Augmenting Image Annotation: A Human-LMM Collaborative Framework for Efficient Object Selection and Label Generation
作者: He Zhang, Xinyi Fu, John M. Carroll
分类: cs.CV, cs.AI, cs.HC
发布日期: 2025-03-14
备注: This paper will appear at ICLR 2025 Workshop on Bidirectional Human-AI Alignment
💡 一句话要点
提出人-LMM协作框架,提升图像标注效率,减轻标注疲劳
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像标注 人机协作 多模态模型 GPT 对象识别
📋 核心要点
- 传统图像标注依赖人工,效率低且易疲劳,难以满足大规模数据需求。
- 提出人-LMM协作框架,人工选择对象,LMM自动生成标签,降低标注负担。
- 实验表明,该框架在对象识别、场景描述和细粒度分类等任务上具有良好泛化能力。
📝 摘要(中文)
本文提出了一种新颖的框架,利用大型多模态模型(LMM),特别是GPT的视觉理解能力,来辅助图像标注工作流程。传统图像标注任务严重依赖人工进行对象选择和标签分配,导致过程耗时且效率降低,尤其是在标注员长时间工作后容易疲劳。在该方法中,人工标注员专注于通过边界框选择对象,而LMM自主生成相关标签。这种人-AI协作框架通过减少人工标注员的认知和时间负担来提高标注效率。通过分析系统在各种类型的标注任务中的性能,证明了其能够推广到对象识别、场景描述和细粒度分类等任务。该框架展示了这种方法在重新定义标注工作流程方面的潜力,为计算机视觉中的大规模数据标注提供了一种可扩展且高效的解决方案。最后,讨论了将LMM集成到标注流程中如何促进双向人-AI对齐,以及在信息过载的情况下,通过将部分工作转移到AI来缓解“无休止的标注”负担所面临的挑战。
🔬 方法详解
问题定义:传统图像标注流程高度依赖人工,标注员需要手动选择图像中的对象并为其分配标签。这种方式耗时耗力,尤其是在处理大规模数据集时,标注员容易疲劳,导致标注质量下降,效率降低。现有方法缺乏有效的自动化手段来减轻人工标注的负担。
核心思路:论文的核心思路是利用大型多模态模型(LMM)的视觉理解能力,将标注任务分解为对象选择和标签生成两个子任务,并让人工标注员和LMM协同完成。人工负责精确的对象选择,LMM负责自动生成标签,从而减轻人工标注的认知负担,提高标注效率。
技术框架:该框架包含两个主要模块:人工对象选择模块和LMM标签生成模块。首先,人工标注员使用边界框在图像中选择目标对象。然后,将包含对象边界框的图像输入到LMM(例如GPT),LMM根据图像内容和对象位置自动生成相应的标签。最后,人工审核LMM生成的标签,并进行必要的修正。
关键创新:该方法最重要的创新点在于引入了人-AI协作模式,将人工的精确性和LMM的自动化能力相结合。与完全依赖人工或完全依赖自动标注的方法相比,该方法能够在保证标注质量的同时,显著提高标注效率。此外,该方法利用了预训练LMM的强大视觉理解能力,无需针对特定任务进行额外训练。
关键设计:论文中没有明确指出关键的参数设置、损失函数、网络结构等技术细节,因为该框架主要依赖于现有的LMM(如GPT)。关键设计在于如何有效地将人工标注员和LMM结合起来,形成一个高效的协作流程。例如,可以设计一个用户友好的界面,方便人工标注员选择对象和审核LMM生成的标签。
🖼️ 关键图片

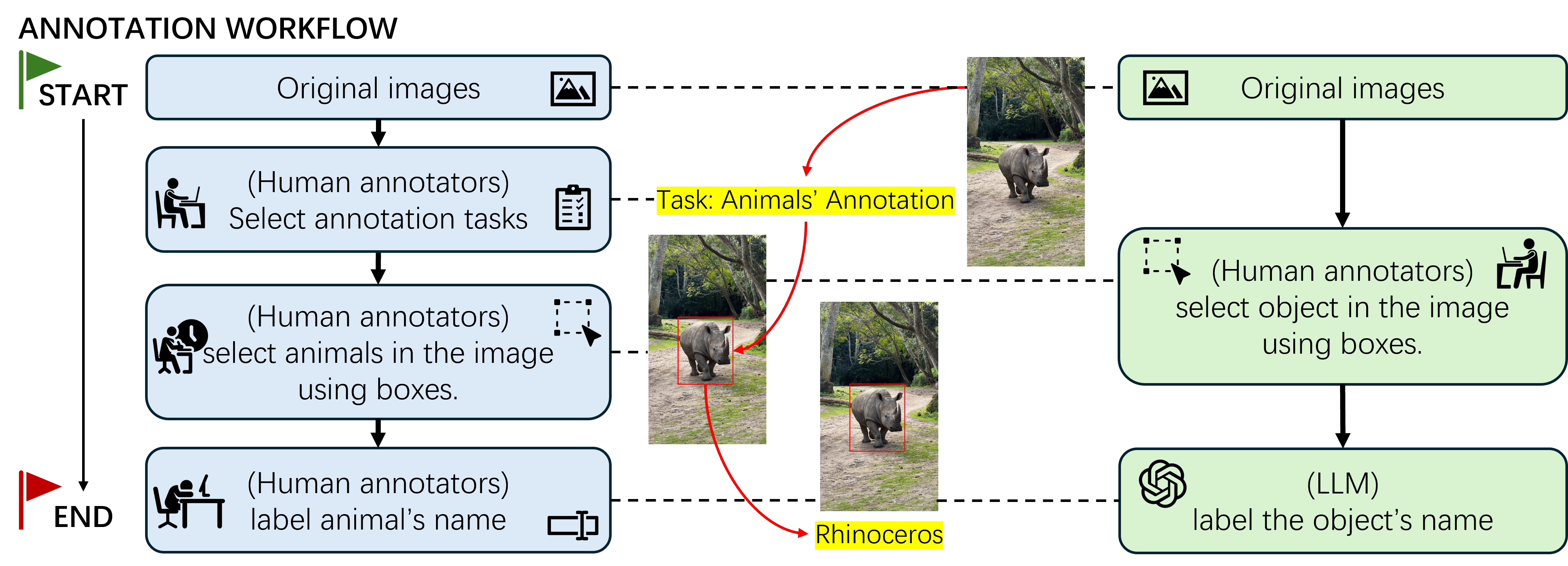

📊 实验亮点
