R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
作者: Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, Bo Zhang, Wei Chen
分类: cs.CV
发布日期: 2025-03-13 (更新: 2025-03-18)
备注: Code and Model: https://github.com/Fancy-MLLM/R1-onevision
💡 一句话要点
R1-Onevision:通过跨模态形式化提升通用多模态推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 跨模态形式化 视觉-语言模型 大型语言模型 数据集构建 强化学习 基准测试 通用人工智能
📋 核心要点
- 现有视觉-语言模型在分析和推理视觉内容方面存在不足,导致复杂推理任务性能受限,且缺乏全面的多模态推理基准。
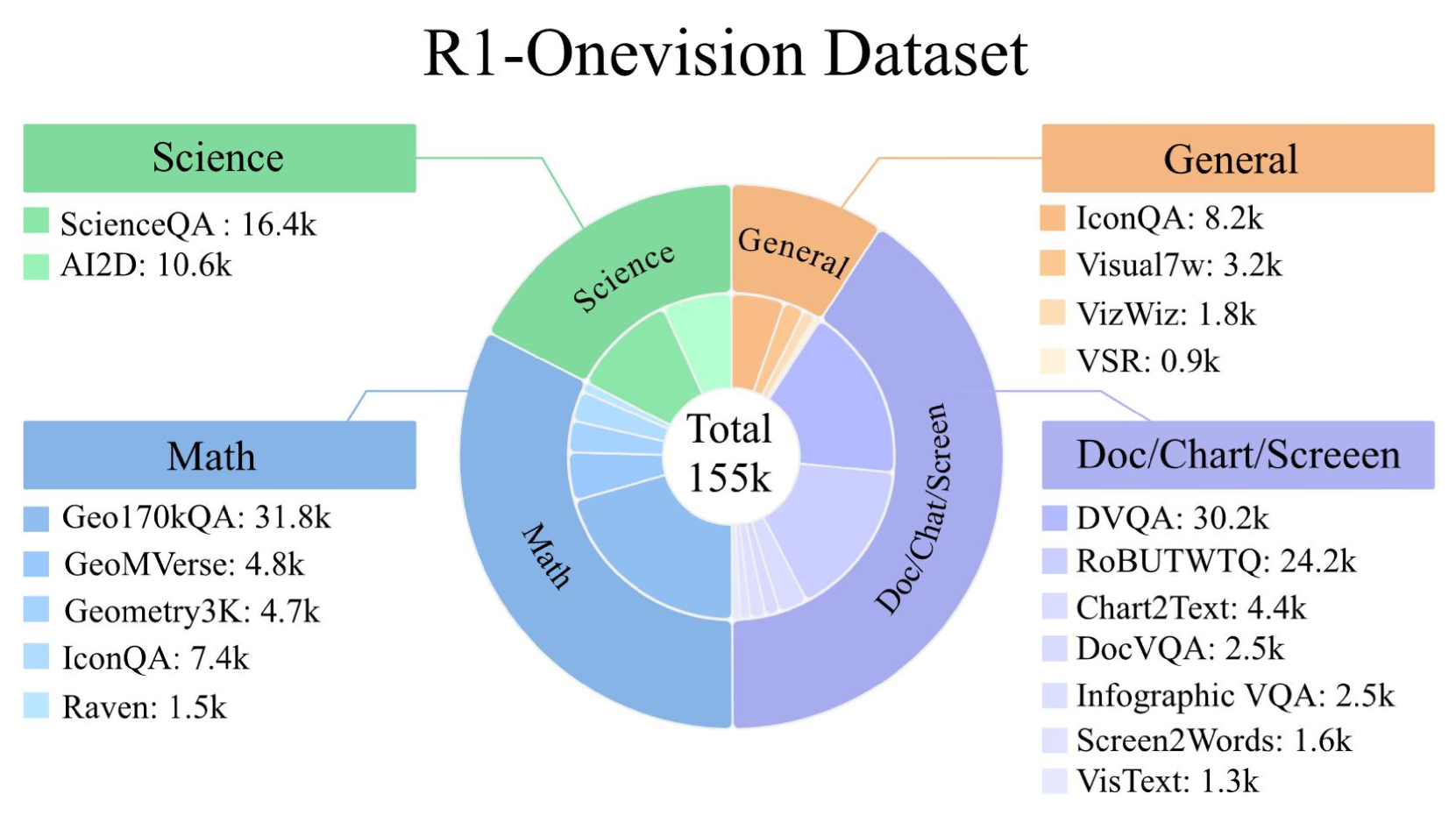
- R1-Onevision通过跨模态推理流程,将图像转换为形式化的文本表示,从而实现精确的基于语言的推理。
- R1-Onevision模型在多个具有挑战性的多模态推理基准上优于GPT-4o和Qwen2.5-VL等模型,达到最先进的性能。
📝 摘要(中文)
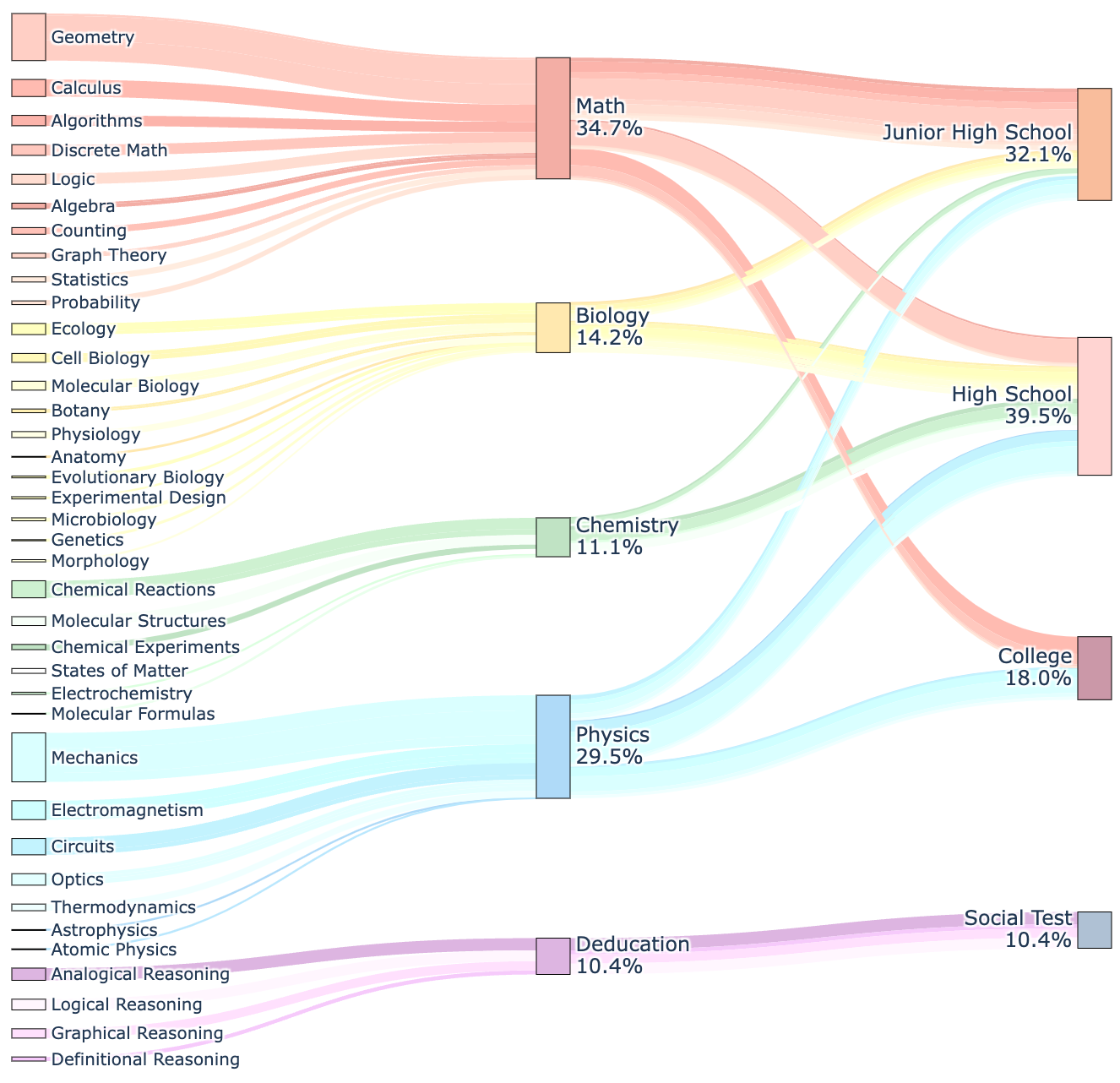
大型语言模型在复杂的文本任务中展现了卓越的推理能力。然而,需要整合视觉和文本信息的多模态推理仍然是一个重大挑战。现有的视觉-语言模型通常难以有效地分析和推理视觉内容,导致在复杂推理任务上的表现欠佳。此外,缺乏全面的基准测试阻碍了对多模态推理能力的准确评估。本文介绍了R1-Onevision,一种旨在弥合视觉感知和深度推理之间差距的多模态推理模型。为此,我们提出了一种跨模态推理流程,将图像转换为形式化的文本表示,从而实现精确的基于语言的推理。利用该流程,我们构建了R1-Onevision数据集,该数据集提供了跨不同领域的详细的、逐步的多模态推理标注。