Perceive, Understand and Restore: Real-World Image Super-Resolution with Autoregressive Multimodal Generative Models
作者: Hongyang Wei, Shuaizheng Liu, Chun Yuan, Lei Zhang
分类: cs.CV
发布日期: 2025-03-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出PURE模型,利用自回归多模态生成模型实现鲁棒的真实世界图像超分辨率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像超分辨率 自回归模型 多模态学习 生成模型 指令微调 图像恢复 真实世界图像 Lumina-mGPT
📋 核心要点
- 现有Real-ISR方法在复杂场景下重建效果不佳,原因是它们对低质量图像的感知和理解能力不足。
- PURE模型利用预训练的自回归多模态模型,通过指令微调使其具备感知、理解和恢复图像的能力。
- 实验表明,PURE模型在复杂场景下能生成更逼真的细节,并有效保留图像内容。
📝 摘要(中文)
本文提出了一种名为PURE的真实世界图像超分辨率(Real-ISR)模型,该模型首次将预训练的自回归多模态模型(如Lumina-mGPT)应用于该任务。现有方法通常依赖于预训练的文本到图像扩散模型的生成先验,但在复杂或严重退化的场景中,由于对输入低质量图像的感知和理解能力有限,容易产生不准确和不自然的重建结果。PURE通过指令微调Lumina-mGPT,使其能够感知图像退化程度和已生成图像token与下一个token之间的关系,理解图像内容并生成图像语义描述,从而自回归地生成高质量图像token以恢复图像。此外,本文还发现图像token熵反映了图像结构,并提出了一种基于熵的Top-k采样策略来优化图像的局部结构。实验结果表明,PURE在保留图像内容的同时生成逼真的细节,尤其是在具有多个对象的复杂场景中,展示了自回归多模态生成模型在鲁棒Real-ISR方面的潜力。
🔬 方法详解
问题定义:真实世界图像超分辨率(Real-ISR)旨在从低质量图像重建高质量图像。现有方法,特别是基于预训练文本到图像扩散模型的方法,在处理复杂场景或严重退化图像时,由于缺乏对输入图像的充分理解,容易产生不准确和不自然的重建结果。这些方法难以准确感知图像的退化程度和图像内容,导致生成的结果与真实场景不符。
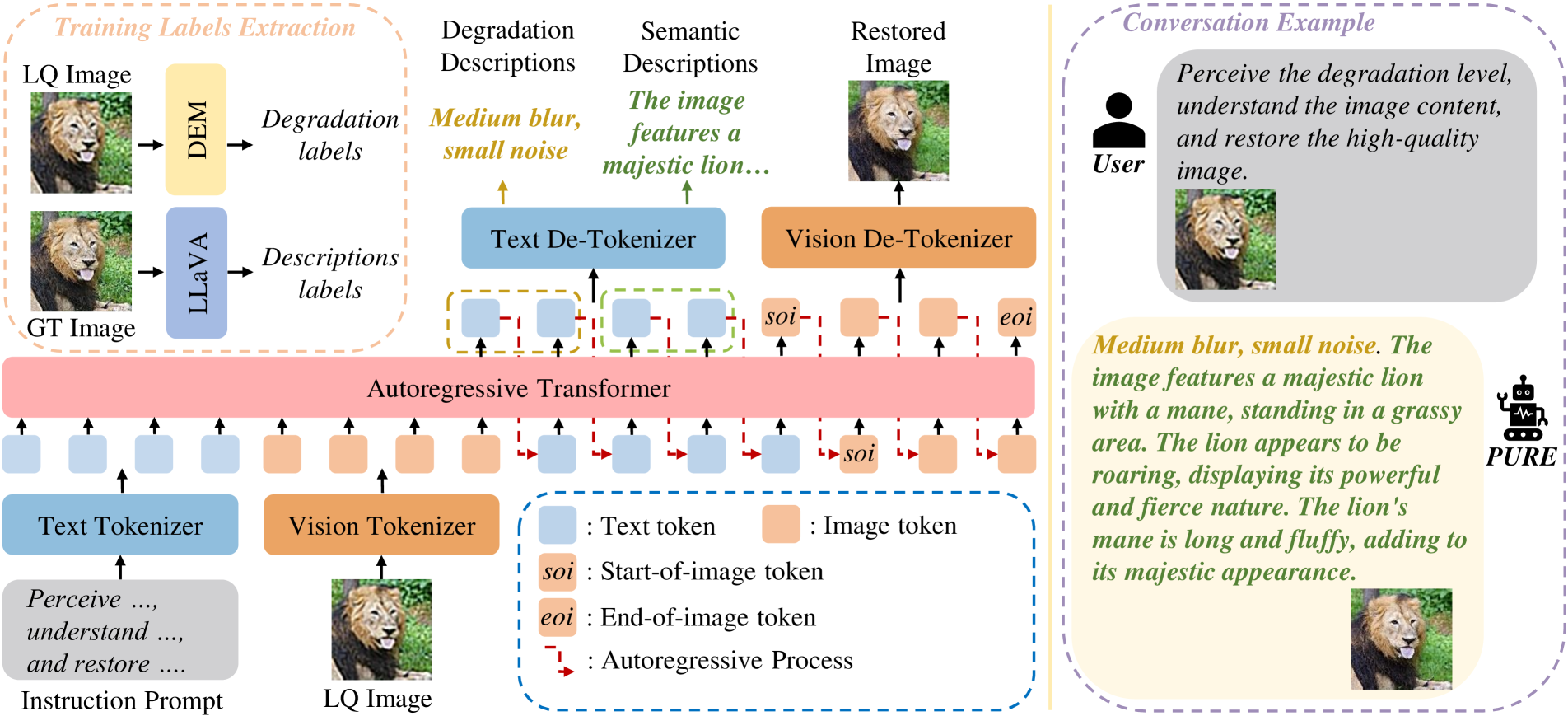
核心思路:PURE的核心思路是利用预训练的自回归多模态模型(如Lumina-mGPT)的强大感知和生成能力,通过指令微调,使其能够理解输入低质量图像的内容和退化特征,并自回归地生成高质量的图像token。这种方法模拟了人类的感知、理解和恢复过程,从而能够更准确地重建图像。
技术框架:PURE模型的整体框架包括以下几个主要阶段:1) 感知阶段:模型接收低质量图像作为输入,并通过指令微调学习感知图像的退化程度。2) 理解阶段:模型生成图像的语义描述,从而理解图像的内容。3) 恢复阶段:模型基于感知到的退化程度和理解到的图像内容,自回归地生成高质量的图像token,逐步恢复图像。
关键创新:PURE的关键创新在于首次将预训练的自回归多模态模型应用于Real-ISR任务,并利用指令微调使其具备感知和理解图像内容的能力。此外,本文还提出了基于图像token熵的Top-k采样策略,用于优化图像的局部结构,从而生成更逼真的细节。与现有方法相比,PURE能够更准确地理解图像内容和退化特征,从而生成更准确和自然的重建结果。
关键设计:PURE模型使用Lumina-mGPT作为基础模型,并通过指令微调来适应Real-ISR任务。指令微调的目标是使模型能够根据输入的低质量图像生成高质量的图像token。此外,本文还提出了一种基于熵的Top-k采样策略,该策略根据图像token的熵值来选择下一个要生成的token,从而优化图像的局部结构。具体的参数设置和损失函数等技术细节在论文中有详细描述,代码已开源。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PURE模型在复杂场景下能够生成更逼真的细节,并有效保留图像内容。与现有方法相比,PURE在多个Real-ISR数据集上取得了显著的性能提升。例如,在包含多个对象的复杂场景中,PURE能够更准确地重建图像的细节,并生成更自然的纹理。具体的性能数据和对比基线可以在论文中找到。