该论文的主要亮点在于提出了一种人-LMM协作的图像标注框架,该框架能够有效提高标注效率,减轻人工标注的负担。虽然论文中没有给出具体的性能数据和对比基线,但通过分析系统在对象识别、场景描述和细粒度分类等任务中的表现,证明了该框架具有良好的泛化能力和应用潜力。
🎯 应用场景
该研究成果可广泛应用于计算机视觉领域的各种数据标注任务,例如自动驾驶、智能安防、医疗影像分析等。通过提高标注效率,可以加速相关领域的数据集构建,推动人工智能技术的发展。此外,该方法还可以应用于教育、内容审核等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Traditional image annotation tasks rely heavily on human effort for object selection and label assignment, making the process time-consuming and prone to decreased efficiency as annotators experience fatigue after extensive work. This paper introduces a novel framework that leverages the visual understanding capabilities of large multimodal models (LMMs), particularly GPT, to assist annotation workflows. In our proposed approach, human annotators focus on selecting objects via bounding boxes, while the LMM autonomously generates relevant labels. This human-AI collaborative framework enhances annotation efficiency by reducing the cognitive and time burden on human annotators. By analyzing the system's performance across various types of annotation tasks, we demonstrate its ability to generalize to tasks such as object recognition, scene description, and fine-grained categorization. Our proposed framework highlights the potential of this approach to redefine annotation workflows, offering a scalable and efficient solution for large-scale data labeling in computer vision. Finally, we discuss how integrating LMMs into the annotation pipeline can advance bidirectional human-AI alignment, as well as the challenges of alleviating the "endless annotation" burden in the face of information overload by shifting some of the work to AI.