Project-Probe-Aggregate: Efficient Fine-Tuning for Group Robustness
作者: Beier Zhu, Jiequan Cui, Hanwang Zhang, Chi Zhang
分类: cs.CV
发布日期: 2025-03-12 (更新: 2025-08-26)
备注: Accepted by CVPR 2025
💡 一句话要点
提出Project-Probe-Aggregate以解决图像文本模型的偏差问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像文本模型 去偏差 少数样本识别 鲁棒训练 参数高效微调
📋 核心要点
- 现有的图像-文本基础模型在处理输入与标签之间的虚假相关性时表现不佳,导致模型的鲁棒性不足。
- 论文提出的Project-Probe-Aggregate方法通过三步流程实现了参数高效的微调,避免了对组注释的依赖。
- 实验结果显示,PPA在最差组准确率上平均超越了现有最优方法,同时所需可调参数极少,提升了模型的实用性。
📝 摘要(中文)
尽管图像-文本基础模型在多种下游任务中取得了成功,但在输入与标签之间存在虚假相关性时仍面临挑战。为了解决这个问题,我们提出了一种简单的三步法——Project-Probe-Aggregate(PPA),该方法能够在不依赖于组注释的情况下实现基础模型的参数高效微调。基于失败驱动的去偏差方案,我们的方法改进了两个关键组成部分:少数样本识别和鲁棒训练算法。具体而言,我们首先通过将图像特征投影到文本编码器的类代理的零空间上来训练偏置分类器。接下来,我们使用偏置分类器推断组标签,并通过先验修正探测组目标。最后,我们聚合每个类别的组权重以生成去偏差分类器。我们的理论分析表明,PPA增强了少数群体的识别能力,并在最小化平衡组误差方面是贝叶斯最优的,有效减轻了虚假相关性。大量实验结果证实了PPA的有效性:在不需要训练组标签的情况下,其最差组准确率平均优于现有最优方法,且可调参数少于0.01%。
🔬 方法详解
问题定义:论文要解决的问题是图像-文本基础模型在存在虚假相关性时的鲁棒性不足,现有方法往往依赖于组注释,限制了其应用场景。
核心思路:PPA方法通过三步流程实现高效微调,首先识别少数样本,然后推断组标签,最后聚合权重,旨在提高模型对少数群体的识别能力。
技术框架:整体架构包括三个主要阶段:1) 训练偏置分类器,通过将图像特征投影到类代理的零空间;2) 使用偏置分类器推断组标签并探测目标;3) 聚合每个类别的组权重以生成去偏差分类器。
关键创新:PPA的关键创新在于其不依赖于组注释的去偏差策略,通过改进少数样本识别和鲁棒训练算法,显著提升了模型的性能。
关键设计:在参数设置上,PPA要求可调参数少于0.01%,并采用特定的损失函数和网络结构,以确保在微调过程中保持高效性和准确性。
🖼️ 关键图片
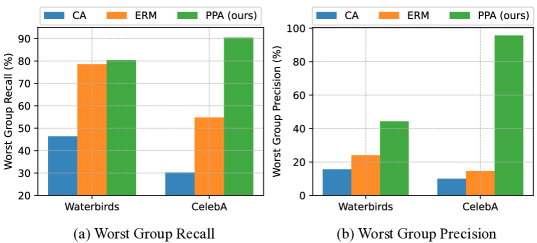

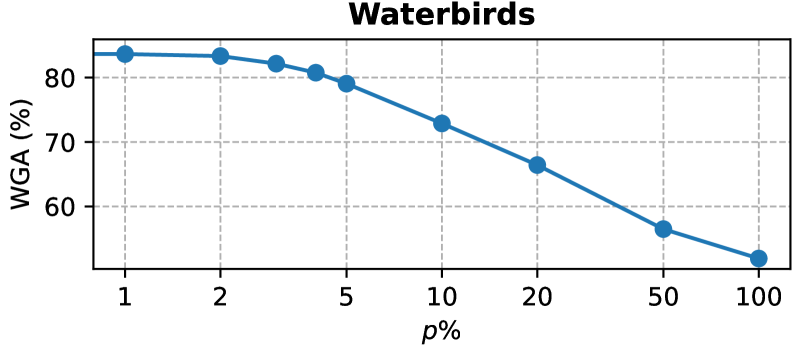
📊 实验亮点
实验结果表明,PPA方法在最差组准确率上平均超越了现有最优方法,提升幅度显著,同时所需的可调参数少于0.01%,显示出其在参数效率上的优势。
🎯 应用场景
该研究的潜在应用领域包括图像识别、文本生成和多模态学习等,尤其在需要处理不平衡数据集的任务中具有重要价值。未来,PPA方法可能推动更广泛的基础模型在实际应用中的鲁棒性提升,促进公平性和准确性的实现。
📄 摘要(原文)
While image-text foundation models have succeeded across diverse downstream tasks, they still face challenges in the presence of spurious correlations between the input and label. To address this issue, we propose a simple three-step approach,Project-Probe-Aggregate (PPA), that enables parameter-efficient fine-tuning for foundation models without relying on group annotations. Building upon the failure-based debiasing scheme, our method, PPA, improves its two key components: minority samples identification and the robust training algorithm. Specifically, we first train biased classifiers by projecting image features onto the nullspace of class proxies from text encoders. Next, we infer group labels using the biased classifier and probe group targets with prior correction. Finally, we aggregate group weights of each class to produce the debiased classifier. Our theoretical analysis shows that our PPA enhances minority group identification and is Bayes optimal for minimizing the balanced group error, mitigating spurious correlations. Extensive experimental results confirm the effectiveness of our PPA: it outperforms the state-of-the-art by an average worst-group accuracy while requiring less than 0.01% tunable parameters without training group labels.