VicaSplat: A Single Run is All You Need for 3D Gaussian Splatting and Camera Estimation from Unposed Video Frames
作者: Zhiqi Li, Chengrui Dong, Yiming Chen, Zhangchi Huang, Peidong Liu
分类: cs.CV
发布日期: 2025-03-13
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VicaSplat:单次运行即可从无位姿视频帧中进行3D高斯溅射重建和相机估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 相机姿态估计 Transformer 无位姿视频 三维重建
📋 核心要点
- 现有方法在无位姿视频帧中进行3D高斯重建和相机姿态估计方面存在不足,这是一个现实世界3D应用中的关键挑战。
- VicaSplat提出了一种基于Transformer的网络架构,通过可学习的相机token聚合多视角信息,并注入视角相关的特征。
- 实验表明,VicaSplat在多视图输入上优于基线方法,并在ScanNet上实现了卓越的跨数据集泛化能力,无需微调。
📝 摘要(中文)
VicaSplat是一种新颖的框架,用于从一系列无位姿视频帧中联合进行3D高斯重建和相机姿态估计。这是现实世界3D应用中一个关键但未被充分探索的任务。该方法的核心在于一种基于Transformer的新型网络架构。具体来说,该模型首先使用图像编码器将每个图像映射到视觉token列表。所有视觉token与插入的可学习相机token连接。然后,获得的token在定制的Transformer解码器中充分地相互通信。相机token因果地聚合来自不同视角的视觉token的特征,并进一步逐帧调制它们以注入视角相关的特征。然后,可以通过不同的预测头估计3D高斯溅射和相机姿态参数。实验表明,VicaSplat超越了多视图输入的基线方法,并且实现了与先前双视图方法相当的性能。值得注意的是,VicaSplat还在ScanNet基准测试中展示了卓越的跨数据集泛化能力,无需任何微调即可实现卓越的性能。
🔬 方法详解
问题定义:论文旨在解决从无位姿的视频帧序列中同时进行3D高斯溅射重建和相机姿态估计的问题。现有的方法可能需要预先知道相机位姿,或者在多视图一致性方面存在不足,导致重建质量不高。
核心思路:论文的核心思路是利用Transformer架构来学习不同视角图像之间的关系,并使用可学习的相机token来表示和优化相机姿态。通过让相机token与视觉token交互,模型可以学习到视角相关的特征,从而实现更准确的3D重建和相机姿态估计。
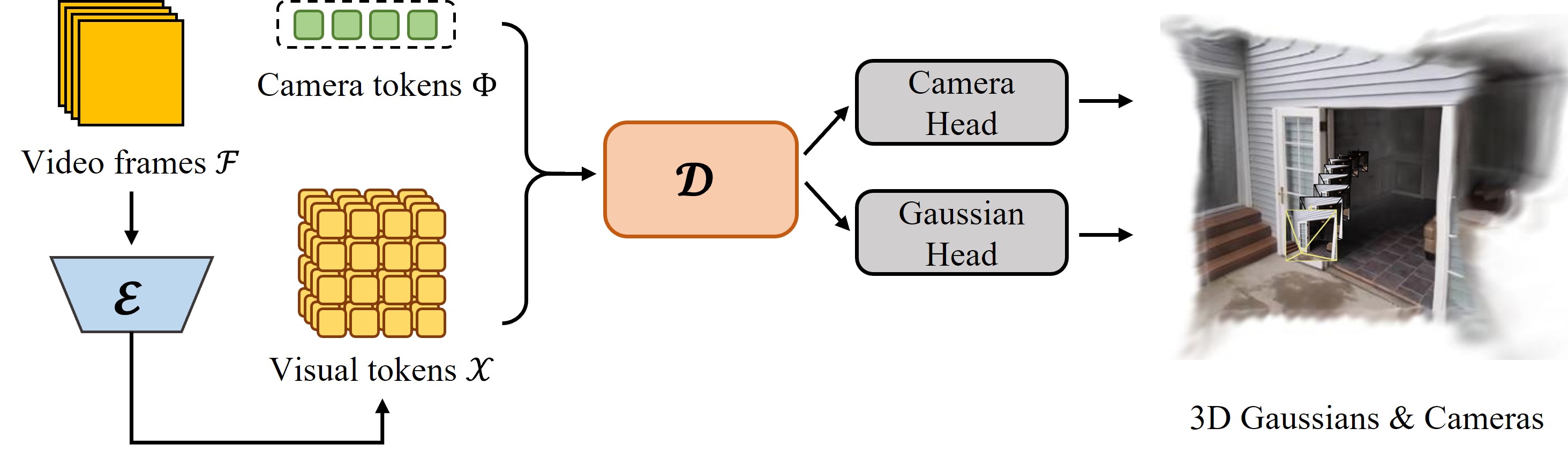
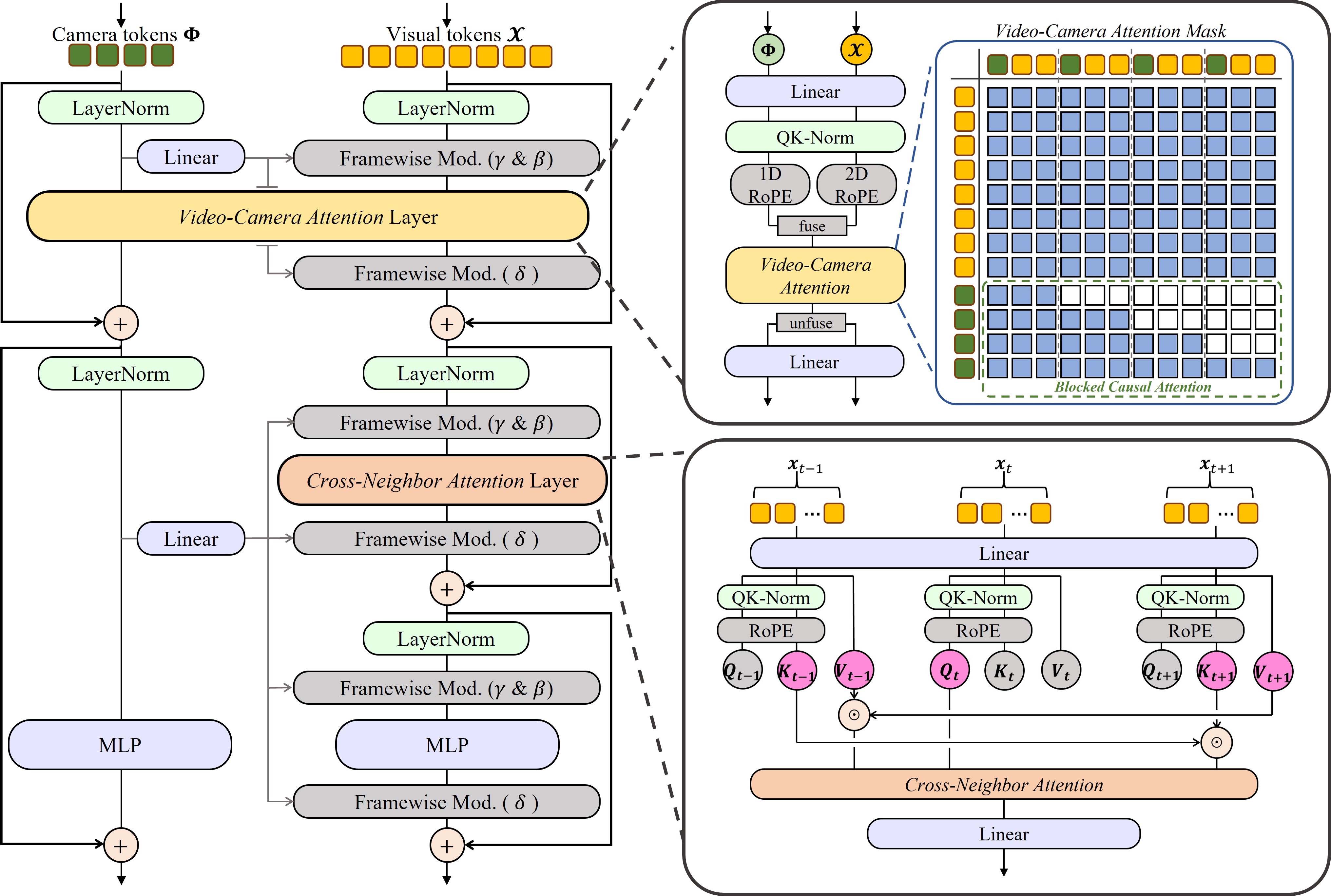
技术框架:VicaSplat的整体架构包括以下几个主要模块:1) 图像编码器:将每个输入图像编码成视觉token序列。2) 相机Token:插入可学习的相机token,用于表示和优化相机姿态。3) Transformer解码器:视觉token和相机token在此模块中进行交互,学习多视角信息。4) 预测头:分别预测3D高斯溅射参数和相机姿态参数。
关键创新:该方法最重要的创新点在于使用Transformer架构来处理多视角图像,并引入可学习的相机token。这种设计允许模型在没有预先相机位姿信息的情况下,学习到视角相关的特征,从而实现更准确的3D重建和相机姿态估计。与现有方法相比,VicaSplat能够直接从无位姿视频帧中进行重建,无需额外的位姿估计步骤。
