Fine-Grained Instruction-Guided Graph Reasoning for Vision-and-Language Navigation
作者: Yaohua Liu, Xinyuan Song, Yunfu Deng, Yifan Xie, Binkai Ou, Yan Zhong
分类: cs.CV, cs.AI
发布日期: 2025-03-14 (更新: 2025-12-23)
备注: 10 pages, 4 figures
💡 一句话要点
提出OIKG框架,通过细粒度指令引导的图推理提升视觉语言导航性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 图推理 指令引导 跨模态对齐 机器人导航
📋 核心要点
- 现有VLN方法在视觉和方向线索的解耦以及导航关键语义的提取方面存在不足,导致空间推理不精确。
- OIKG框架通过观察图交互机制解耦视觉和角度信息,并利用细粒度指令引导模块提取位置和对象信息。
- 在R2R和RxR基准测试中,OIKG框架在多个评估指标上取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种细粒度指令引导的图推理框架(OIKG),旨在提升视觉语言导航(VLN)任务的性能。现有方法通常以耦合的方式编码视觉和方向线索,并且在处理指令时没有显式地提取导航关键语义,导致不精确的空间推理和次优的跨模态对齐。为了解决这些挑战,OIKG框架引入了观察图交互机制,解耦角度和视觉线索,并通过几何嵌入增强有向边的表示,从而在导航图中实现更可靠的空间推理。此外,设计了一个细粒度指令引导模块,用于显式地从语言指令中提取和利用特定位置和以对象为中心的信息,从而促进语言语义和可导航轨迹之间更精确的跨模态对齐。通过联合整合结构化图推理和指令关键语义线索,该方法显著提高了智能体遵循复杂导航指令的能力。在R2R和RxR基准上的大量实验表明,该方法在多个评估指标上始终达到最先进的性能,验证了细粒度指令引导的图推理在视觉语言导航中的有效性。
🔬 方法详解
问题定义:视觉语言导航(VLN)任务要求智能体根据自然语言指令在复杂环境中导航。现有方法通常将视觉和方向线索耦合在一起编码,并且在处理指令时没有明确提取导航相关的语义信息,导致空间推理不准确,跨模态对齐效果不佳。这些问题限制了智能体在复杂环境中的导航能力。
核心思路:本文的核心思路是通过细粒度的指令引导来增强图推理能力。具体来说,首先解耦视觉和角度信息,增强导航图的空间表示能力;然后,从指令中提取位置和对象相关的语义信息,指导智能体进行更精确的跨模态对齐。这样可以提高智能体对复杂指令的理解和执行能力。
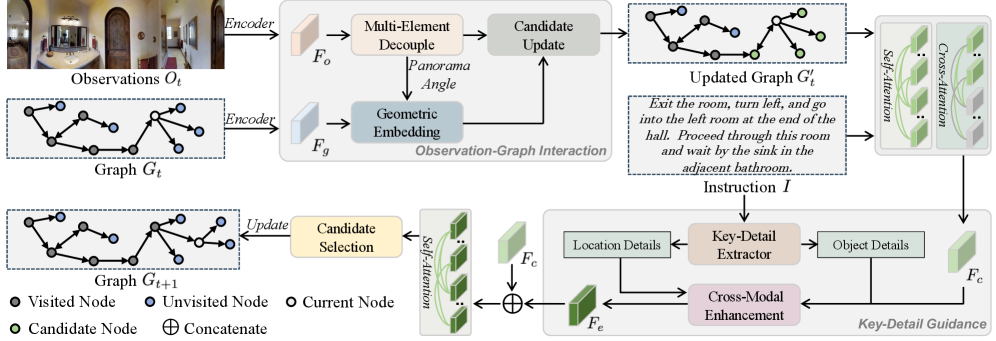
技术框架:OIKG框架主要包含两个核心模块:观察图交互机制和细粒度指令引导模块。观察图交互机制用于解耦视觉和角度信息,并通过几何嵌入增强有向边的表示。细粒度指令引导模块用于从语言指令中提取位置和对象相关的语义信息,并将其用于指导智能体的导航决策。整体流程是:首先,智能体观察环境并构建导航图;然后,利用观察图交互机制增强图的表示;接着,利用细粒度指令引导模块提取指令语义;最后,智能体根据图表示和指令语义进行导航决策。
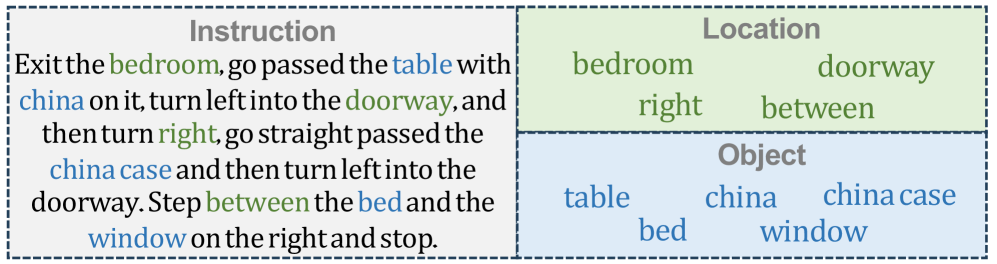
关键创新:该方法最重要的创新点在于将细粒度的指令信息融入到图推理过程中。与现有方法不同,OIKG框架显式地提取指令中的位置和对象信息,并将其用于指导智能体的导航决策。这种细粒度的指令引导可以帮助智能体更准确地理解指令,并做出更合理的导航决策。
关键设计:观察图交互机制使用几何嵌入来增强有向边的表示,具体来说,使用节点的坐标信息来计算边的几何特征,并将这些特征融入到边的表示中。细粒度指令引导模块使用注意力机制来提取指令中的位置和对象信息,并使用这些信息来调整智能体的导航策略。损失函数包括导航损失和辅助损失,导航损失用于优化智能体的导航策略,辅助损失用于优化指令语义的提取。
🖼️ 关键图片

📊 实验亮点
