Proxy-Tuning: Tailoring Multimodal Autoregressive Models for Subject-Driven Image Generation
作者: Yi Wu, Shengju Qian, Lingting Zhu, Lei Liu, Wandi Qiao, Ziqiang Li, Lequan Yu, Bin Li
分类: cs.CV, cs.MM
发布日期: 2025-03-13 (更新: 2025-11-29)
💡 一句话要点
提出Proxy-Tuning,利用扩散模型提升自回归模型在主体驱动图像生成中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主体驱动图像生成 自回归模型 扩散模型 弱到强学习 多模态学习
📋 核心要点
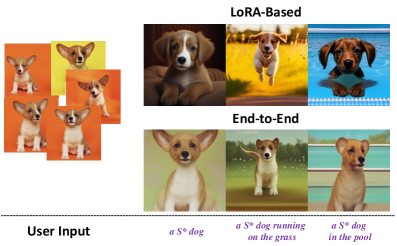
- 现有的多模态自回归模型在主体驱动图像生成方面存在不足,性能不如扩散模型。
- Proxy-Tuning方法利用扩散模型作为代理,微调自回归模型,提升其在主体驱动图像生成方面的能力。
- 实验结果表明,微调后的自回归模型在主体保真度和提示词遵循度方面均优于扩散模型。
📝 摘要(中文)
本文提出Proxy-Tuning方法,旨在提升多模态自回归(AR)模型在主体驱动图像生成方面的能力。研究发现,尽管AR模型在通用文本到图像(T2I)生成任务中表现出色,但在主体驱动图像生成方面,其初始性能不如扩散模型。Proxy-Tuning利用扩散模型来增强AR模型在特定主体图像生成方面的能力。该方法揭示了一种显著的弱到强现象:微调后的AR模型在主体保真度和提示词遵循度方面均优于其扩散模型监督者。论文分析了这种性能转变,并确定了AR模型擅长的场景,尤其是在多主体组合和上下文理解方面。这项工作不仅展示了AR图像生成在主体驱动方面的卓越成果,还揭示了图像生成领域中弱到强泛化的潜力,有助于更深入地理解不同架构的优势和局限性。
🔬 方法详解
问题定义:论文旨在解决多模态自回归模型在主体驱动图像生成任务中表现不佳的问题。现有的自回归模型虽然在通用文本到图像生成任务中表现良好,但在处理特定主体的图像生成时,其性能明显低于扩散模型,无法很好地捕捉和还原主体的细节和特征。
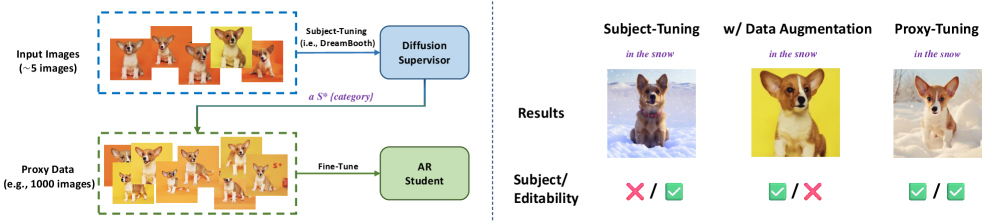
核心思路:论文的核心思路是利用扩散模型作为“代理”或“监督者”,通过微调的方式来提升自回归模型在主体驱动图像生成方面的能力。这种“弱到强”的训练范式,旨在让自回归模型学习扩散模型在主体建模方面的优势,从而提高其生成特定主体图像的质量。
技术框架:Proxy-Tuning的整体框架包含两个主要阶段:首先,使用扩散模型生成特定主体的图像;然后,使用这些图像和对应的文本提示作为训练数据,对自回归模型进行微调。微调过程中,自回归模型学习如何根据文本提示生成与扩散模型生成的图像相似的图像,从而提升其在主体建模方面的能力。
关键创新:该方法最重要的创新点在于其“弱到强”的训练范式,即利用性能更强的扩散模型来指导性能较弱的自回归模型进行学习。这种方法不仅提升了自回归模型在主体驱动图像生成方面的性能,还揭示了图像生成领域中弱到强泛化的潜力。
关键设计:论文中可能涉及的关键设计包括:用于微调自回归模型的损失函数,例如,可以使用像素级别的损失函数或感知损失函数来衡量生成图像与扩散模型生成图像之间的相似度;用于生成训练数据的扩散模型的选择,不同的扩散模型可能具有不同的主体建模能力,选择合适的扩散模型对于Proxy-Tuning的性能至关重要;自回归模型的架构选择和参数设置,不同的自回归模型架构可能具有不同的学习能力和生成效果。