🎯 应用场景
PURE模型在图像修复、视频增强、医学影像处理等领域具有广泛的应用前景。它可以用于提高监控视频的清晰度,修复老旧照片,增强医学影像的诊断效果,以及改善低分辨率图像的视觉质量。该研究的实际价值在于提供了一种更鲁棒和准确的Real-ISR解决方案,未来可能推动相关领域的发展。
📄 摘要(原文)
By leveraging the generative priors from pre-trained text-to-image diffusion models, significant progress has been made in real-world image super-resolution (Real-ISR). However, these methods tend to generate inaccurate and unnatural reconstructions in complex and/or heavily degraded scenes, primarily due to their limited perception and understanding capability of the input low-quality image. To address these limitations, we propose, for the first time to our knowledge, to adapt the pre-trained autoregressive multimodal model such as Lumina-mGPT into a robust Real-ISR model, namely PURE, which Perceives and Understands the input low-quality image, then REstores its high-quality counterpart. Specifically, we implement instruction tuning on Lumina-mGPT to perceive the image degradation level and the relationships between previously generated image tokens and the next token, understand the image content by generating image semantic descriptions, and consequently restore the image by generating high-quality image tokens autoregressively with the collected information. In addition, we reveal that the image token entropy reflects the image structure and present a entropy-based Top-k sampling strategy to optimize the local structure of the image during inference. Experimental results demonstrate that PURE preserves image content while generating realistic details, especially in complex scenes with multiple objects, showcasing the potential of autoregressive multimodal generative models for robust Real-ISR. The model and code will be available at https://github.com/nonwhy/PURE.