关键设计:Transformer解码器是关键组件,其自注意力机制允许视觉token和相机token之间进行充分的交互。相机token的设计允许模型学习到视角相关的特征,并通过逐帧调制来注入视角依赖性。损失函数可能包括重建损失和相机姿态损失,用于优化3D高斯溅射参数和相机姿态参数。具体的网络结构和参数设置在论文中应该有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
VicaSplat在多视图输入上超越了基线方法,并在ScanNet数据集上实现了卓越的跨数据集泛化能力,无需任何微调。这表明VicaSplat具有很强的鲁棒性和泛化能力,可以应用于不同的场景和数据集。与现有的双视图方法相比,VicaSplat实现了相当的性能,但只需要单次运行,效率更高。
🎯 应用场景
VicaSplat在机器人导航、增强现实、虚拟现实、三维地图构建等领域具有广泛的应用前景。它可以用于从移动设备拍摄的视频中重建三维场景,无需预先标定相机或使用额外的传感器。该技术可以帮助机器人更好地理解周围环境,并为用户提供更沉浸式的AR/VR体验。
📄 摘要(原文)
We present VicaSplat, a novel framework for joint 3D Gaussians reconstruction and camera pose estimation from a sequence of unposed video frames, which is a critical yet underexplored task in real-world 3D applications. The core of our method lies in a novel transformer-based network architecture. In particular, our model starts with an image encoder that maps each image to a list of visual tokens. All visual tokens are concatenated with additional inserted learnable camera tokens. The obtained tokens then fully communicate with each other within a tailored transformer decoder. The camera tokens causally aggregate features from visual tokens of different views, and further modulate them frame-wisely to inject view-dependent features. 3D Gaussian splats and camera pose parameters can then be estimated via different prediction heads. Experiments show that VicaSplat surpasses baseline methods for multi-view inputs, and achieves comparable performance to prior two-view approaches. Remarkably, VicaSplat also demonstrates exceptional cross-dataset generalization capability on the ScanNet benchmark, achieving superior performance without any fine-tuning. Project page: https://lizhiqi49.github.io/VicaSplat.