UniGoal: Towards Universal Zero-shot Goal-oriented Navigation
作者: Hang Yin, Xiuwei Xu, Lingqing Zhao, Ziwei Wang, Jie Zhou, Jiwen Lu
分类: cs.CV, cs.RO
发布日期: 2025-03-13 (更新: 2025-03-18)
备注: Accepted to CVPR 2025. Project page: https://bagh2178.github.io/UniGoal/
💡 一句话要点
UniGoal:提出通用零样本目标导向导航框架,统一处理多种目标类型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 目标导向导航 图神经网络 大型语言模型 通用人工智能
📋 核心要点
- 现有零样本导航方法依赖特定任务的LLM框架,流程差异大,泛化性差,难以处理多种目标。
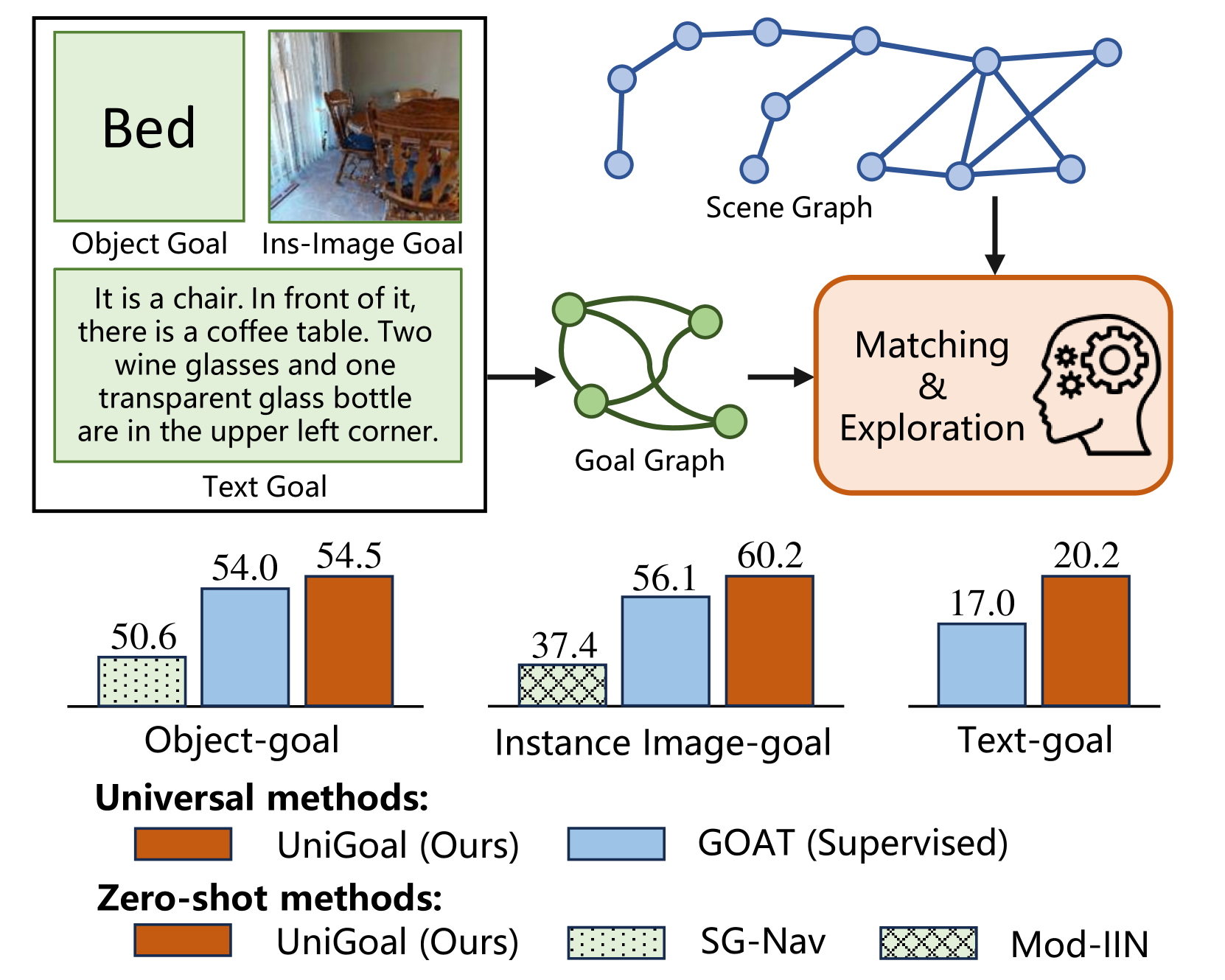
- UniGoal提出统一的图表示,将不同目标(类别、图像、文本)和场景信息转化为图结构,便于LLM推理。
- 实验表明,UniGoal在多个导航任务上,以单一模型超越了特定任务的零样本方法和监督通用方法。
📝 摘要(中文)
本文提出了一种通用的零样本目标导向导航框架。现有的零样本方法依赖于大型语言模型(LLM),针对特定任务构建推理框架,这些框架在整体流程上差异很大,无法推广到不同类型的目标。为了实现通用零样本导航,我们提出了一种统一的图表示来统一不同的目标,包括对象类别、实例图像和文本描述。我们还将智能体的观察结果转换为在线维护的场景图。通过这种一致的场景和目标表示,与纯文本相比,我们保留了大部分结构信息,并且能够利用LLM进行显式的基于图的推理。具体来说,我们在每个时间步进行场景图和目标图之间的图匹配,并根据不同的匹配状态提出不同的探索长期目标生成策略。智能体首先在零匹配时迭代搜索目标子图。在部分匹配的情况下,智能体利用坐标投影和锚点对齐来推断目标位置。最后,应用场景图校正和目标验证来实现完美匹配。我们还提出了一种黑名单机制,以实现阶段之间的鲁棒切换。在多个基准测试上的大量实验表明,我们的UniGoal在三个研究的导航任务上,使用单一模型实现了最先进的零样本性能,甚至优于特定任务的零样本方法和监督通用方法。
