HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
作者: Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, Chengkai Hou, Mengdi Zhao, KC alex Zhou, Pheng-Ann Heng, Shanghang Zhang
分类: cs.CV, cs.RO
发布日期: 2025-03-13 (更新: 2025-06-23)
💡 一句话要点
HybridVLA:融合扩散模型与自回归的统一视觉-语言-动作模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 扩散模型 自回归模型 机器人操纵 协作训练 动作集成 连续控制
📋 核心要点
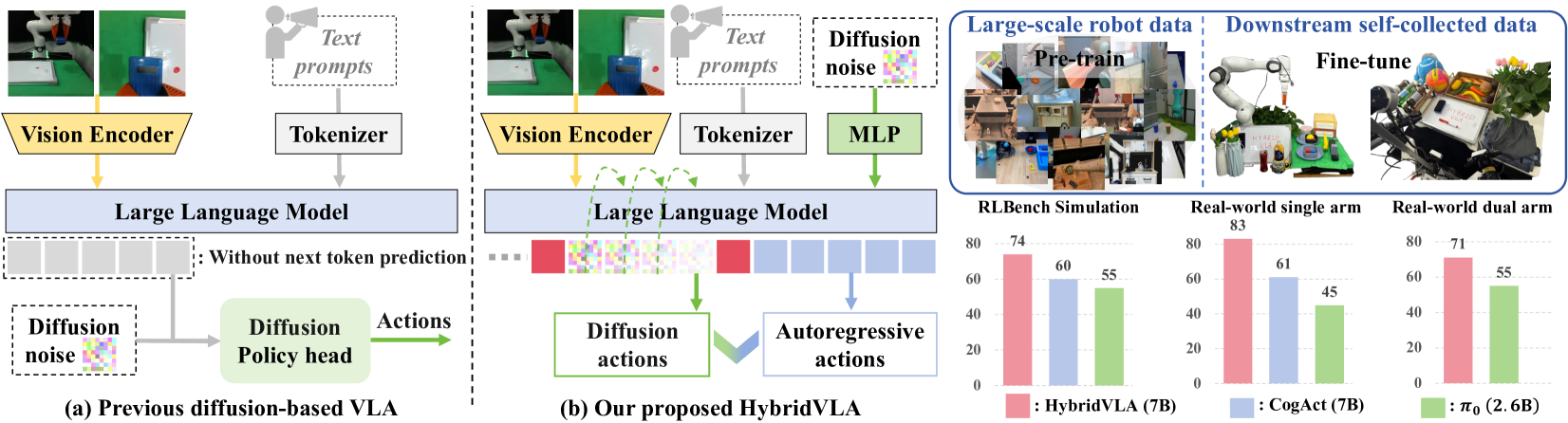
- 现有自回归VLA方法离散化动作导致控制精度不足,而扩散VLA方法未能充分利用VLM的token级推理能力。
- HybridVLA融合扩散模型的连续动作生成和自回归模型的上下文推理,实现更精确和鲁棒的机器人控制。
- 实验表明,HybridVLA在模拟和真实世界任务中显著优于现有VLA方法,平均成功率分别提升14%和19%。
📝 摘要(中文)
操纵策略设计的根本目标是赋予机器人理解人类指令、推理场景线索并在动态环境中执行通用动作的能力。最近的自回归视觉-语言-动作(VLA)方法继承了视觉-语言模型(VLM)的常识推理能力,用于预测下一个动作token。然而,这些方法将动作量化为离散的bins,破坏了精确控制所需的连续性。相比之下,现有的基于扩散的VLA方法包含一个额外的扩散头,用于预测连续动作,仅以VLM提取的特征表示为条件,而没有通过token级别的生成充分利用VLM的预训练推理能力。为了解决这些限制,我们引入了HybridVLA,这是一个统一的框架,在一个大型语言模型中吸收了基于扩散的动作的连续性和自回归的上下文推理。为了减轻两种生成范式之间的干扰,我们提出了一种协作训练方法,将扩散去噪无缝地融入到下一个token的预测过程中。通过这种方法,我们发现这两种动作预测方法不仅相互加强,而且在不同的任务中表现出不同的优势。因此,我们设计了一种协作动作集成机制,自适应地融合两种预测,从而实现更鲁棒的控制。HybridVLA在模拟和真实世界任务中的平均成功率分别比之前的最先进的VLA方法高出14%和19%,同时在未见过的配置中表现出稳定的操作。
🔬 方法详解
问题定义:现有VLA方法在机器人操纵任务中存在局限性。自回归方法将动作离散化,损失了动作的连续性,影响控制精度。扩散模型方法虽然能生成连续动作,但未能充分利用VLM的token级推理能力,限制了其性能。因此,需要一种既能生成连续动作,又能有效利用VLM推理能力的方法。
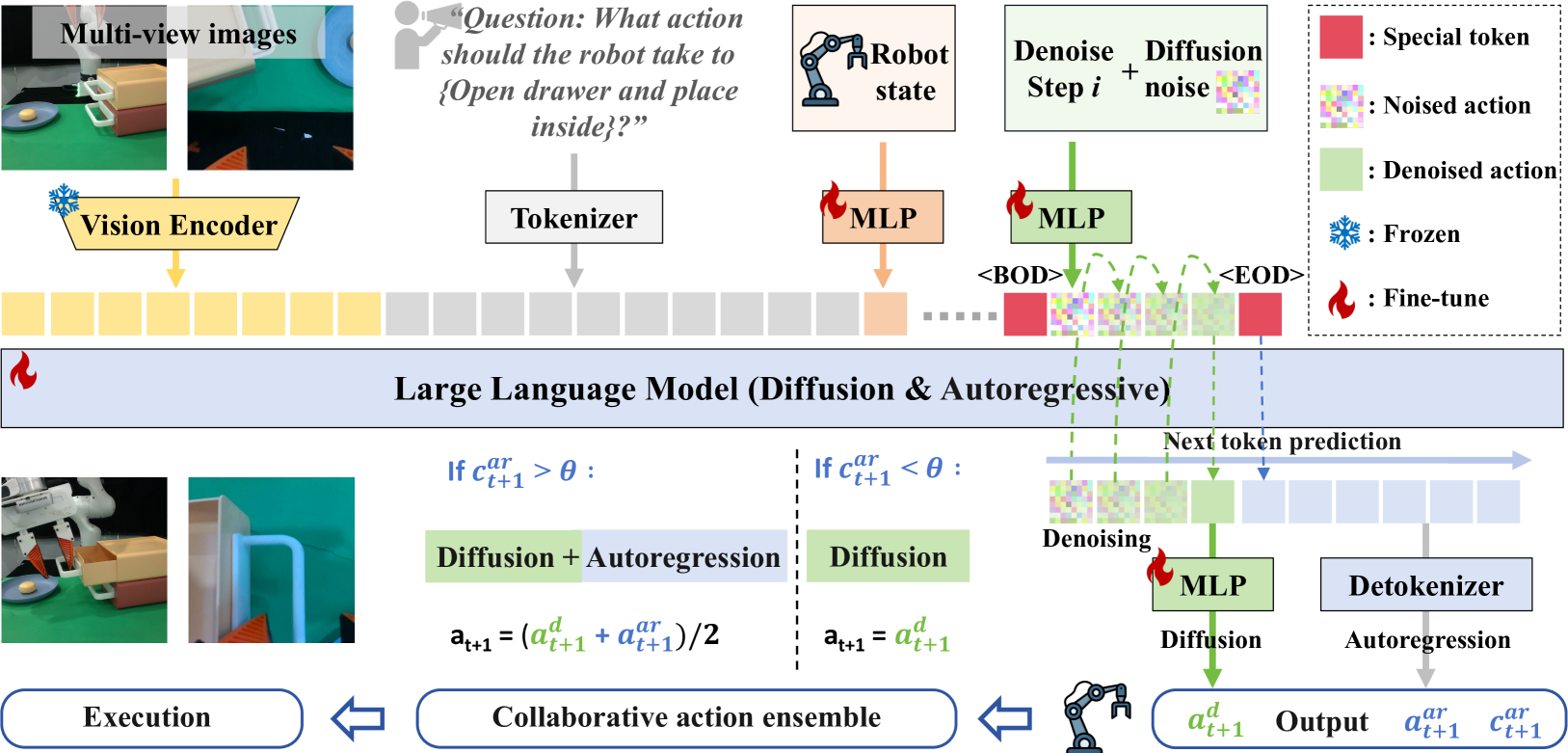
