏见之间的悖论。
🔬 方法详解
问题定义:CLIP模型作为强大的视觉-语言基础模型,在实际应用中面临着可解释性和社会偏见的问题。现有方法难以有效识别模型内部哪些机制驱动了其强大的性能,以及哪些机制导致了其潜在的偏见。因此,如何理解CLIP模型内部的工作原理,并减轻其潜在的社会偏见,是一个重要的研究问题。
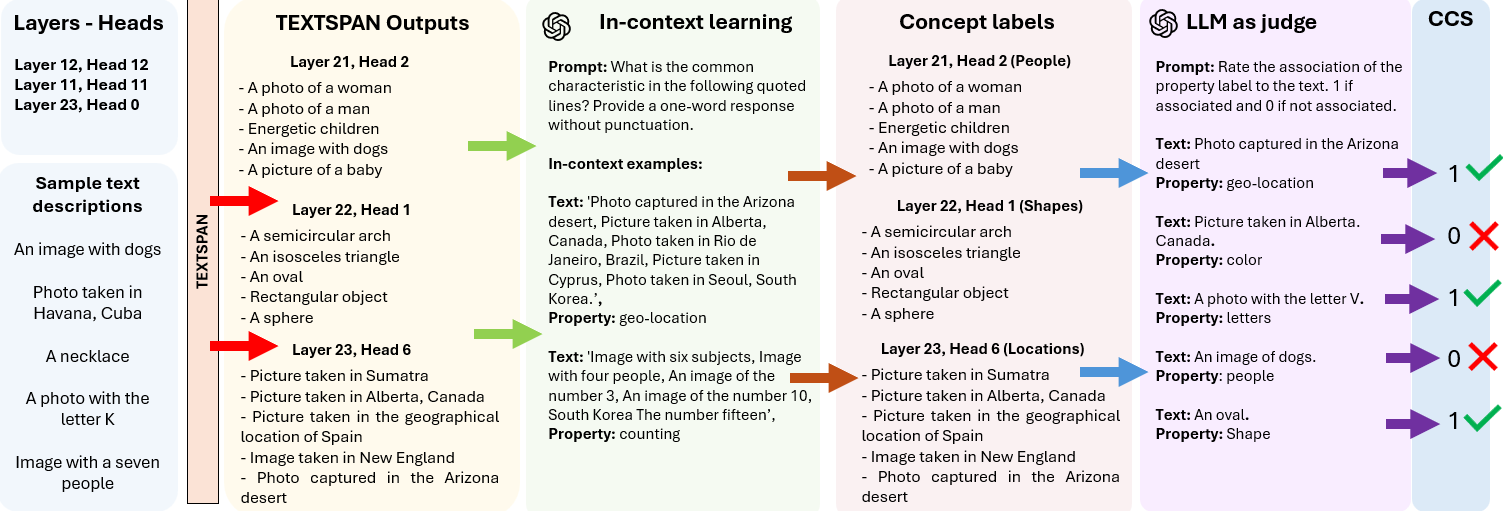
核心思路:本文的核心思路是通过量化CLIP模型中各个注意力头与特定概念的一致性程度,来理解模型内部的知识表示和偏见来源。具体来说,提出了概念一致性分数(CCS)这一指标,用于衡量注意力头与特定概念的对齐程度。通过分析高CCS注意力头的行为,可以揭示模型如何利用这些概念来完成任务,以及这些概念如何导致偏见。
技术框架:本文的技术框架主要包括以下几个步骤:1) 定义概念集合;2) 为每个注意力头生成文本描述;3) 计算每个注意力头与每个概念之间的CCS;4) 进行软剪枝实验,评估不同CCS注意力头对模型性能的影响;5) 分析高CCS注意力头在不同任务中的作用,以及它们与社会偏见之间的关系。
关键创新:本文最重要的技术创新点是提出了概念一致性分数(CCS)这一可解释性指标。CCS能够有效地量化CLIP模型中各个注意力头与特定概念的一致性程度,从而为理解模型内部的知识表示和偏见来源提供了新的视角。与现有方法相比,CCS更加直接和易于理解,并且能够用于分析各种不同的概念。
关键设计:CCS的计算方法是基于注意力头生成的文本描述和概念的文本描述之间的相似度。具体来说,首先使用预训练的语言模型(例如BERT)为每个注意力头生成文本描述。然后,计算注意力头文本描述和概念文本描述之间的余弦相似度,作为该注意力头与该概念的CCS。在软剪枝实验中,使用不同的剪枝策略(例如,随机剪枝、低CCS剪枝、高CCS剪枝)来移除不同比例的注意力头,并评估模型在不同任务上的性能。
🖼️ 关键图片

📊 实验亮点
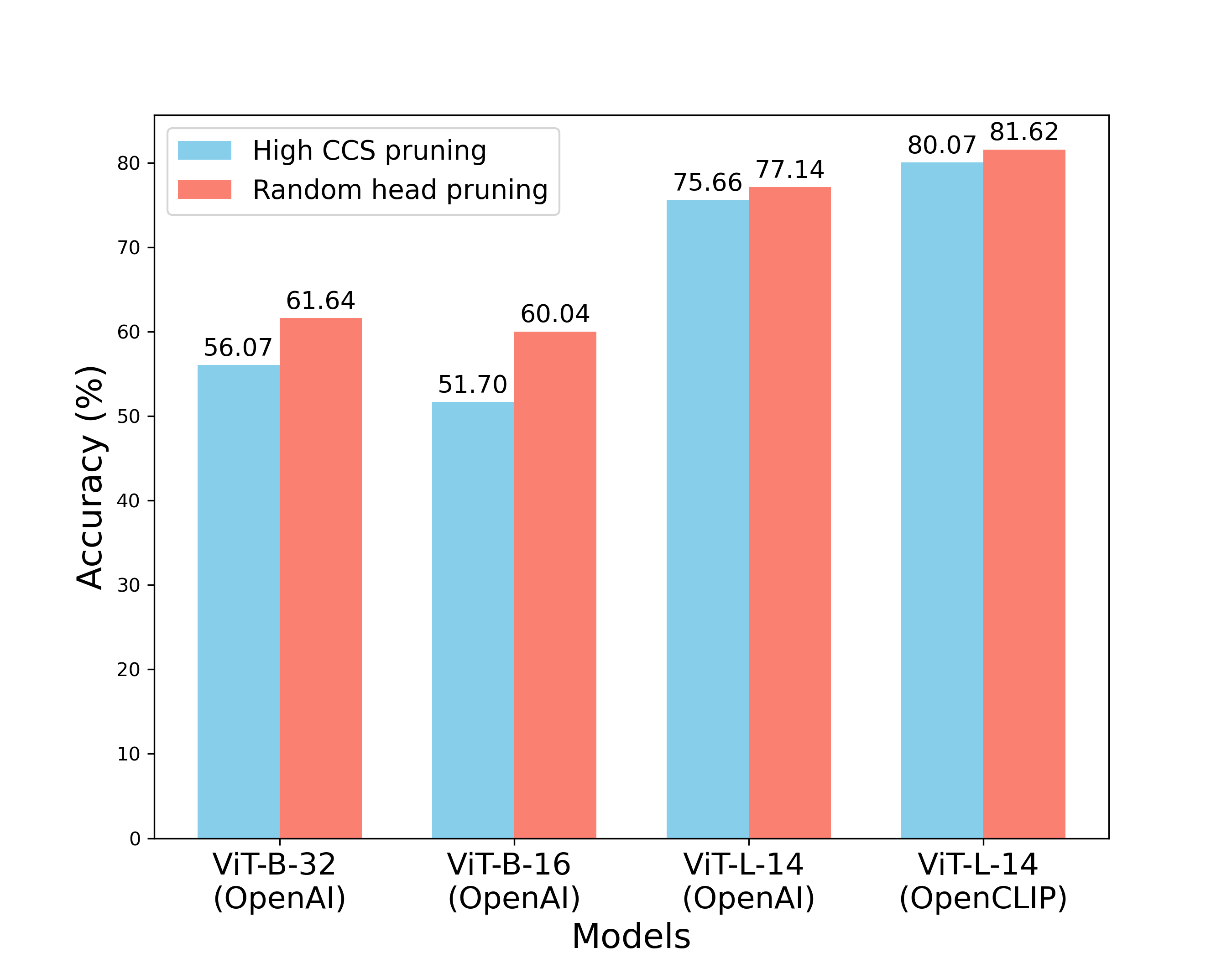
实验结果表明,高CCS的注意力头对于保持CLIP模型的性能至关重要。剪枝高CCS的注意力头会导致比剪枝随机或低CCS的注意力头更大的性能下降。此外,研究发现高CCS的注意力头捕获了基本概念,并在域外检测、概念特定推理和视频-语言理解中发挥着关键作用。然而,这些高CCS的注意力头也学习了虚假的相关性,从而放大了社会偏见。
🎯 应用场景
该研究成果可应用于提升CLIP模型的可解释性和公平性。通过识别和干预高CCS但带有偏见的注意力头,可以减轻CLIP模型在下游任务中的社会偏见,例如图像分类、目标检测和文本生成等。此外,CCS可以作为一种通用的可解释性工具,用于分析其他视觉-语言模型。
📄 摘要(原文)
CLIP is one of the most popular foundation models and is heavily used for many vision-language tasks, yet little is known about its inner workings. As CLIP is increasingly deployed in real-world applications, it is becoming even more critical to understand its limitations and embedded social biases to mitigate potentially harmful downstream consequences. However, the question of what internal mechanisms drive both the impressive capabilities as well as problematic shortcomings of CLIP has largely remained unanswered. To bridge this gap, we study the conceptual consistency of text descriptions for attention heads in CLIP-like models. Specifically, we propose Concept Consistency Score (CCS), a novel interpretability metric that measures how consistently individual attention heads in CLIP models align with specific concepts. Our soft-pruning experiments reveal that high CCS heads are critical for preserving model performance, as pruning them leads to a significantly larger performance drop than pruning random or low CCS heads. Notably, we find that high CCS heads capture essential concepts and play a key role in out-of-domain detection, concept-specific reasoning, and video-language understanding. Moreover, we prove that high CCS heads learn spurious correlations which amplify social biases. These results position CCS as a powerful interpretability metric exposing the paradox of performance and social biases in CLIP models.