OmniDiff: A Comprehensive Benchmark for Fine-grained Image Difference Captioning
作者: Yuan Liu, Saihui Hou, Saijie Hou, Jiabao Du, Shibei Meng, Yongzhen Huang
分类: cs.CV
发布日期: 2025-03-14
💡 一句话要点
OmniDiff:用于细粒度图像差异描述的综合基准,并提出M$^3$Diff模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像差异描述 多模态学习 大型语言模型 多尺度感知 数据集构建
📋 核心要点
- 现有图像差异描述数据集缺乏广度和深度,难以应对复杂场景和细粒度差异描述任务。
- 提出OmniDiff数据集,包含324个多样化场景和细粒度人工标注,覆盖12种变化类型。
- 提出M$^3$Diff模型,通过多尺度差异感知模块增强多模态大语言模型,提升差异识别能力。
📝 摘要(中文)
图像差异描述(IDC)旨在生成自然语言描述图像对之间细微差异,这需要精确的视觉变化定位和连贯的语义表达。现有数据集在广度和深度上存在不足,限制了其在复杂和动态环境中的应用:(1)从广度上看,当前数据集仅限于特定场景中对象的有限变化;(2)从深度上看,先前的基准通常提供过于简单的描述。为了解决这些挑战,我们引入了OmniDiff,一个包含324个多样化场景的综合数据集,涵盖真实世界的复杂环境和3D合成设置,具有细粒度的人工标注,平均长度为60个单词,涵盖12种不同的变化类型。在此基础上,我们提出了M$^3$Diff,一个由即插即用的多尺度差异感知(MDP)模块增强的多模态大型语言模型。该模块提高了模型准确识别和描述图像间差异的能力,同时保持了基础模型的泛化能力。通过添加OmniDiff数据集,M$^3$Diff在多个基准测试中实现了最先进的性能,包括Spot-the-Diff、IEdit、CLEVR-Change、CLEVR-DC和OmniDiff,与现有方法相比,在跨场景差异识别准确性方面取得了显著提高。数据集、代码和模型将公开提供,以支持进一步的研究。
🔬 方法详解
问题定义:图像差异描述(IDC)任务旨在生成自然语言描述图像对之间细微差异。现有数据集的局限性在于场景单一、变化类型有限、描述过于简单,难以满足实际应用需求。现有方法难以在复杂场景下精确定位和描述图像间的细微差异。
核心思路:论文的核心思路是构建一个更全面、更细粒度的图像差异描述数据集OmniDiff,并在此基础上设计一个能够有效利用多尺度差异信息的模型M$^3$Diff。通过高质量的数据和模型设计,提升模型在复杂场景下的差异识别和描述能力。
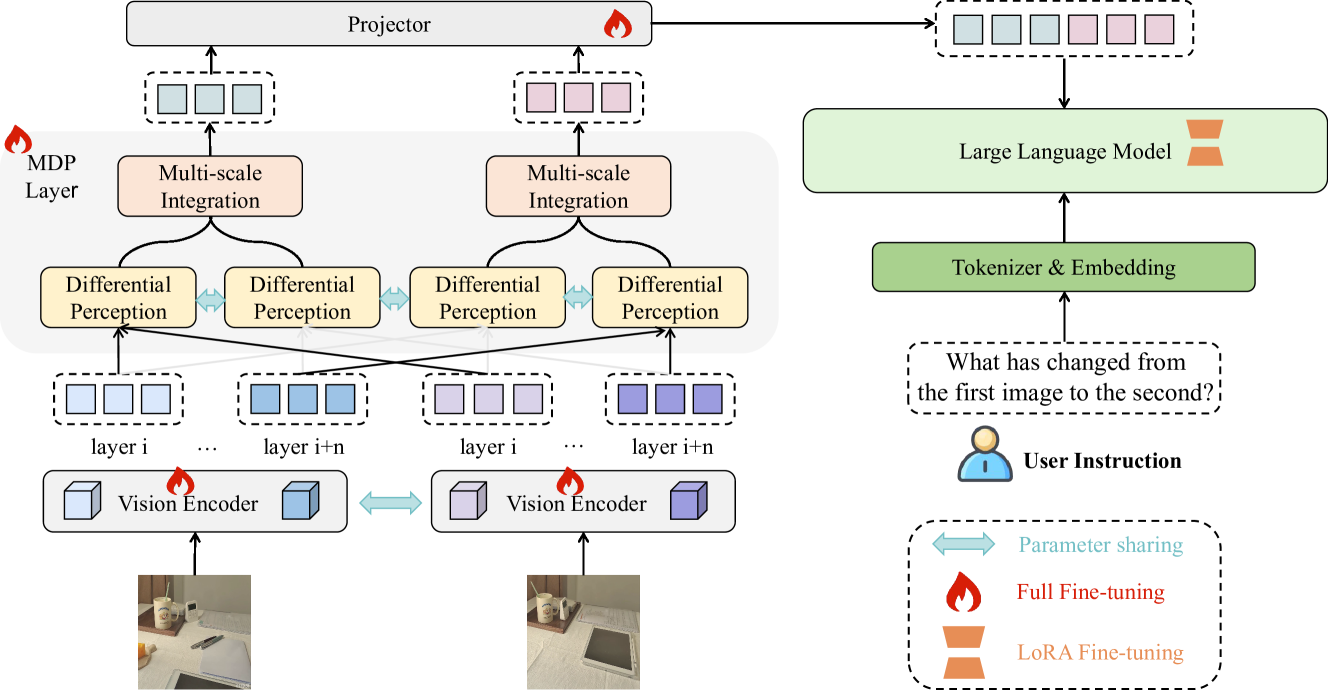
技术框架:M$^3$Diff模型基于多模态大型语言模型,并引入了一个即插即用的多尺度差异感知(MDP)模块。MDP模块旨在提取图像对在不同尺度上的差异特征,并将这些特征融入到多模态大语言模型中,从而增强模型对图像差异的感知能力。整体流程包括:图像对输入、MDP模块提取多尺度差异特征、特征融合到多模态大语言模型、生成差异描述文本。
关键创新:关键创新点在于OmniDiff数据集的构建和MDP模块的设计。OmniDiff数据集提供了更丰富、更细粒度的图像差异标注,为模型训练提供了高质量的数据支撑。MDP模块通过多尺度感知,能够更全面地捕捉图像间的差异信息,提升模型的差异识别能力。
关键设计:MDP模块的具体设计细节未知,但可以推测其可能包含不同尺度的卷积层或池化层,用于提取不同感受野的差异特征。损失函数可能包括交叉熵损失或对比损失,用于优化模型对差异的识别能力。数据集的标注方式采用了细粒度的人工标注,平均长度为60个单词,保证了描述的准确性和完整性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,M$^3$Diff模型在OmniDiff、Spot-the-Diff、IEdit、CLEVR-Change和CLEVR-DC等多个基准测试中取得了state-of-the-art的性能。尤其是在OmniDiff数据集上,M$^3$Diff模型相比现有方法在跨场景差异识别准确性方面取得了显著提高,验证了所提出数据集和模型的有效性。
