TokenCarve: Information-Preserving Visual Token Compression in Multimodal Large Language Models
作者: Xudong Tan, Peng Ye, Chongjun Tu, Jianjian Cao, Yaoxin Yang, Lin Zhang, Dongzhan Zhou, Tao Chen
分类: cs.CV
发布日期: 2025-03-13
🔗 代码/项目: GITHUB
💡 一句话要点
TokenCarve:一种面向多模态大语言模型的信息保持型视觉Token压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token压缩 信息保持 免训练 推理加速
📋 核心要点
- 多模态大语言模型面临视觉tokens带来的高计算成本挑战,现有方法或需昂贵重训练,或压缩性能不佳。
- TokenCarve通过信息保持引导选择(IPGS)策略,在token修剪和合并过程中最小化信息损失,实现高效压缩。
- 实验表明,TokenCarve能显著减少视觉tokens数量,加速推理,降低存储需求,同时保持较高的模型准确率。
📝 摘要(中文)
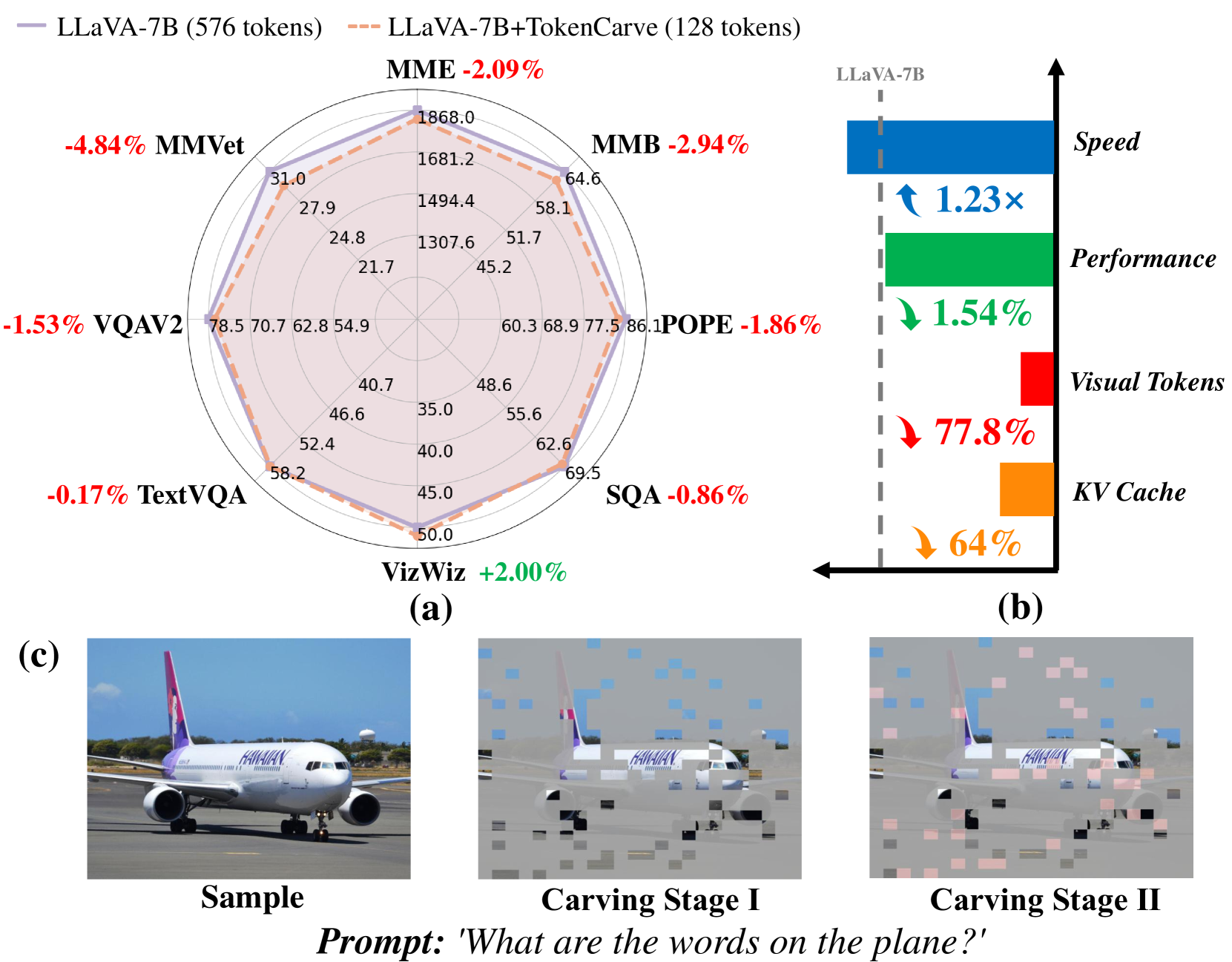
多模态大语言模型(MLLMs)日益普及,但多模态数据输入,特别是视觉tokens,带来了巨大的计算成本挑战。现有的基于训练的token压缩方法虽然提高了推理效率,但需要昂贵的重新训练。而免训练的方法在大幅减少token数量时难以维持性能。本研究揭示了MLLM的性能下降与注意力输出矩阵中信息加速丢失密切相关。这一洞察引入了一种新的信息保持视角,使得即使在极端token压缩下也能维持性能成为可能。基于此,我们提出了TokenCarve,一个免训练、即插即用的两阶段token压缩框架。第一阶段采用信息保持引导选择(IPGS)策略来修剪低信息量的tokens,第二阶段进一步利用IPGS来引导token合并,从而最小化信息损失。在11个数据集和2个模型变体上的大量实验证明了TokenCarve的有效性。它可以将视觉tokens的数量减少到原始数量的22.2%,实现1.23倍的推理加速,KV缓存存储减少64%,而准确率仅下降1.54%。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型中视觉tokens数量过多导致计算成本高昂的问题。现有基于训练的token压缩方法需要耗费大量资源进行重新训练,而免训练方法在大幅压缩tokens时性能下降明显,无法在效率和精度之间取得平衡。
