CombatVLA: An Efficient Vision-Language-Action Model for Combat Tasks in 3D Action Role-Playing Games
作者: Peng Chen, Pi Bu, Yingyao Wang, Xinyi Wang, Ziming Wang, Jie Guo, Yingxiu Zhao, Qi Zhu, Jun Song, Siran Yang, Jiamang Wang, Bo Zheng
分类: cs.CV, cs.AI
发布日期: 2025-03-12 (更新: 2026-01-09)
备注: Accepted by ICCV 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
CombatVLA:用于3D动作角色扮演游戏中战斗任务的高效视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 3D动作角色扮演游戏 具身智能 行动-思考序列 实时决策
📋 核心要点
- 现有VLA模型在复杂3D环境中实时决策能力不足,难以满足战斗任务对响应速度、感知精度和战术推理的要求。
- CombatVLA通过行动-思考(AoT)序列训练,并采用截断AoT策略,实现了高效的推理和动作执行。
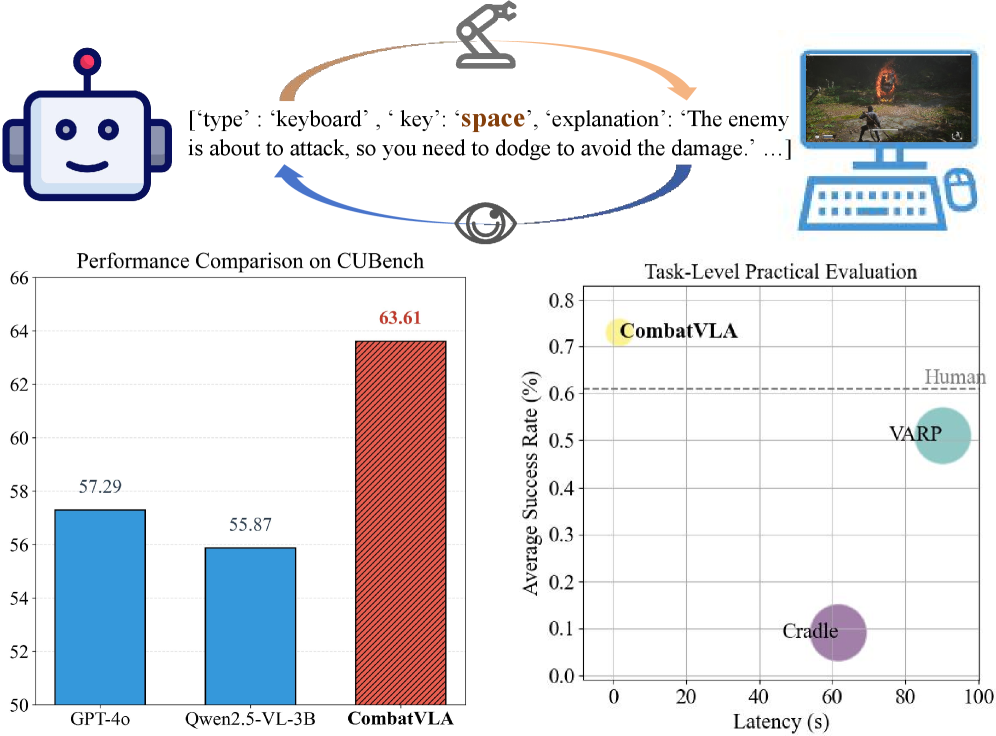
- 实验表明,CombatVLA在战斗理解基准测试中超越现有模型,游戏战斗速度提升50倍,任务成功率超过人类玩家。
📝 摘要(中文)
视觉-语言-动作模型(VLA)的最新进展扩展了具身智能的能力。然而,在复杂的3D环境中进行实时决策仍然面临重大挑战,这需要秒级响应、高分辨率感知以及动态条件下的战术推理。为了推进该领域,我们推出了CombatVLA,这是一种针对3D动作角色扮演游戏(ARPG)中战斗任务进行优化的高效VLA模型。具体来说,我们的CombatVLA是一个30亿参数的模型,在动作追踪器收集的视频-动作对上进行训练,数据格式为行动-思考(AoT)序列。此后,CombatVLA通过我们截断的AoT策略无缝集成到动作执行框架中,从而实现高效推理。实验结果表明,CombatVLA不仅在战斗理解基准测试中优于所有现有模型,而且在游戏战斗中实现了50倍的加速。此外,它比人类玩家具有更高的任务成功率。我们将开源所有资源,包括动作追踪器、数据集、基准、模型权重、训练代码和框架的实现,网址为https://combatvla.github.io/。
🔬 方法详解
问题定义:论文旨在解决3D动作角色扮演游戏中,现有视觉-语言-动作模型(VLA)在复杂战斗场景下实时决策能力不足的问题。现有方法难以兼顾高分辨率感知、快速响应和战术推理,导致游戏智能体在战斗中表现不佳。
核心思路:论文的核心思路是利用行动-思考(AoT)序列来训练VLA模型,使模型能够学习到更有效的战术决策。同时,通过截断AoT策略,减少推理计算量,提高响应速度。这种设计旨在模拟人类玩家在战斗中的思考和行动过程,从而提升智能体的战斗能力。
技术框架:CombatVLA的技术框架主要包括三个部分:1) 数据收集:使用动作追踪器收集游戏中的视频-动作对,并将其格式化为AoT序列。2) 模型训练:使用收集到的AoT数据训练一个30亿参数的VLA模型。3) 动作执行:将训练好的CombatVLA模型集成到动作执行框架中,通过截断AoT策略进行高效推理,并控制游戏智能体执行动作。
关键创新:CombatVLA的关键创新在于:1) 提出了基于行动-思考(AoT)序列的训练方法,使模型能够学习到更有效的战术决策。2) 采用了截断AoT策略,在保证性能的同时,显著降低了推理计算量,提高了响应速度。3) 构建了一个完整的战斗理解基准测试,用于评估VLA模型在3D动作角色扮演游戏中的战斗能力。