我们进一步通过监督微调和强化学习开发了R1-Onevision模型,以培养高级推理和强大的泛化能力。为了全面评估不同等级的多模态推理性能,我们推出了R1-Onevision-Bench,这是一个与人类教育阶段对齐的基准,涵盖从初中到大学及以上的考试。实验结果表明,R1-Onevision实现了最先进的性能,在多个具有挑战性的多模态推理基准上优于GPT-4o和Qwen2.5-VL等模型。
🔬 方法详解
问题定义:论文旨在解决现有视觉-语言模型在复杂多模态推理任务中表现不佳的问题。现有方法难以有效分析和推理视觉内容,导致性能瓶颈。此外,缺乏高质量的多模态推理数据集和基准测试,限制了模型能力的评估和提升。
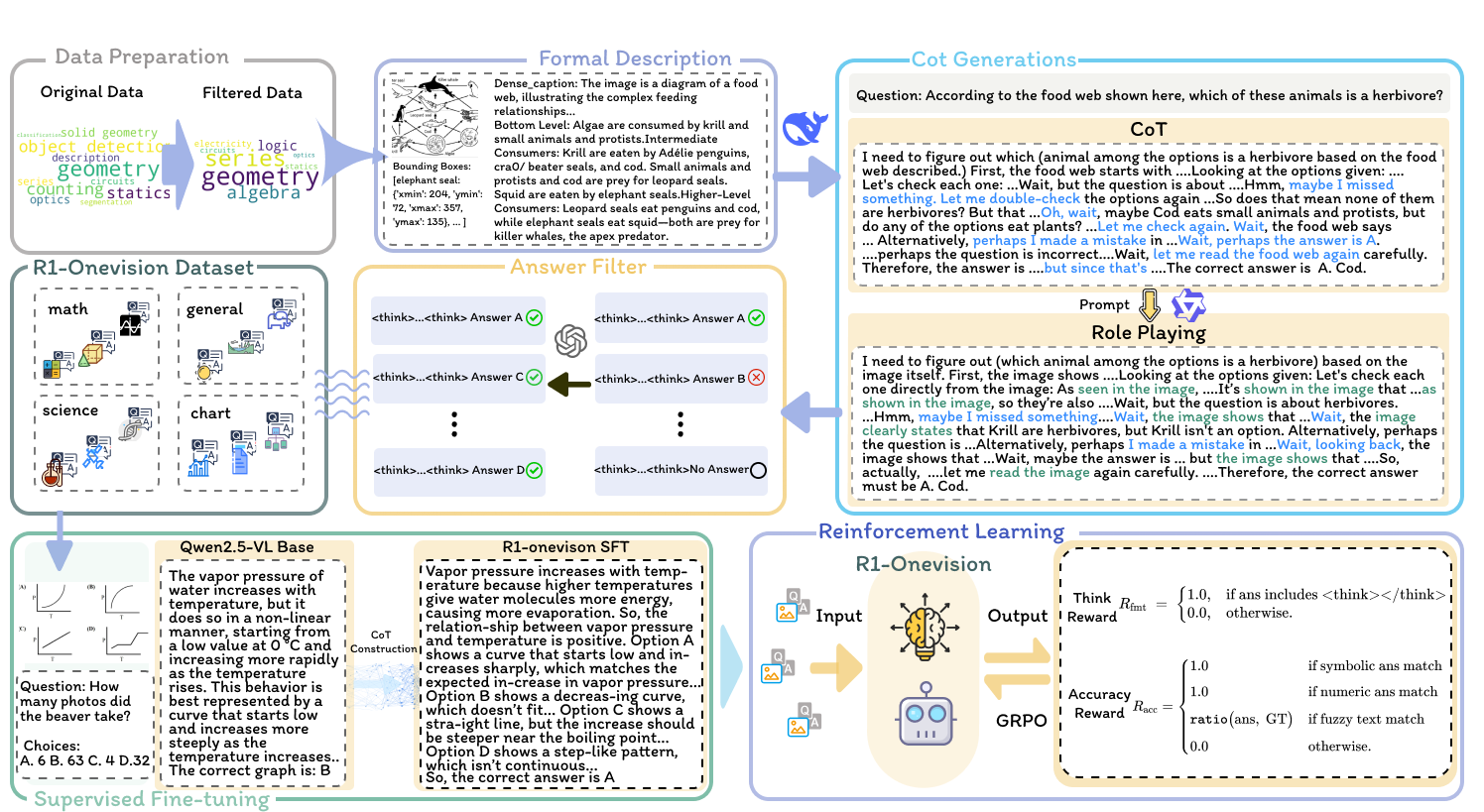
核心思路:论文的核心思路是将视觉信息转化为形式化的文本表示,从而利用大型语言模型强大的文本推理能力。通过将图像转换为文本,模型可以更精确地进行语言推理,从而提高多模态推理的准确性和效率。这种方法旨在弥合视觉感知和深度推理之间的差距。
技术框架:R1-Onevision的整体框架包含以下几个主要阶段:1) 图像编码:使用视觉编码器提取图像特征。2) 跨模态形式化:将图像特征转换为形式化的文本表示。3) 语言推理:利用大型语言模型对文本表示进行推理。4) 结果解码:将推理结果转换为最终的输出形式。该框架通过跨模态转换,实现了视觉信息和语言模型的有效融合。
关键创新:论文最重要的技术创新点在于提出了跨模态形式化的方法,将图像转换为形式化的文本表示。这种方法与现有方法的本质区别在于,它避免了直接对图像进行推理,而是利用语言模型强大的文本推理能力,从而提高了多模态推理的准确性和效率。
关键设计:论文的关键设计包括:1) 跨模态形式化的具体实现方式,例如使用特定的规则或模型将图像特征转换为文本。2) 损失函数的设计,用于优化跨模态转换和语言推理过程。3) 数据集的构建方式,包括标注的详细程度和多样性。4) 强化学习的使用,以进一步提升模型的推理和泛化能力。具体的参数设置和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