🔬 方法详解
问题定义:现有零样本目标导向导航方法通常针对特定类型的目标(例如,仅限于寻找特定类别的物体),并且依赖于为每个任务定制的LLM推理框架。这些框架在整体流程上差异很大,导致泛化能力不足,难以适应多种目标类型(例如,寻找特定实例的图像或满足文本描述的目标)。因此,如何设计一个通用的零样本导航框架,能够处理不同类型的目标,是本文要解决的核心问题。
核心思路:本文的核心思路是将不同类型的目标(对象类别、实例图像、文本描述)统一表示为图结构,并利用大型语言模型(LLM)进行基于图的推理。通过将场景信息也表示为图结构,可以有效地保留场景的结构信息,并方便进行场景图和目标图之间的匹配。这种统一的图表示方法使得可以使用相同的推理流程处理不同类型的目标,从而提高了泛化能力。
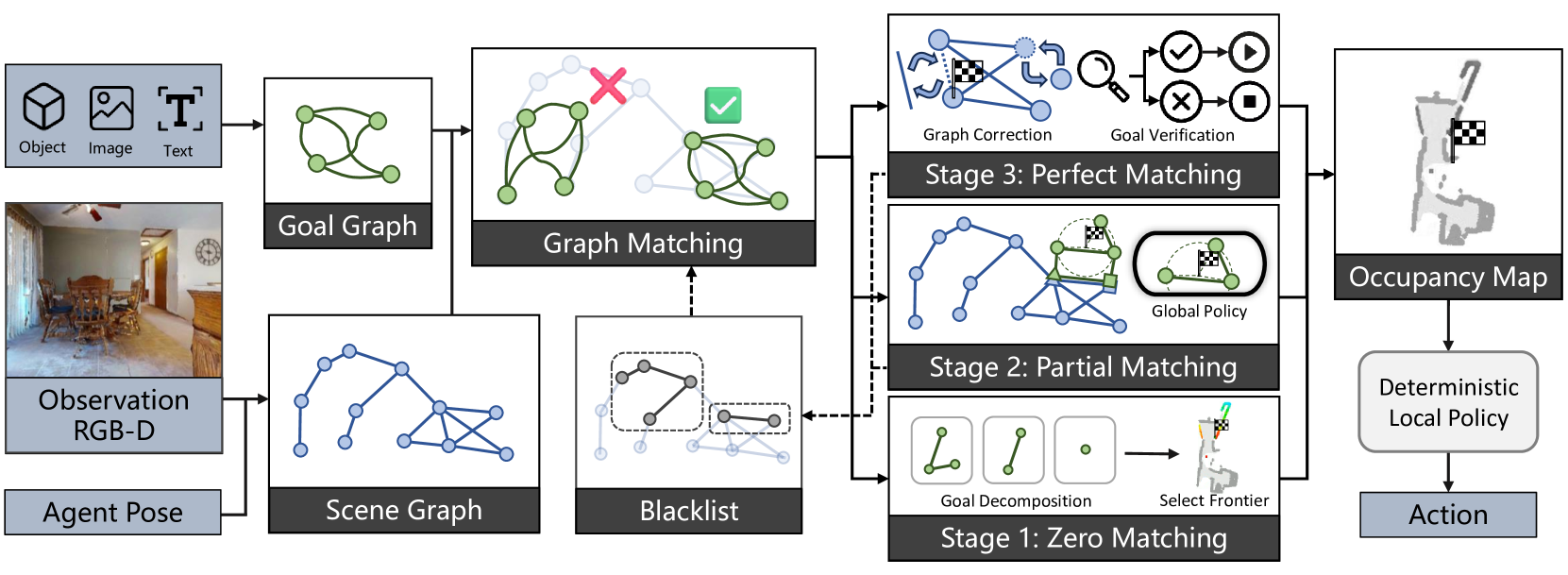
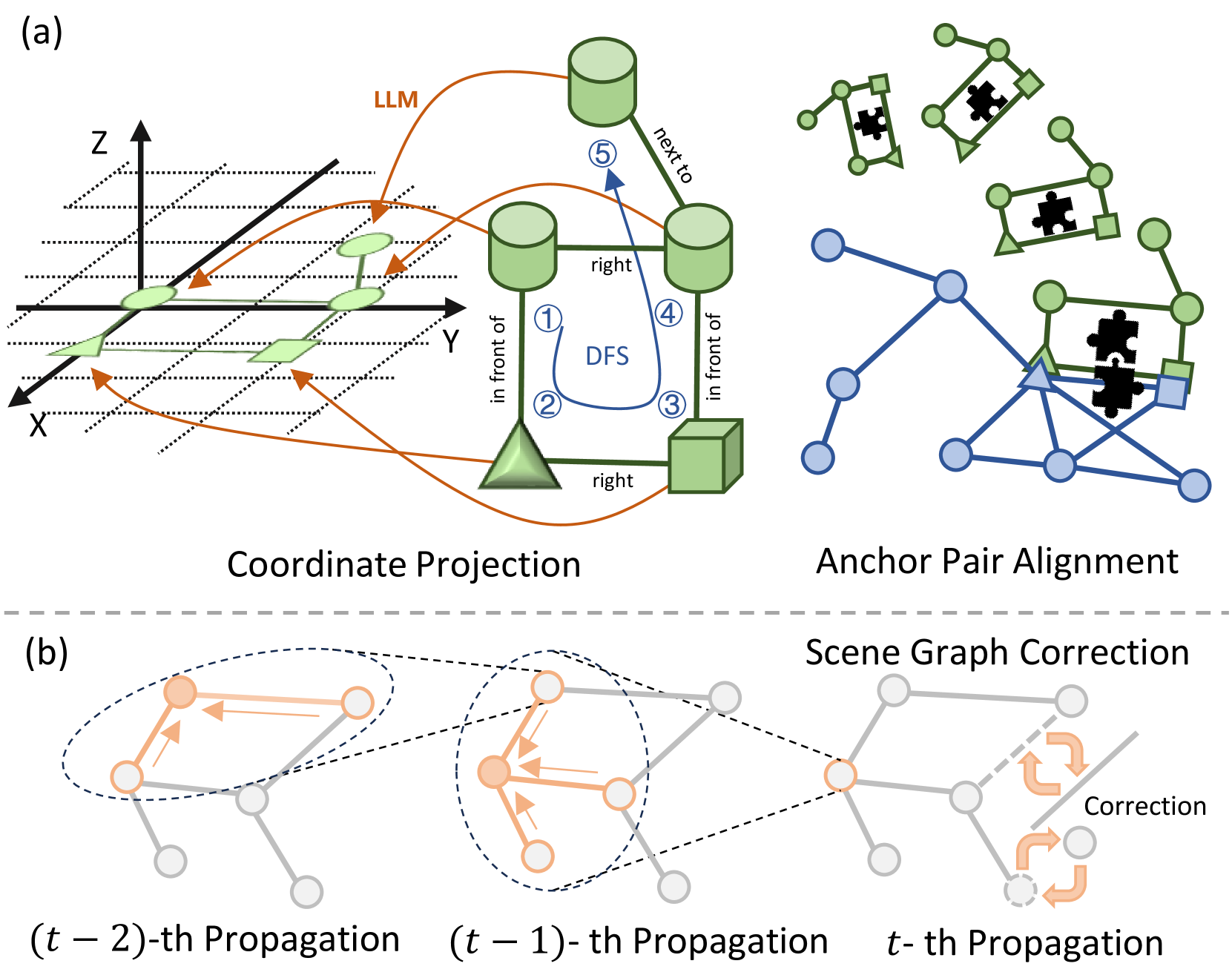
技术框架:UniGoal的整体框架包括以下几个主要模块:1) 场景图构建:将智能体的观察结果转换为在线维护的场景图。2) 目标图表示:将不同类型的目标(对象类别、实例图像、文本描述)统一表示为图结构。3) 图匹配:在每个时间步,进行场景图和目标图之间的图匹配,判断当前场景与目标的匹配程度。4) 长期目标生成:根据不同的匹配状态,生成不同的探索长期目标。具体来说,包括零匹配时的子图搜索、部分匹配时的坐标投影和锚点对齐,以及完美匹配时的场景图校正和目标验证。5) 黑名单机制:用于在不同阶段之间进行鲁棒切换,避免陷入局部最优。
关键创新:UniGoal最重要的技术创新点在于提出了统一的图表示方法,将不同类型的目标和场景信息都表示为图结构。这种统一的表示方法使得可以使用相同的推理流程处理不同类型的目标,从而提高了泛化能力。与现有方法相比,UniGoal避免了为每个任务定制LLM推理框架的需要,从而降低了开发成本,并提高了模型的通用性。
关键设计:在图匹配阶段,采用了不同的策略来处理不同的匹配状态。当场景图和目标图完全不匹配时(零匹配),智能体会迭代搜索目标图的子图,以寻找可能的匹配。当场景图和目标图部分匹配时,智能体会利用坐标投影和锚点对齐来推断目标位置。此外,还设计了一种黑名单机制,用于记录已经探索过的区域,避免重复探索,提高探索效率。