核心思路:HybridVLA的核心思路是将扩散模型和自回归模型融合到一个统一的框架中。通过结合扩散模型的连续动作生成能力和自回归模型的上下文推理能力,实现更精确和鲁棒的机器人控制。这种融合允许模型在利用VLM的预训练知识的同时,生成连续的动作序列。
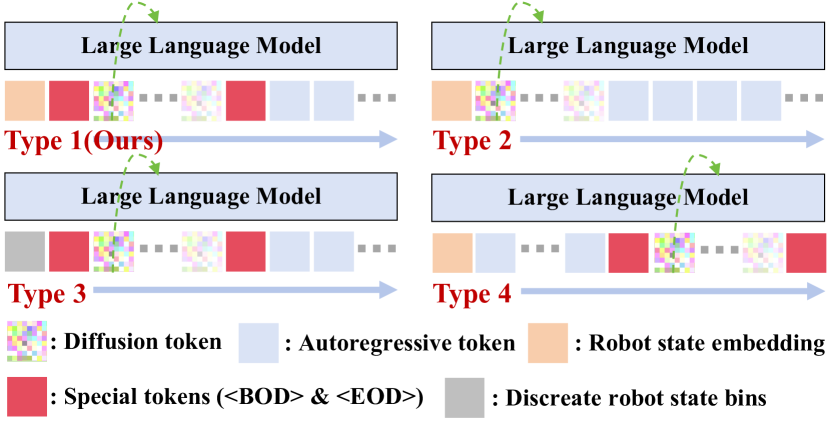
技术框架:HybridVLA的整体架构包含一个大型语言模型,该模型同时执行自回归的token预测和扩散模型的去噪过程。VLM提取的特征表示被用于条件化这两个过程。协作训练方法用于减轻两种生成范式之间的干扰。协作动作集成机制自适应地融合两种预测,从而实现更鲁棒的控制。
关键创新:HybridVLA的关键创新在于其统一的框架,该框架能够同时利用扩散模型和自回归模型的优势。协作训练方法和协作动作集成机制是实现这种融合的关键。与现有方法相比,HybridVLA能够生成更连续、更精确的动作,并更好地利用VLM的推理能力。
关键设计:协作训练方法通过将扩散去噪过程融入到下一个token的预测过程中,来减轻两种生成范式之间的干扰。协作动作集成机制通过自适应地融合两种预测,来提高控制的鲁棒性。具体的融合权重可能是根据任务类型或当前状态动态调整的。损失函数可能包含自回归预测损失和扩散模型的去噪损失,并可能通过某种方式进行平衡。
🖼️ 关键图片
📊 实验亮点
HybridVLA在模拟和真实世界任务中均取得了显著的性能提升。在模拟环境中,HybridVLA的平均成功率比之前的SOTA方法高出14%。在真实世界环境中,HybridVLA的平均成功率比之前的SOTA方法高出19%。这些结果表明,HybridVLA能够有效地融合扩散模型和自回归模型的优势,实现更精确和鲁棒的机器人控制。
🎯 应用场景
HybridVLA可应用于各种机器人操纵任务,例如家庭服务机器人、工业自动化机器人和医疗机器人。该方法能够使机器人更好地理解人类指令,并在复杂环境中执行精确的动作。未来,HybridVLA可以扩展到更复杂的任务,例如多机器人协作和人机协作。
📄 摘要(原文)
A fundamental objective of manipulation policy design is to endow robots to comprehend human instructions, reason about scene cues, and execute generalized actions in dynamic environments. Recent autoregressive vision-language-action (VLA) methods inherit common-sense reasoning capabilities from vision-language models (VLMs) for next action-token prediction. However, these methods quantize actions into discrete bins, which disrupts the continuity required for precise control. In contrast, existing diffusion-based VLA methods incorporate an additional diffusion head to predict continuous actions solely conditioned on feature representations extracted by the VLM, without fully leveraging the VLM's pretrained reasoning capabilities through token-level generation. To address these limitations, we introduce HybridVLA, a unified framework that absorbs the continuous nature of diffusion-based actions and the contextual reasoning of autoregression within a single large language model. To mitigate interference between the two generation paradigms, we propose a collaborative training recipe that seamlessly incorporates diffusion denoising into the next-token prediction process. With this recipe, we find these two action prediction methods not only reinforce each other but also exhibit varying strength across different tasks. Therefore, we design a collaborative action ensemble mechanism that adaptively fuses both predictions, leading to more robust control. HybridVLA outperforms previous state-of-the-art VLA methods by 14\% and 19\% in mean success rate on simulation and real-world tasks, respectively, while demonstrating stable manipulation in unseen configurations.