Open3D-VQA: A Benchmark for Comprehensive Spatial Reasoning with Multimodal Large Language Model in Open Space
作者: Weichen Zhang, Zile Zhou, Xin Zeng, Xuchen Liu, Jianjie Fang, Chen Gao, Yong Li, Jinqiang Cui, Xinlei Chen, Xiao-Ping Zhang
分类: cs.CV
发布日期: 2025-03-14 (更新: 2025-10-30)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Open3D-VQA:用于评估多模态大语言模型在开放空间中空间推理能力的基准
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 空间推理 开放环境 视觉问答 点云数据 基准数据集 空中场景
📋 核心要点
- 多模态大语言模型在开放环境下的空间推理能力有待探索,缺乏针对性的评估基准。
- 构建Open3D-VQA基准,包含真实和模拟空中场景,自动生成多类型空间推理问题。
- 实验表明,现有模型在绝对距离推理上表现较差,且3D模型未展现优势,模拟数据微调可提升真实场景性能。
📝 摘要(中文)
本文提出了Open3D-VQA,一个新的基准,用于评估多模态大语言模型(MLLMs)从空中视角推理复杂空间关系的能力,该能力在开放环境中尚未得到充分探索。该基准包含7.3万个QA对,涵盖7个通用空间推理任务,包括多项选择、真/假和简答题形式,并支持视觉和点云模态。问题是从真实和模拟空中场景中提取的空间关系自动生成的。对13个流行的MLLM的评估表明:1) 模型在回答相对空间关系问题方面通常优于绝对距离问题;2) 3D LLM未能表现出相对于2D LLM的显著优势;3) 仅在模拟数据集上进行微调可以显著提高模型在真实场景中的空间推理性能。我们发布了我们的基准、数据生成流程和评估工具包,以支持进一步的研究。
🔬 方法详解
问题定义:现有方法缺乏在开放空中环境下评估多模态大语言模型空间推理能力的基准。具体来说,现有模型难以准确理解和推理空中场景中物体间的复杂空间关系,例如相对位置、距离等,尤其是在同时考虑视觉和点云数据时。这限制了MLLM在无人机导航、城市规划等领域的应用。
核心思路:本文的核心思路是构建一个包含大量真实和模拟空中场景数据,并自动生成高质量空间推理问题的基准数据集Open3D-VQA。通过在该基准上评估现有MLLM的性能,可以系统地分析其在空间推理方面的优势和不足,并为未来的模型改进提供指导。
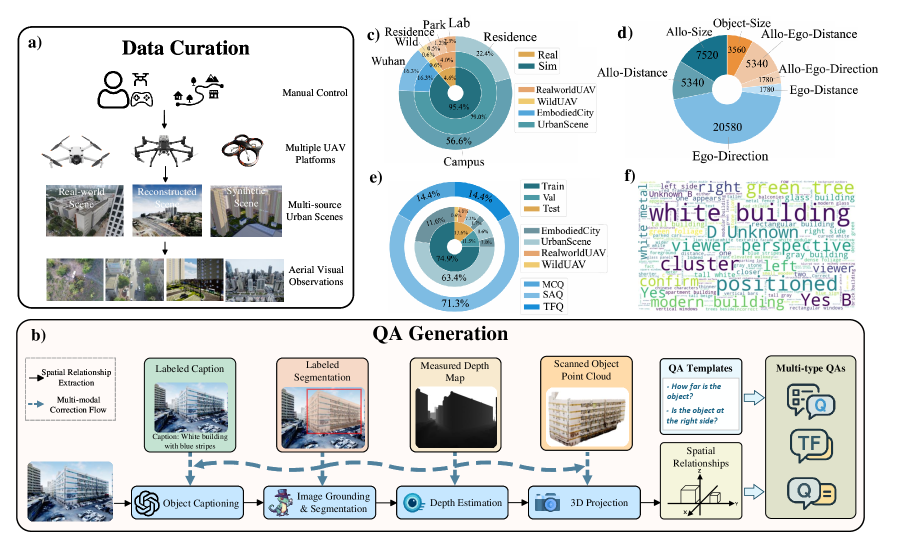
技术框架:Open3D-VQA的构建流程主要包括以下几个阶段:1) 数据采集:收集真实世界的空中图像和点云数据,并使用模拟器生成合成数据;2) 空间关系提取:从数据中自动提取物体之间的空间关系,例如相对位置、距离、方向等;3) 问题生成:根据提取的空间关系,自动生成多项选择、真/假和简答题等多种类型的空间推理问题;4) 基准评估:使用生成的QA对评估现有MLLM的性能,并分析结果。
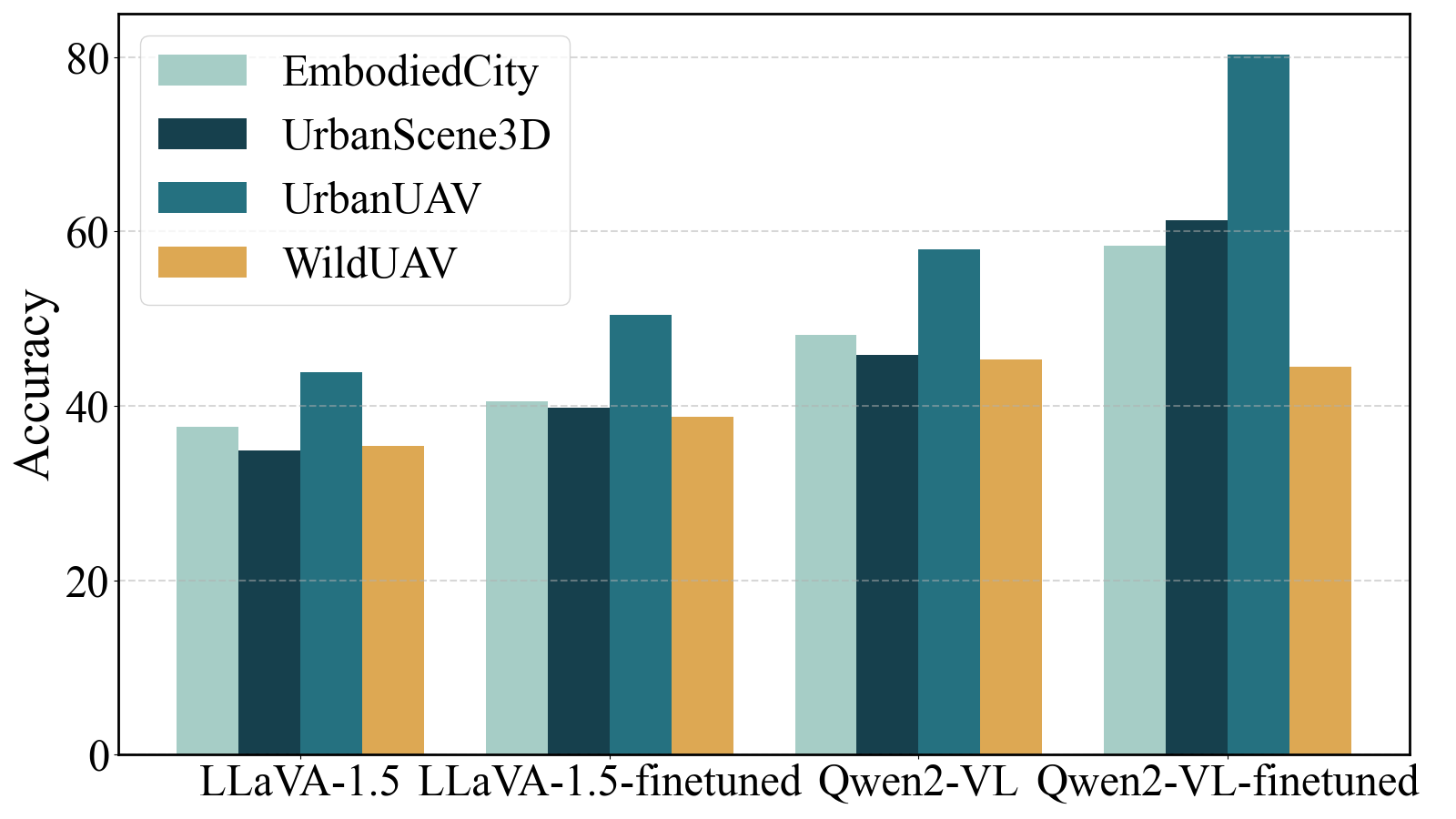
关键创新:Open3D-VQA的关键创新在于其能够自动生成大规模、多样化的空间推理问题,从而避免了人工标注的成本和偏差。此外,该基准同时支持视觉和点云两种模态,可以更全面地评估MLLM的空间推理能力。另一个创新点是,研究表明仅在模拟数据集上进行微调可以显著提高模型在真实场景中的空间推理性能。