🖼️ 关键图片
📊 实验亮点
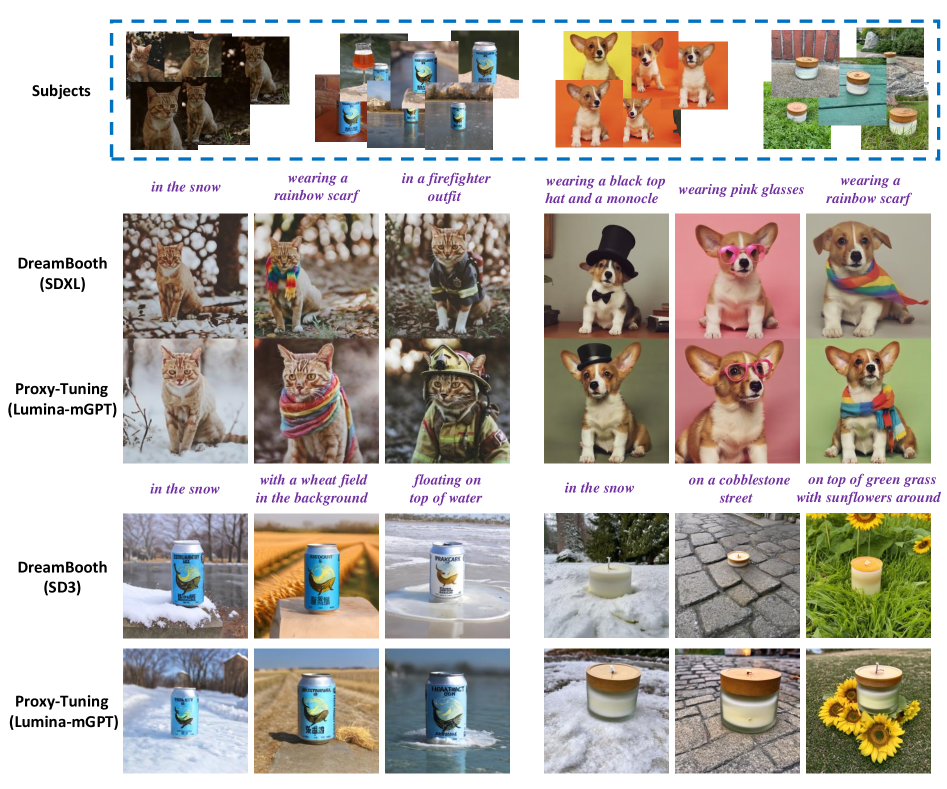
实验结果表明,通过Proxy-Tuning微调后的自回归模型在主体保真度和提示词遵循度方面均优于其扩散模型监督者。尤其是在多主体组合和上下文理解方面,自回归模型表现出更强的优势。具体的性能提升数据(例如FID分数、CLIP分数等)未知,但整体结果表明Proxy-Tuning能够有效提升自回归模型在主体驱动图像生成方面的能力。
🎯 应用场景
该研究成果可应用于定制化图像生成、个性化内容创作等领域。例如,用户可以提供一张或几张包含特定主体的图像,然后通过文本描述,生成包含该主体的各种场景图像。这项技术在游戏开发、广告设计、虚拟现实等领域具有广泛的应用前景,能够显著提升内容创作的效率和质量。
📄 摘要(原文)
Multimodal autoregressive (AR) models, based on next-token prediction and transformer architecture, have demonstrated remarkable capabilities in various multimodal tasks including text-to-image (T2I) generation. Despite their strong performance in general T2I tasks, our research reveals that these models initially struggle with subject-driven image generation compared to dominant diffusion models. To address this limitation, we introduce Proxy-Tuning, leveraging diffusion models to enhance AR models' capabilities in subject-specific image generation. Our method reveals a striking weak-to-strong phenomenon: fine-tuned AR models consistently outperform their diffusion model supervisors in both subject fidelity and prompt adherence. We analyze this performance shift and identify scenarios where AR models excel, particularly in multi-subject compositions and contextual understanding. This work not only demonstrates impressive results in subject-driven AR image generation, but also unveils the potential of weak-to-strong generalization in the image generation domain, contributing to a deeper understanding of different architectures' strengths and limitations.