MAVFlow: Preserving Paralinguistic Elements with Conditional Flow Matching for Zero-Shot AV2AV Multilingual Translation
作者: Sungwoo Cho, Jeongsoo Choi, Sungnyun Kim, Se-Young Yun
分类: eess.AS, cs.CV, cs.LG, cs.MM
发布日期: 2025-03-14 (更新: 2025-07-30)
备注: Accepted to ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MAVFlow,利用条件流匹配实现零样本AV2AV多语种翻译,保持说话人一致性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频翻译 零样本学习 条件流匹配 说话人一致性 多模态融合
📋 核心要点
- 现有AV2AV翻译模型难以在翻译过程中保持说话人的语音和面部特征一致性。
- 提出基于条件流匹配的零样本音视频渲染器,利用音频和视觉模态的双重引导,保留说话人特征。
- 实验表明,该方法通过高质量梅尔频谱和面部信息条件化,提升了语音合成质量和面部生成效果。
📝 摘要(中文)
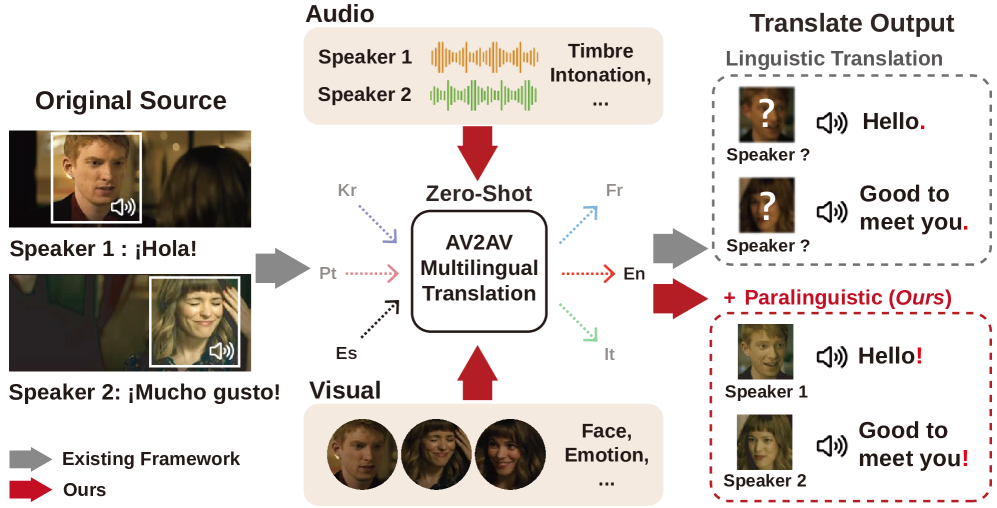
本文提出了一种条件流匹配(CFM)零样本音视频渲染器,用于解决音视频到音视频(AV2AV)翻译中说话人一致性保持的难题。该方法利用来自音频和视觉模态的双重强引导,通过多模态引导增强CFM过程,从而稳健地保留说话人特征,提升零样本AV2AV翻译能力。在音频模态方面,通过集成带有x-vectors的鲁棒说话人嵌入来增强CFM过程,从而加强说话人一致性。此外,模型还将情感细微差别传递到面部渲染模块。音频和视觉线索提供的引导独立于语义或语言内容,使渲染器能够有效处理不同语言的单语说话人的零样本翻译任务。实验结果表明,高质量的、以面部信息为条件的梅尔频谱不仅提高了合成语音的质量,而且对面部生成产生了积极影响,从而全面提升了LSE和FID评分。
🔬 方法详解
问题定义:AV2AV(Audio-Visual to Audio-Visual)翻译旨在将一种语言的音视频转换为另一种语言的音视频,同时保持说话人的身份特征(包括语音和面部特征)。现有方法在零样本场景下,难以保证翻译后音视频中说话人身份的一致性,即翻译后的语音和面部表情仍然像原始说话人。
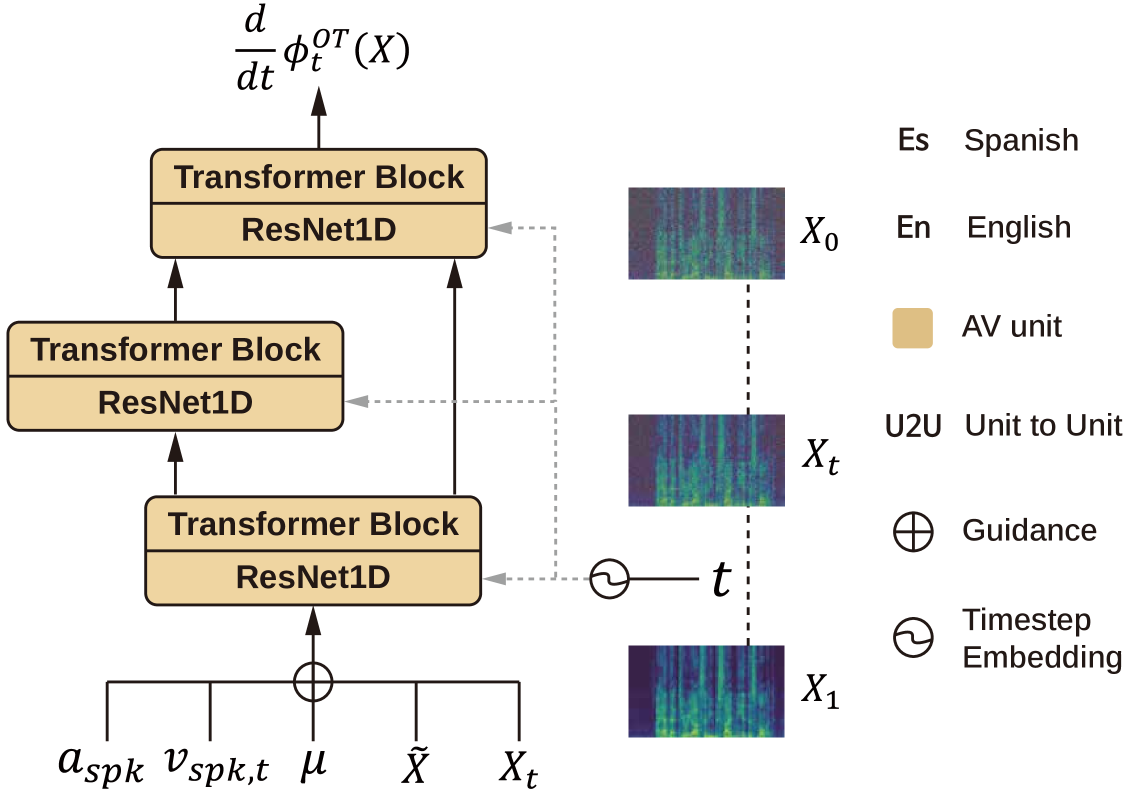