R1-Onevision在多个具有挑战性的多模态推理基准上取得了显著的性能提升,超越了GPT-4o和Qwen2.5-VL等先进模型。具体的数据和提升幅度在论文中应该有详细的展示(未知)。这些结果表明,R1-Onevision在多模态推理方面具有强大的能力和潜力。
🎯 应用场景
R1-Onevision的研究成果具有广泛的应用前景,包括智能教育、视觉问答、机器人导航、医学图像分析等领域。该模型可以用于开发更智能的教育辅导系统,帮助学生理解复杂的概念;也可以用于构建更强大的视觉问答系统,为用户提供更准确的信息;还可以应用于机器人导航,使机器人能够更好地理解周围环境;在医学图像分析领域,可以辅助医生进行疾病诊断和治疗。
📄 摘要(原文)
Large Language Models have demonstrated remarkable reasoning capability in complex textual tasks. However, multimodal reasoning, which requires integrating visual and textual information, remains a significant challenge. Existing visual-language models often struggle to effectively analyze and reason visual content, resulting in suboptimal performance on complex reasoning tasks. Moreover, the absence of comprehensive benchmarks hinders the accurate assessment of multimodal reasoning capabilities. In this paper, we introduce R1-Onevision, a multimodal reasoning model designed to bridge the gap between visual perception and deep reasoning. To achieve this, we propose a cross-modal reasoning pipeline that transforms images into formal textural representations, enabling precise language-based reasoning. Leveraging this pipeline, we construct the R1-Onevision dataset which provides detailed, step-by-step multimodal reasoning annotations across diverse domains. We further develop the R1-Onevision model through supervised fine-tuning and reinforcement learning to cultivate advanced reasoning and robust generalization abilities. To comprehensively evaluate multimodal reasoning performance across different grades, we introduce R1-Onevision-Bench, a benchmark aligned with human educational stages, covering exams from junior high school to university and beyond. Experimental results show that R1-Onevision achieves state-of-the-art performance, outperforming models such as GPT-4o and Qwen2.5-VL on multiple challenging multimodal reasoning benchmarks.