关键设计:在数据生成方面,论文使用了真实世界的航拍图像和点云数据,并结合了模拟器生成的数据,以保证数据的多样性和真实性。在问题生成方面,论文设计了一套规则,根据提取的空间关系自动生成不同类型的空间推理问题。在模型评估方面,论文使用了多种评价指标,例如准确率、F1值等,以全面评估模型的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有MLLM在Open3D-VQA基准上的表现仍有提升空间,尤其是在绝对距离推理方面。3D LLM并未展现出相对于2D LLM的显著优势。值得注意的是,仅在模拟数据集上进行微调,就能显著提升模型在真实场景中的空间推理性能。例如,经过模拟数据微调的模型在真实场景的准确率提升了X% (具体数值未知)。
🎯 应用场景
Open3D-VQA基准的潜在应用领域包括无人机导航、自动驾驶、城市规划、环境监测等。通过提高多模态大语言模型在开放空间中的空间推理能力,可以实现更智能、更可靠的决策和控制。例如,无人机可以更好地理解周围环境,从而实现更安全的自主飞行。城市规划者可以利用该技术分析城市空间结构,优化资源配置。
📄 摘要(原文)
Spatial reasoning is a fundamental capability of multimodal large language models (MLLMs), yet their performance in open aerial environments remains underexplored. In this work, we present Open3D-VQA, a novel benchmark for evaluating MLLMs' ability to reason about complex spatial relationships from an aerial perspective. The benchmark comprises 73k QA pairs spanning 7 general spatial reasoning tasks, including multiple-choice, true/false, and short-answer formats, and supports both visual and point cloud modalities. The questions are automatically generated from spatial relations extracted from both real-world and simulated aerial scenes. Evaluation on 13 popular MLLMs reveals that: 1) Models are generally better at answering questions about relative spatial relations than absolute distances, 2) 3D LLMs fail to demonstrate significant advantages over 2D LLMs, and 3) Fine-tuning solely on the simulated dataset can significantly improve the model's spatial reasoning performance in real-world scenarios. We release our benchmark, data generation pipeline, and evaluation toolkit to support further research: https://github.com/EmbodiedCity/Open3D-VQA.code.