🖼️ 关键图片
📊 实验亮点
UniGoal在多个基准测试上取得了最先进的零样本性能,甚至优于特定任务的零样本方法和监督通用方法。具体来说,UniGoal在三个研究的导航任务上,使用单一模型实现了显著的性能提升,证明了其通用性和有效性。这些实验结果表明,UniGoal是一种非常有前景的通用零样本目标导向导航方法。
🎯 应用场景
UniGoal具有广泛的应用前景,例如,可以应用于家庭服务机器人、自动驾驶汽车、虚拟现实游戏等领域。在家庭服务机器人中,UniGoal可以帮助机器人理解用户的指令,例如“去厨房拿一个苹果”,并自主导航到厨房找到苹果。在自动驾驶汽车中,UniGoal可以帮助汽车理解导航指令,例如“开到最近的加油站”,并规划出最佳路线。在虚拟现实游戏中,UniGoal可以帮助玩家在虚拟环境中自由探索,完成各种任务。
📄 摘要(原文)
In this paper, we propose a general framework for universal zero-shot goal-oriented navigation. Existing zero-shot methods build inference framework upon large language models (LLM) for specific tasks, which differs a lot in overall pipeline and fails to generalize across different types of goal. Towards the aim of universal zero-shot navigation, we propose a uniform graph representation to unify different goals, including object category, instance image and text description. We also convert the observation of agent into an online maintained scene graph. With this consistent scene and goal representation, we preserve most structural information compared with pure text and are able to leverage LLM for explicit graph-based reasoning. Specifically, we conduct graph matching between the scene graph and goal graph at each time instant and propose different strategies to generate long-term goal of exploration according to different matching states. The agent first iteratively searches subgraph of goal when zero-matched. With partial matching, the agent then utilizes coordinate projection and anchor pair alignment to infer the goal location. Finally scene graph correction and goal verification are applied for perfect matching. We also present a blacklist mechanism to enable robust switch between stages. Extensive experiments on several benchmarks show that our UniGoal achieves state-of-the-art zero-shot performance on three studied navigation tasks with a single model, even outperforming task-specific zero-shot methods and supervised universal methods.