核心思路:论文的核心思路是基于信息保持的视角进行token压缩。作者发现模型性能下降与注意力输出矩阵中的信息损失密切相关,因此提出在token选择和合并过程中,优先保留包含更多信息的tokens,从而在大幅压缩tokens数量的同时,尽可能地减少信息损失,维持模型性能。
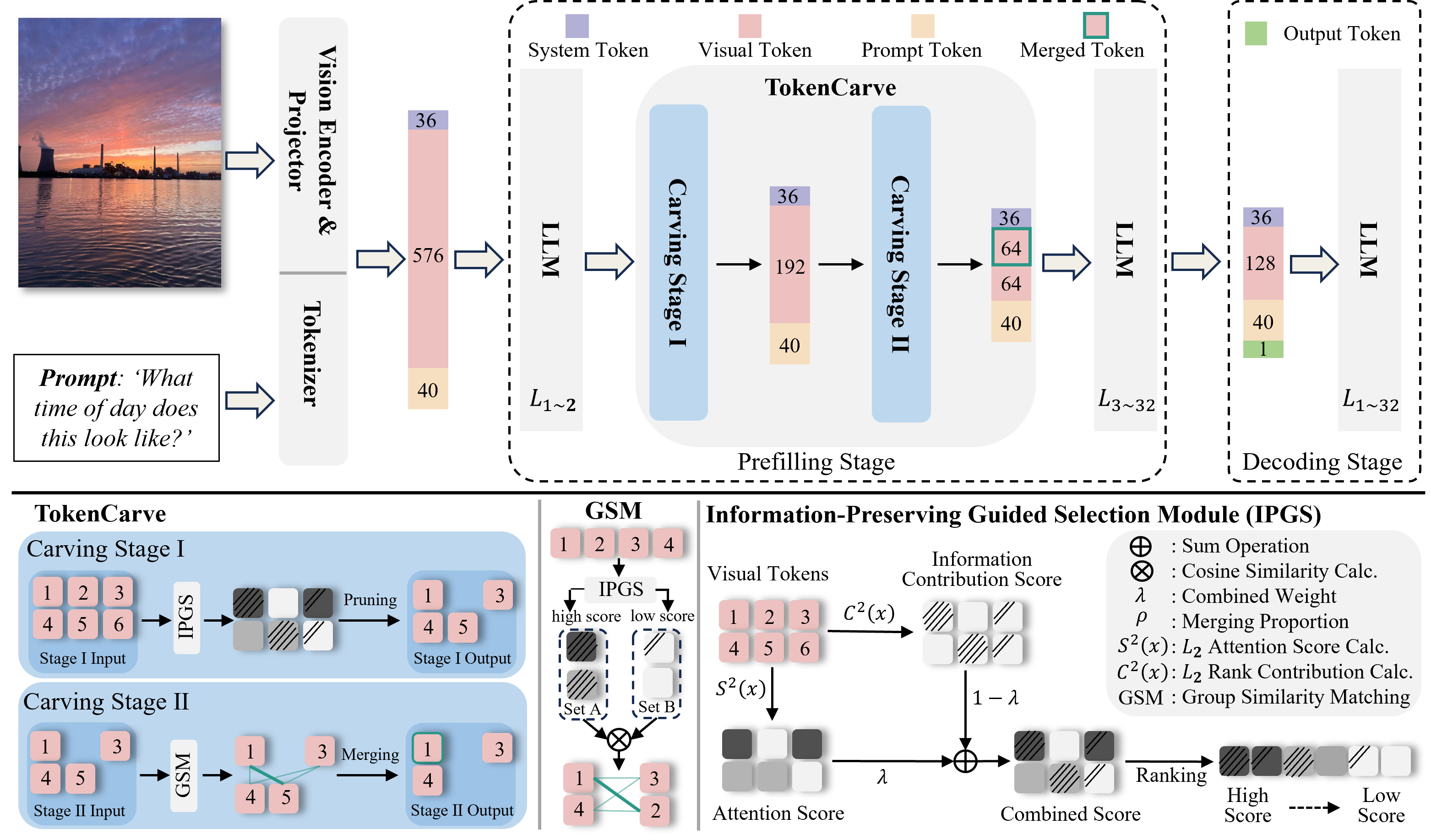
技术框架:TokenCarve是一个两阶段的token压缩框架。第一阶段是信息保持引导选择(IPGS)的token修剪,旨在移除低信息量的tokens。第二阶段是基于IPGS的token合并,进一步减少tokens数量,同时最小化信息损失。整个框架是免训练的,可以即插即用,方便集成到现有的多模态大语言模型中。
关键创新:TokenCarve的关键创新在于其信息保持的视角。与以往关注token重要性或显著性的方法不同,TokenCarve直接关注tokens对模型输出信息量的贡献,并以此为依据进行压缩。这种方法能够更有效地保留关键信息,从而在极端压缩条件下维持模型性能。
关键设计:IPGS策略是TokenCarve的核心。具体实现细节未知,但可以推测其可能涉及计算每个token对模型输出的影响,例如通过梯度或注意力权重等方式。在token修剪阶段,选择信息量最低的tokens进行移除;在token合并阶段,将信息量相近的tokens进行合并,并可能采用加权平均或其他方式来融合tokens的特征。
🖼️ 关键图片

📊 实验亮点
TokenCarve在11个数据集和2个模型变体上进行了广泛的实验验证。实验结果表明,TokenCarve可以将视觉tokens的数量减少到原始数量的22.2%,实现1.23倍的推理加速,KV缓存存储减少64%,而准确率仅下降1.54%。这些结果表明TokenCarve在效率和精度之间取得了良好的平衡。
🎯 应用场景
TokenCarve可广泛应用于各种多模态大语言模型,尤其是在资源受限的场景下,如移动设备、边缘计算等。通过降低计算成本和存储需求,TokenCarve能够使这些模型在更广泛的平台上部署和应用,例如智能助手、图像/视频理解、机器人导航等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) are becoming increasingly popular, while the high computational cost associated with multimodal data input, particularly from visual tokens, poses a significant challenge. Existing training-based token compression methods improve inference efficiency but require costly retraining, while training-free methods struggle to maintain performance when aggressively reducing token counts. In this study, we reveal that the performance degradation of MLLM closely correlates with the accelerated loss of information in the attention output matrix. This insight introduces a novel information-preserving perspective, making it possible to maintain performance even under extreme token compression. Based on this finding, we propose TokenCarve, a training-free, plug-and-play, two-stage token compression framework. The first stage employs an Information-Preservation-Guided Selection (IPGS) strategy to prune low-information tokens, while the second stage further leverages IPGS to guide token merging, minimizing information loss. Extensive experiments on 11 datasets and 2 model variants demonstrate the effectiveness of TokenCarve. It can even reduce the number of visual tokens to 22.2% of the original count, achieving a 1.23x speedup in inference, a 64% reduction in KV cache storage, and only a 1.54% drop in accuracy. Our code is available at https://github.com/ShawnTan86/TokenCarve.