🎯 应用场景
该研究成果可应用于智能监控、图像编辑、自动驾驶、医疗影像分析等领域。例如,在智能监控中,可以用于检测异常事件和行为;在图像编辑中,可以辅助用户进行精细化的图像修改;在自动驾驶中,可以帮助车辆识别环境变化;在医疗影像分析中,可以辅助医生诊断疾病。
📄 摘要(原文)
Image Difference Captioning (IDC) aims to generate natural language descriptions of subtle differences between image pairs, requiring both precise visual change localization and coherent semantic expression. Despite recent advancements, existing datasets often lack breadth and depth, limiting their applicability in complex and dynamic environments: (1) from a breadth perspective, current datasets are constrained to limited variations of objects in specific scenes, and (2) from a depth perspective, prior benchmarks often provide overly simplistic descriptions. To address these challenges, we introduce OmniDiff, a comprehensive dataset comprising 324 diverse scenarios-spanning real-world complex environments and 3D synthetic settings-with fine-grained human annotations averaging 60 words in length and covering 12 distinct change types. Building on this foundation, we propose M$^3$Diff, a MultiModal large language model enhanced by a plug-and-play Multi-scale Differential Perception (MDP) module. This module improves the model's ability to accurately identify and describe inter-image differences while maintaining the foundational model's generalization capabilities. With the addition of the OmniDiff dataset, M$^3$Diff achieves state-of-the-art performance across multiple benchmarks, including Spot-the-Diff, IEdit, CLEVR-Change, CLEVR-DC, and OmniDiff, demonstrating significant improvements in cross-scenario difference recognition accuracy compared to existing methods. The dataset, code, and models will be made publicly available to support further research.