关键设计:CombatVLA的关键设计包括:1) 使用30亿参数的模型,以保证模型的表达能力。2) 采用行动追踪器收集高质量的视频-动作对数据。3) 设计截断AoT策略,平衡推理速度和性能。4) 损失函数的设计未知,训练代码细节未知。
🖼️ 关键图片


📊 实验亮点
CombatVLA在战斗理解基准测试中超越了所有现有模型,并在游戏战斗中实现了50倍的加速。更重要的是,CombatVLA的任务成功率甚至高于人类玩家,这表明该模型在3D动作角色扮演游戏中的战斗能力已经达到了一个新的高度。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
CombatVLA模型可应用于3D动作角色扮演游戏中的智能体控制,提升游戏AI的战斗能力和玩家体验。此外,该模型的设计思路和技术框架也可推广到其他需要实时决策的复杂环境中,如自动驾驶、机器人控制等领域,具有广泛的应用前景和实际价值。
📄 摘要(原文)
Recent advances in Vision-Language-Action models (VLAs) have expanded the capabilities of embodied intelligence. However, significant challenges remain in real-time decision-making in complex 3D environments, which demand second-level responses, high-resolution perception, and tactical reasoning under dynamic conditions. To advance the field, we introduce CombatVLA, an efficient VLA model optimized for combat tasks in 3D action role-playing games(ARPGs). Specifically, our CombatVLA is a 3B model trained on video-action pairs collected by an action tracker, where the data is formatted as action-of-thought (AoT) sequences. Thereafter, CombatVLA seamlessly integrates into an action execution framework, allowing efficient inference through our truncated AoT strategy. Experimental results demonstrate that CombatVLA not only outperforms all existing models on the combat understanding benchmark but also achieves a 50-fold acceleration in game combat. Moreover, it has a higher task success rate than human players. We will open-source all resources, including the action tracker, dataset, benchmark, model weights, training code, and the implementation of the framework at https://combatvla.github.io/.