核心思路:论文的核心思路是利用条件流匹配(Conditional Flow Matching, CFM)框架,并结合音频和视觉模态的强引导,训练一个零样本音视频渲染器。通过音频和视觉信息的双重约束,模型能够更好地学习说话人的身份特征,并在翻译过程中保持这些特征。
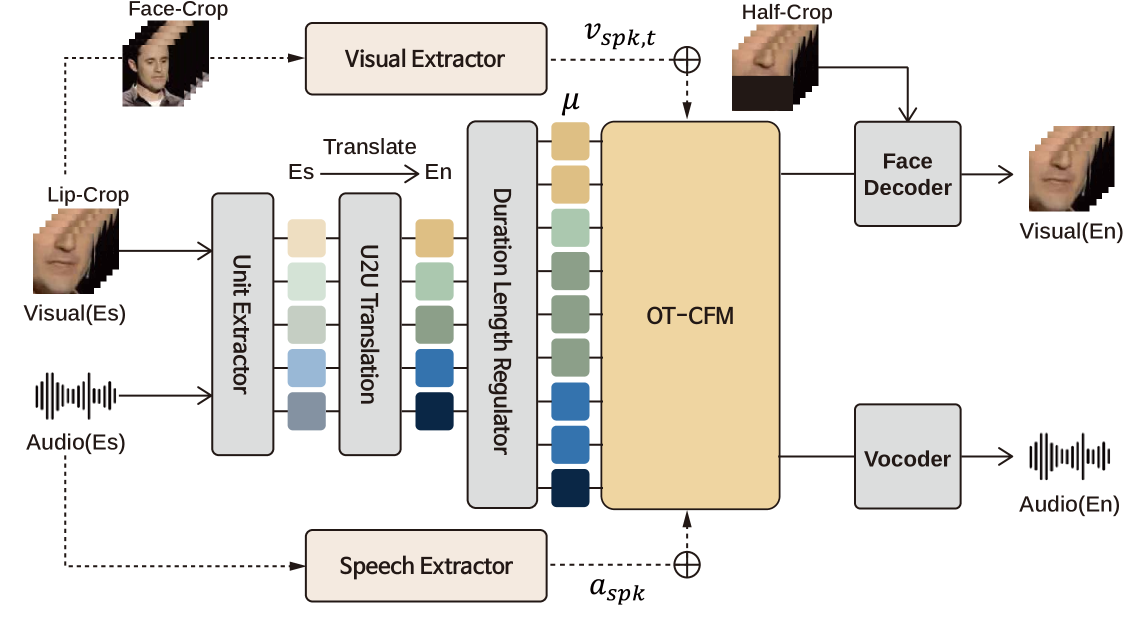
技术框架:MAVFlow的整体框架包含以下几个主要模块: 1. 音频编码器:提取音频特征,并使用x-vectors进行说话人嵌入。 2. 视觉编码器:提取面部特征,并传递情感信息。 3. 条件流匹配(CFM)模块:基于音频和视觉特征,生成目标语音和面部。 4. 语音合成器:将CFM模块生成的语音特征转换为最终的语音。 5. 面部渲染器:将CFM模块生成的面部特征渲染成最终的面部图像。
关键创新:该论文的关键创新在于: 1. 多模态引导的CFM:同时利用音频和视觉信息作为条件,引导CFM过程,从而更有效地学习和保持说话人特征。 2. 说话人嵌入增强:通过集成x-vectors,增强了音频模态的说话人信息,提高了说话人一致性。 3. 情感信息传递:将情感信息从视觉模态传递到面部渲染模块,使翻译后的面部表情更自然。
关键设计: 1. 条件流匹配(CFM)损失函数:使用CFM损失函数训练模型,使模型能够学习从噪声到真实数据的映射。 2. 说话人嵌入损失函数:使用说话人嵌入损失函数,鼓励模型学习具有区分性的说话人特征。 3. 对抗损失函数:使用对抗损失函数,提高生成语音和面部的真实感。 4. 网络结构:音频和视觉编码器采用卷积神经网络(CNN),CFM模块采用基于Transformer的网络结构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MAVFlow在零样本AV2AV翻译任务中取得了显著的性能提升。具体而言,通过结合高质量的梅尔频谱和面部信息条件化,模型在语音合成质量(LSE)和面部生成质量(FID)方面均优于现有方法。具体数据指标(例如LSE和FID的具体数值以及与基线的对比)未知,但总体而言,该方法能够更好地保持说话人一致性,生成更自然、更真实的翻译结果。
🎯 应用场景
该研究成果可应用于多语种视频会议、电影配音、虚拟人物生成等领域。例如,在国际会议中,可以将演讲者的语音和面部表情实时翻译成其他语言,同时保持演讲者的身份特征。此外,该技术还可以用于创建具有不同语言和情感表达的虚拟人物,用于娱乐、教育等领域。
📄 摘要(原文)
Despite recent advances in text-to-speech (TTS) models, audio-visual-to-audio-visual (AV2AV) translation still faces a critical challenge: maintaining speaker consistency between the original and translated vocal and facial features. To address this issue, we propose a conditional flow matching (CFM) zero-shot audio-visual renderer that utilizes strong dual guidance from both audio and visual modalities. By leveraging multimodal guidance with CFM, our model robustly preserves speaker-specific characteristics and enhances zero-shot AV2AV translation abilities. For the audio modality, we enhance the CFM process by integrating robust speaker embeddings with x-vectors, which serve to bolster speaker consistency. Additionally, we convey emotional nuances to the face rendering module. The guidance provided by both audio and visual cues remains independent of semantic or linguistic content, allowing our renderer to effectively handle zero-shot translation tasks for monolingual speakers in different languages. We empirically demonstrate that the inclusion of high-quality mel-spectrograms conditioned on facial information not only enhances the quality of the synthesized speech but also positively influences facial generation, leading to overall performance improvements in LSE and FID score. Our code is available at https://github.com/Peter-SungwooCho/MAVFlow.