在R2R和RxR基准测试中,OIKG框架在多个评估指标上取得了显著的性能提升。例如,在R2R数据集上,OIKG框架的SPL指标比现有最佳方法提高了超过2%。在RxR数据集上,OIKG框架也取得了类似的性能提升,验证了该方法在不同数据集上的泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。例如,在服务机器人领域,可以利用该技术使机器人能够更好地理解人类的指令,并在复杂环境中完成导航任务。在自动驾驶领域,可以提高自动驾驶系统对交通规则和路况的理解能力,从而提高驾驶安全性。在虚拟现实领域,可以使虚拟角色能够更好地理解用户的指令,并在虚拟环境中进行交互。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) requires an embodied agent to traverse complex environments by following natural language instructions, demanding accurate alignment between visual observations and linguistic guidance. Despite recent progress, existing methods typically encode visual and directional cues in a coupled manner, and process instructions without explicitly extracting navigation-critical semantics, which often leads to imprecise spatial reasoning and suboptimal cross-modal alignment. To address these challenges, we propose a fine-grained instruction-guided graph reasoning framework (OIKG) that enhances both spatial representation and instruction understanding during navigation. Specifically, an observation-graph interaction mechanism is introduced to disentangle angular and visual cues while strengthening directed edge representations through geometric embedding, enabling more reliable spatial reasoning within the navigation graph. In addition, a fine-grained instruction guidance module is designed to explicitly extract and leverage location-specific and object-centric information from language instructions, facilitating more precise cross-modal alignment between linguistic semantics and navigable trajectories. By jointly integrating structured graph reasoning with instruction-critical semantic cues, the proposed approach significantly improves the agent's ability to follow complex navigation instructions. Extensive experiments on the R2R and RxR benchmarks demonstrate that our method consistently achieves state-of-the-art performance across multiple evaluation metrics, validating the effectiveness of fine-grained instruction-guided graph reasoning for vision-and-language navigation.